I build a ML model to classify music and to identify their genre using fastai on top of Kaggle Music Classification Dataset. The accuracy I got after 10 epochs was approx. 55%.
I wrote my experience on training this model in ML-blog. Do check it out 
I build a ML model to classify music and to identify their genre using fastai on top of Kaggle Music Classification Dataset. The accuracy I got after 10 epochs was approx. 55%.
I wrote my experience on training this model in ML-blog. Do check it out
BTW, the pickling error is gone in fastai 2.6.3
Even for lambda functions is that pickling error gone?
That, I do not know. A couple of us were getting the pickling error due to probably a threadlock issue in 2.6.2 and Jeremey pushed a fix yesterday.
Don’t use lambdas if you want to pickle … they are convenient (until you export).
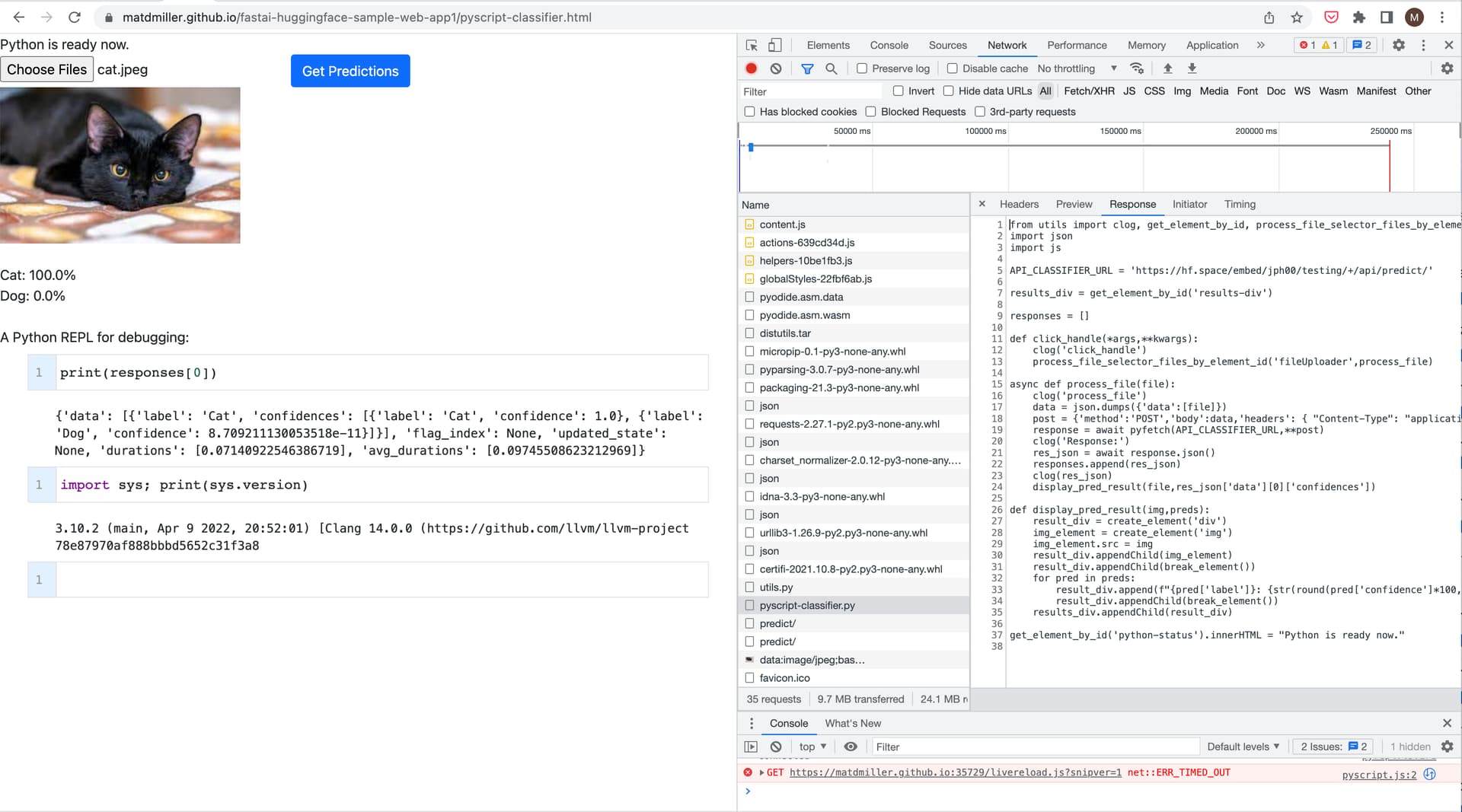
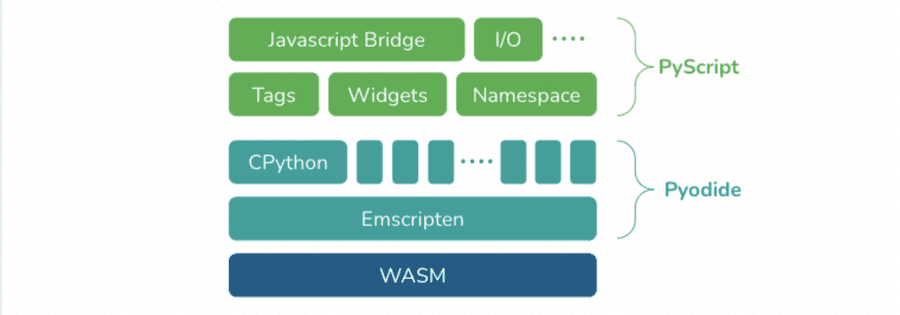
I just created a web app using the new pyscript project which was Announced by Annaconda yesterday. Pyscript enables you to run Python code within your browser on the