you can quickly try out using the interpretation object helpers.
5 Likes
Search for ‘gradcam’ in the book.
6 Likes
Also, there is an interesting library for this. Should be as simple as:
cam = GradCAM(model=model, target_layers=target_layers)
(In case if you would like to use it with a “plain” torch model.)
6 Likes
Nice model and very well done write-up.
2 Likes
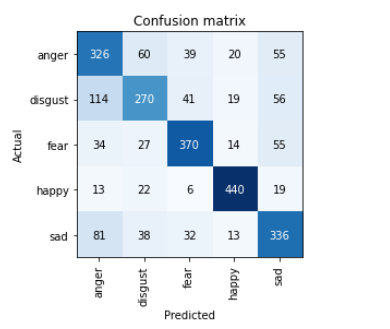
I built Emotion Escape a choose-your-own adventure where you choose your path by uploading images of facial expressions.

I trained a model to detect emotions in a Kaggle notebook. I found getting good images of emotions through DDG search tricky, so I used an existing dataset, a sample of AffectNet with 500 images per class. This data is also pretty noisy, but resnet34 got an error rate around 30% with 5 classes.
Then I deployed it as a Gradio app on huggingface spaces.

Inspired by the Javascript Interface thread I made a little Javascript adventure game that uses the emotion classifier to move between rooms. I pushed it to github and deployed it on github pages.