client side. This is different than Jupyter where the python code itself is executed on a server and is simply accessed via the browser. Pyscript is still in Alpha so it’s very rough around the edges and can be a pretty challenging developer experience, but it’s a really cool concept and I’m excited to see where they take it. Unfortunately pytorch is not one of the packages that is currently supported so you can’t use it to run models locally yet.
You can access the app here:
https://matdmiller.github.io/fastai-huggingface-sample-web-app1/pyscript-classifier.html
I did a writeup on the project in another thread which you can access here:
wow … cool.
Very neat stuff. I wasn’t aware, haven’t gotten to catch up on tech. news this weekend. Very cool that Python* is getting access to WASM runtime. I’ll be keeping an eye on this. Thanks for sharing !
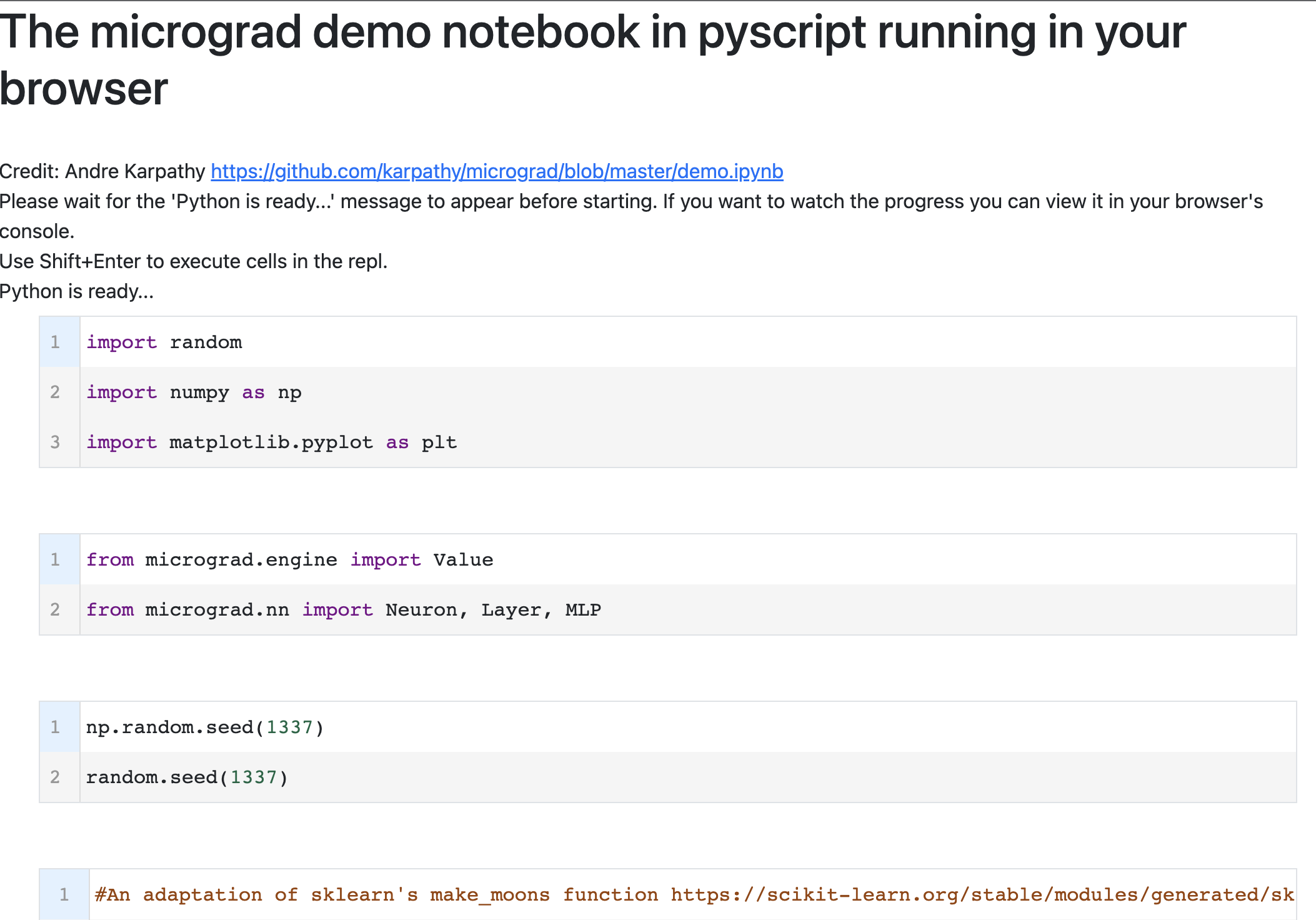
I created an implementation of Andrej Karpathy’s micrograd demo running inside the browser in pyscript. This trains a mini neural net inside the browser using his micrograd library.