The game could use a lot of polish, especially around making it easier to capture images from a camera and resize the images before uploading. Currently it requires having some images with facial expressions downloaded and uploading them from a file browser; but it works reasonably well.
10 Likes
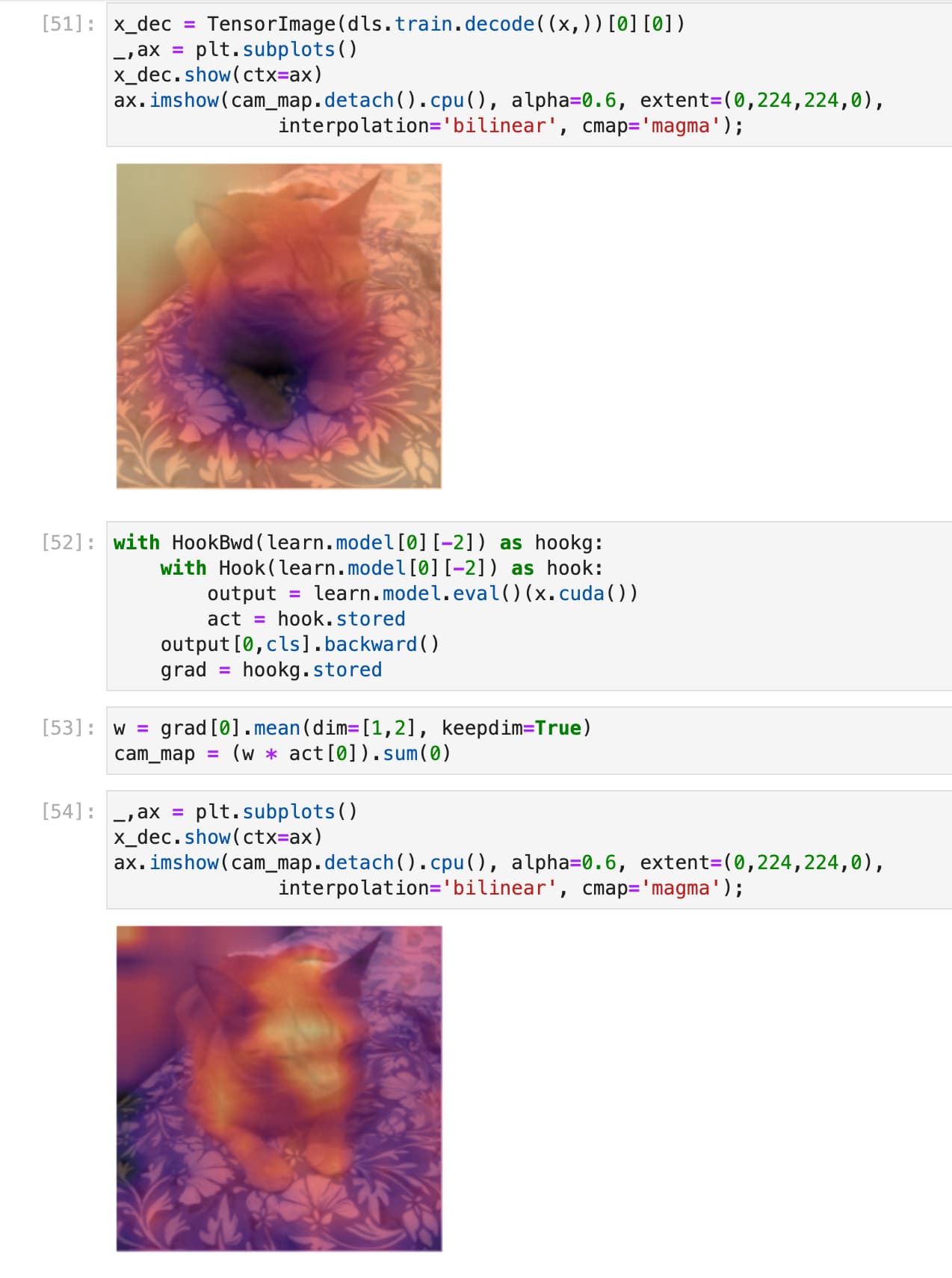
Well, that was a journey! I have relatively little idea of what all this means (chapter 18!), but at least it does seem that the model is activating (if that’s the right word / phrasing) on Mr Blupus and not the pillow or the background.
Thanks for the nudge to try that out. I would never have dared, otherwise, and it gives a bit of extra motivation to do the work to get to the point where I understand all the layers of what’s going on here.
14 Likes
Created a huggingface spaces for classifying music according to genre. I had written a blog post on training model previously.
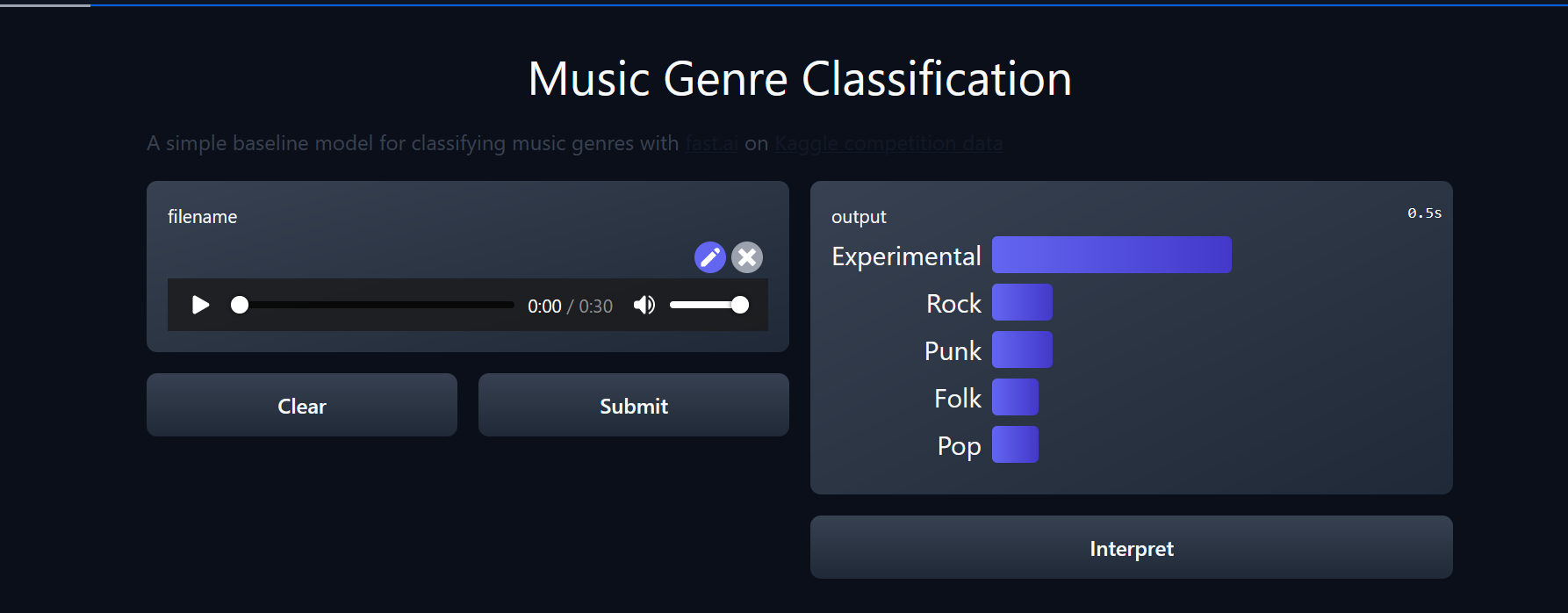
You can check out the model here and thanks for @suvash for explaining how to make hugging-face spaces work and explaining his code during delft-fastai meetup.
18 Likes
Pretty neat that you have the audio → image(spectrogram) right in the inference code, and I see that you’re also using the huggingface+fastai integration functions. 
3 Likes
Did you include this in your notebook? If so … please do 
Kind of amazing is that this is considered an advanced technique and waits for folks at the end of the book … and yet you figured out how to implement it after the first session of the course. Top > down learning works!
6 Likes
Hi all,
I have created a classifier to detect if your house has been damaged by storms and have published a simple Gradio app on Huggingface spaces.
Thanks @suvash for the inspiration to explore Gradio and Huggingface Spaces.
Thanks @strickvl for hosting the delft-fastai study group, and good work using class activation maps to check how your model is working, I will definitely have to give this a go as well!
2 Likes
I took an idea I had when tinkering with a smart home around “private” computer vision - can I use images with detail stripped out and still build a model that can drive certain smart home tasks (ie. lights on/off when someone enters/exits a room). With limited time and using pretty much the standard set of hyperparameters that fastai suggests, I was able to get 85-90% accuracy in a simple multi-class classification using two different types of proxy camera filters.
The background and next steps for anyone interested can be found in this notebook, but the lesson here is that with models that are clearly not optimized for this task can still get good results in a couple hours of time.
This fastai/DL stuff is like magic - but unlike magicians, the fastai team actually reveal their secrets
BTW - I tried to host my notebook on Kaggle but I was encountering an error. Will repost there if I can resolve
4 Likes
Yeah, I kind of figured out the pipeline looking at notebooks made by @dhoa and played around with gradio audio inputs. It worked pretty smooth with the integration.
Yet one thing I noticed was two of the three gradio demos showing audio feature were having some issues.
Hi everyone, I have enjoyed following lesson 1 and learning from the python code.
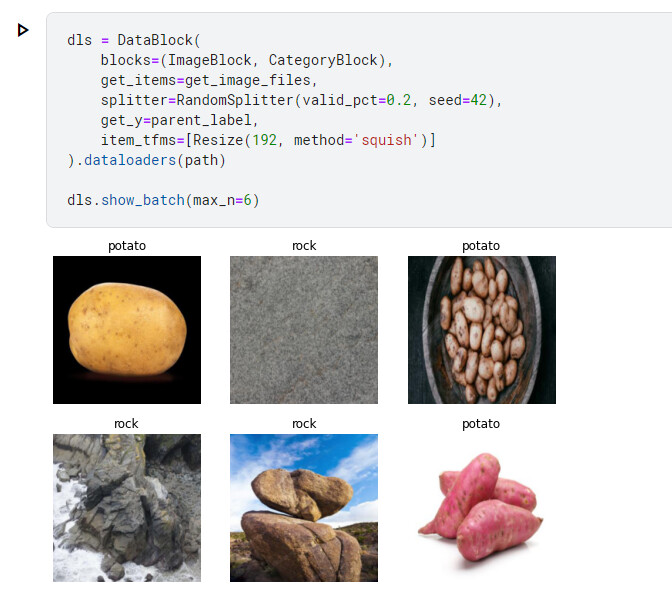
I made some quick modifications to the “Is it a bird?” kaggle notebook.