This page allows you to run it interactively like you can with a Jupyter notebook, except this is running inside of your browser.
https://matdmiller.github.io/fastai-huggingface-sample-web-app1/pyscript-micrograd-demo.html
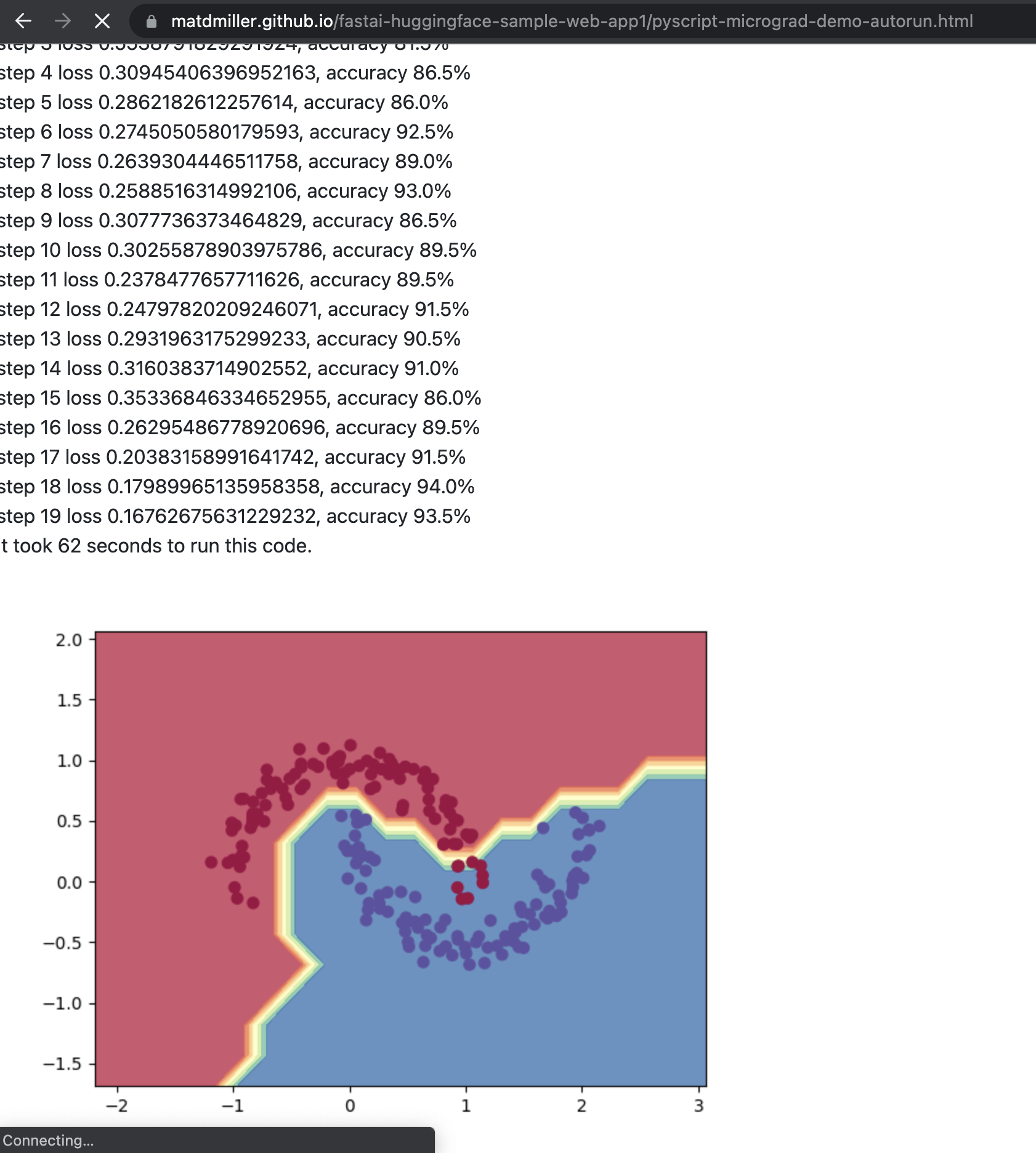
This page automatically runs the entire script and displays the training graphic at the end when it’s done. I wanted to test running this demo on my iPhone, but couldn’t run the Jupyter/REPL cells on my iPhone because I can’t click Shift+Enter to run them so this just automatically runs the entire script. Amazingly, it works!