I was inspired by this clip by Stephen Colbert to answer the question:

Uploading: image.png…
I also liked this one because some potato images look similar to rock from the image search.
There were some issues with this example becuase there were images of the “The Rock”.
Looking forward to meeting up with the other members of the Australia Study Group before today’s talk.
6 Likes
This is an intriguing concept. I think from a security perspective, I’d be paranoid enough to not let anything hit the camera sensor that I don’t want it to see, so I’d probably go for a “physical filter”. I’ve worked in offices where they used motion detectors above cubicles to determine presence (to turn lights off when people leave) but the most annoying part of that was that these sensors turn lights off if your’e working late and their resolution wasn’t that great. So, if you’re working late just sitting at your desk, they can’t detect presence. I think a vision based system like you propose can check itself against a base case and keep the lights on even if no motion is detected. I think not too much resolution is needed to determin if there is motion within the monitored space.
Something really cool would be if the system can “learn” the base case of an empty room and then detect presence of objects within it. Especially if those objects tend to move once in a while. or maybe a combination of multiple cheap sensors that feed into the network? like a very low resolution camera, a microphone and an ultrasound motion detector all in one case?
The more I think about it, the more complicated this problem gets in my mind 
Definitely an interesting and challenging problem for sure!
2 Likes
I also tried to re-use “Is it a bird?” code with a different set of images to see if the classifier can distinguish between war memes and news photos. It performed very well but it was interesting to see that a captioned news photo was classified as a meme! Looking forward to playing with this idea a little more, potentially adding NLP element to it.
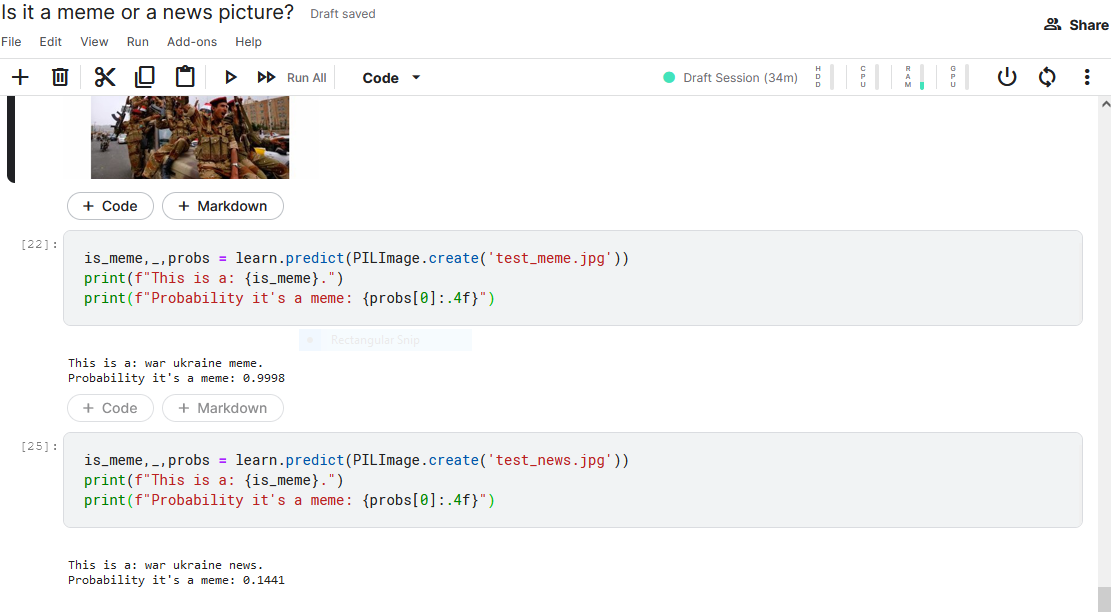
3 Likes
Might be even more interesting to see if you can find out why using the techniques described here: Share your work here ✅ - #77
1 Like
Art Mood

This is a variation of my last model in which I trained an image classifier on pictures of the four seasons. In Art Mood I wanted to determine how well the model could predict the mood the paintings evoked in me. (I limited these moods to the four seasons.) The examples in the Art Mood app are a combination of both real and abstract art. Subjectively, I thought the model did very well. My wife is an artist and she too found the predictions to largely match her seasonal moods—and her perspective should be more highly regarded than my own. . .