https://matdmiller.github.io/fastai-huggingface-sample-web-app1/pyscript-micrograd-demo-autorun.html
More epochs yields better (100% accuracy) accuracy, but the speed/performance of this is not great, so I cut it down to 20 epochs so it finishes faster.
If you share this on twitter and post a link here, I’ll retweet it and make sure Karpathy sees
Wow! amazing work! it took a couple minutes to run on my 12 year old macbook air running linux (in Chromium) … amazing to see this running in a browser.
Really awesome stuff
Awesome, thanks Jeremy! Here’s the link to the tweet:
For this first project, I wanted to try something a bit more abstract than just objects. Here, I train a model to classify the four seasons from images obtained from Duck Duck Go:
In terms of hyperparamaters, here are some adjustments that seemed helpful:
Architecture: I tried resnet18, resnet34, resnet50 and resnet101. With smaller training sets of 100-200 images/season, the smaller architectures outpreformed the larger ones—as high as 90-95% accuracy. I pursume this might in part be due to overtraining. Additionally, the smaller sets of images are likely have been more homogeneous than the larger training sets. For the final model I used resnet101 and 750 images/season with resulting accurcay of 80-85%.
Number of Pictures: 150 training images/season were initially used. These trained very well. As I increased the training sizes, performance dropped. I believe that this is because the larger training sets were much more diverse. I could verify this by looking manually at the DDG search results: later images diverged significantly from earlier images. For the final model, I used 750 training images/season. These larger training sets did not perform as well. Hopefully, the larger and more diverse training sets will perform better In the Wild, with real test data.
Image Size: 400 size images performed better than 300 size images
Transformations: squish outperformed crop
Training Epochs: 5 training epochs with resnet101 showed continued reduction in both training and validation losses
Cool HF demo. I noticed that the inference can take a really long time (upwards of 20 seconds). Do you have a sense of why that is? Is it on account of the model being large (i.e. fine-tuned off resnet101) or are the sample images large or is there something else going on? Curious if there are some tips on how to keep that inference time low.
I’ve noticed the lag as well. Moreover, it’s quite variable. Picture size, network/server load at HuggingFace, not sure. It is free. I would guess the paid models perform better. Frankly, I had never heard of either Gradio or HuggingFace till yesterday reading through the forums. Very cool
My Chosen Problem Statement: A lot of people tend to confuse apes for monkeys.
Example: Monke Never forget’s
Therefore, I have decided to tackle this very important issue by creating an “Ape vs. Monkey” classifier.
Plan:
Stay tuned…
It’s running on CPU, not GPU, and a ResNet101 is a really big model to be running on GPU, especially with such large images!
Generally I’d try to get 224x224 pixel images with ResNet34 working for reasonable CPU latency.
I wrote up my attempt at training a model to recognise my very cute (but not particularly intelligent) cat, Mr Blupus.
I ran into exactly the problem with validation data that Jeremy describes in chapter one, where my model was ‘cheating’ by learning to recognise my house (i.e. the photo backgrounds) and not my cat.
I reran the experiment with a held-out test set and surprisingly the model still did pretty well. I’m not sure if I did something wrong with how I calculated the accuracy using the test set, but in any case it was a useful lesson to have experienced in a practical way. (Thanks for the help with the final step, @FraPochetti and to those in the delft-fastai study group who encouraged me to collect a held-out test set.)
That’s a very good name for a not very intelligent cat. Did you know about its limited intellect before you named it?..