This was a proof of concept. In order to make this more rigorous, I would need to create a labeled training set of paintings in order to compare how well the model did a priori.
Let me know if the model aligns with your Art Mood
9 Likes
I built a classifier to match an image with the best-fitting art movement from the following:
- Expressionism
- Impressionism
- Hudson River School
- Pre-Raphaelite Brotherhood
- Ukiyo-e (Japanese woodblock prints)
I gathered about 200 photos / movement, 150 for Expressionism from Google Arts & Culture, and 200 for the rest from DuckDuckGo.
Using a resnet34 and presizing the images got it down to below a 5% error rate.
Testing my classifier on images outside of the genres provided seems to align with my intuitions pretty well - Keith Haring is categorized as Expressionism
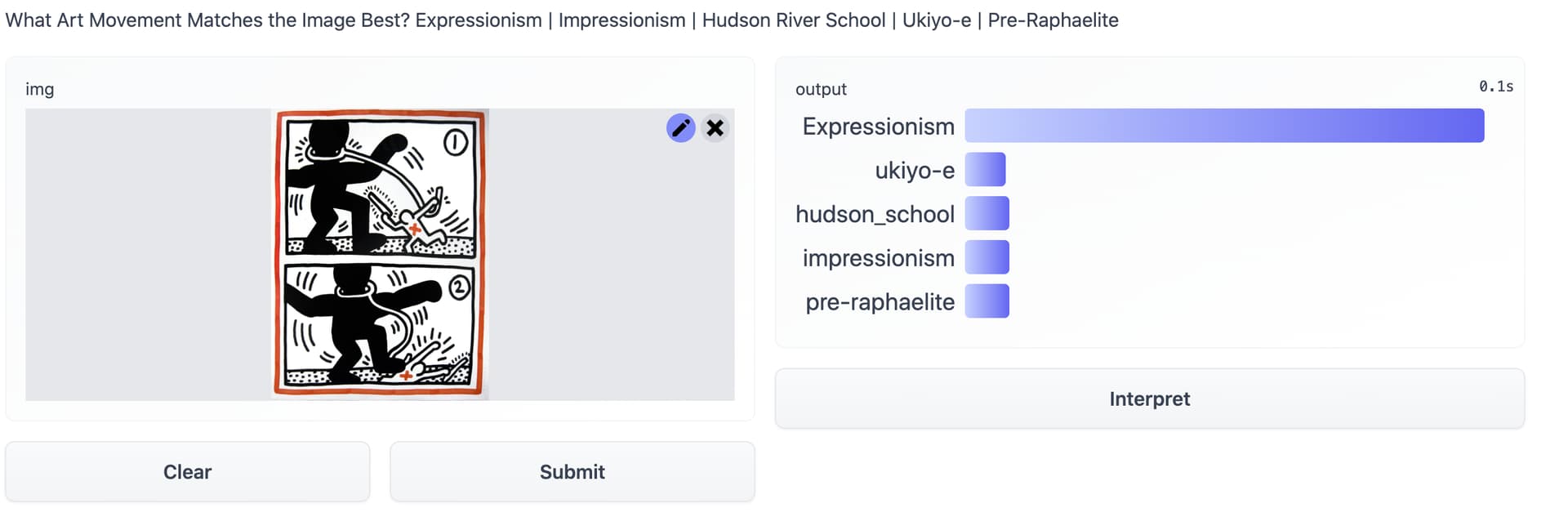
While for Mickey Mouse Ukiyo-e is the favored category
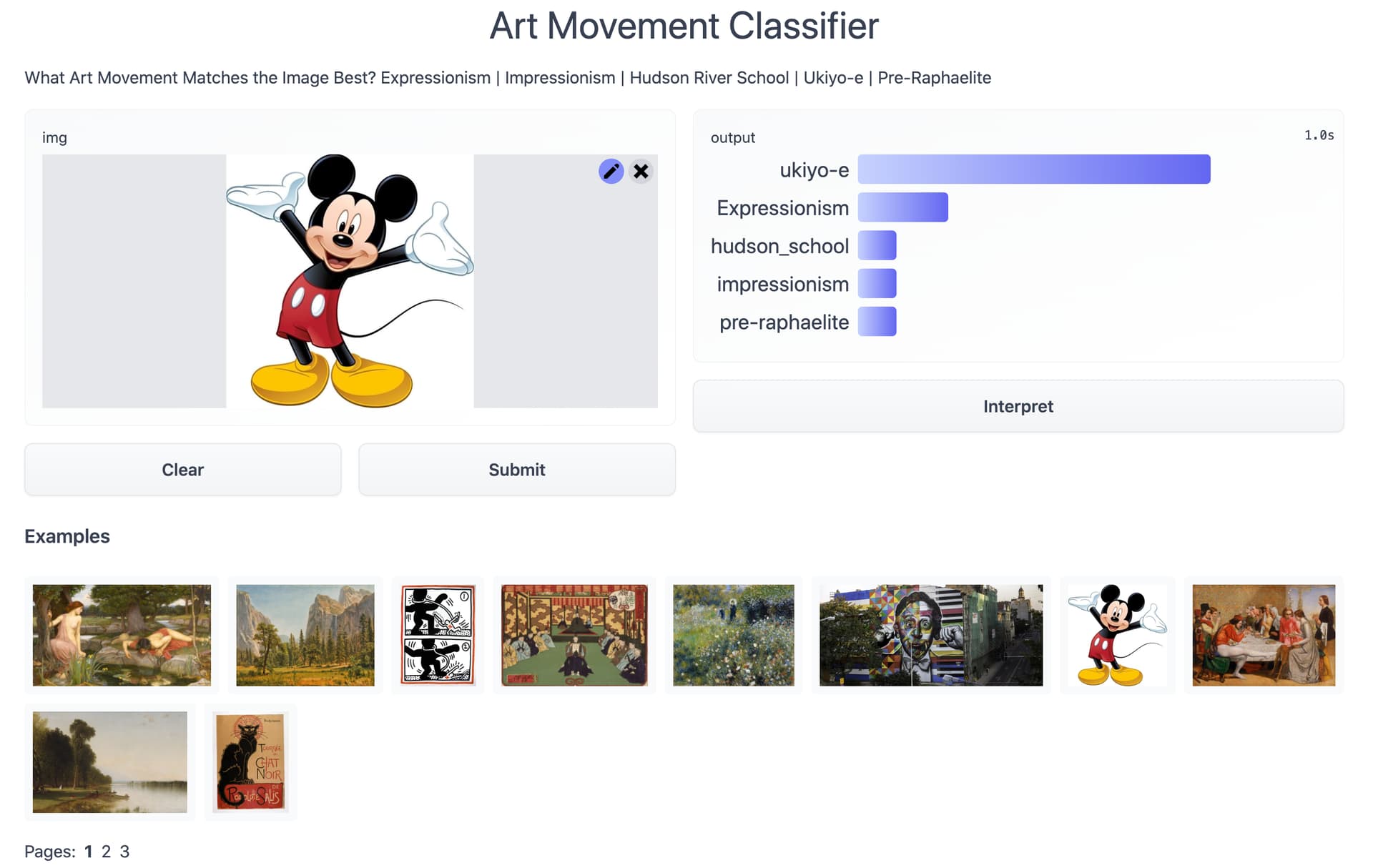
Next steps might be looking at training on the WikiArt dataset.
Also curious about scraping Twitter hashtags for generative art (Dall-e 2, MidJourney) and predicting likes / retweets.
Here’s my Hugging Face Demo
9 Likes