I just read your blog , nice work !
https://kirankamath.netlify.app/blog/matrix-calculus-for-deeplearning-part1/
blog on matrix calculus
I recently finished up a project analyzing 4.5 years of my own journal entries; most of it was exploratory analysis, but I was able to use fast.ai to create a language model and thereafter predict text.
Here’s one of the better predictions (the majority of my journals were written while I was in high school, so naturally it talks a lot about school, classes, and the like):

There are some repetitive/nonsensical sections, but it reads pretty similarly to my actual journals, so I’m happy with it.
This result is just with the learner.predict method; in Lesson 4 Jeremy explains that learner.predict is worst-case text generation, but I wasn’t able to get anything better with beam search or nucleus predict.
If you’re interested in the rest of the exploratory analysis/insights, I wrote an article about the project on Medium here.
2 Likes
I finished my lesson 2 project. It’s an image classifier for jaguars and leopards. I was able to make the app work (repository) by modifying the render example and using flask instead of scarlette . and then upload it to heroku. You can check it out here today.
2 Likes
Hey there, can you share a little bit of your experience with the little guy? Especially doing the course lessons on it. I doubt it has much value here but I am really interested in the product.
Thank you!
So, bad news: fastshap and ClassConfusion are now gone. Good news? Instead we have fastinference  What all does it do?
What all does it do?
- Speed up inference
- A more verbose
get_predsandpredict- You can fully decode the classes, choose to not have the loss function decodes or the loss function final activation if you choose, return the input, and the other behaviors you would expect
- ClassConfusion and SHAP
- Feature Importance for tabular models with custom “rank” methods
- ONNX support
All while never leaving the comfortablefastailanguage!
See the attached screenshots. To install dopip install fastinference. Documentation is a WIP, please see the /nbs for examples for now. Need to deal with somefastpagesissues.
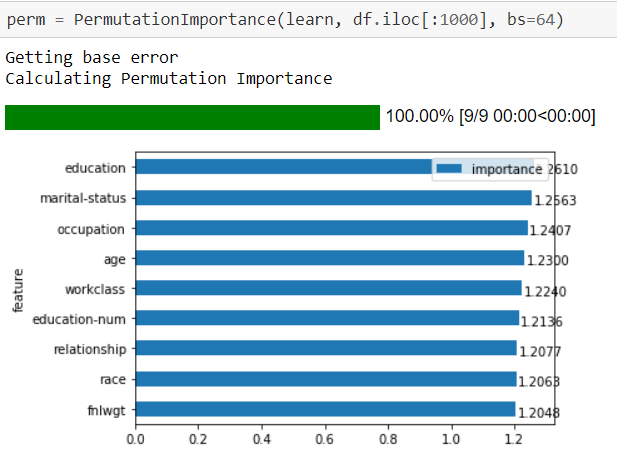
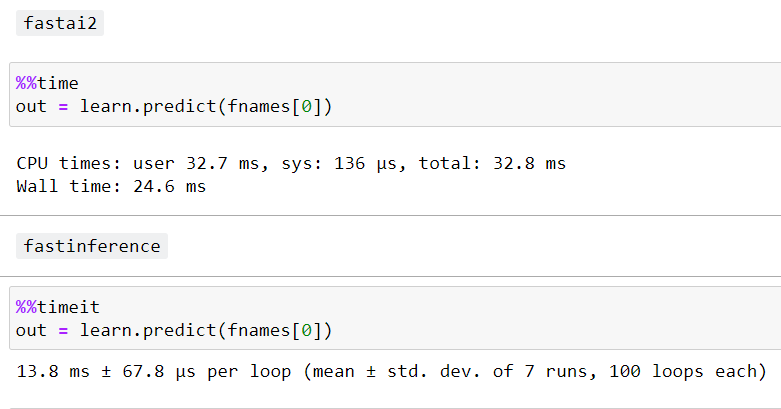

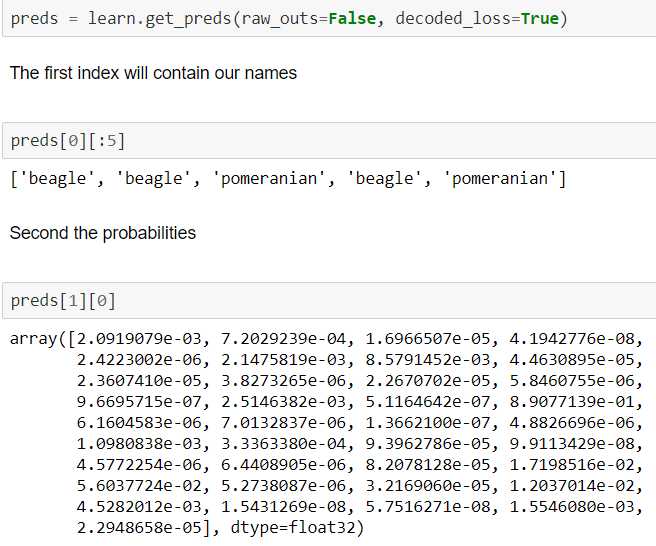
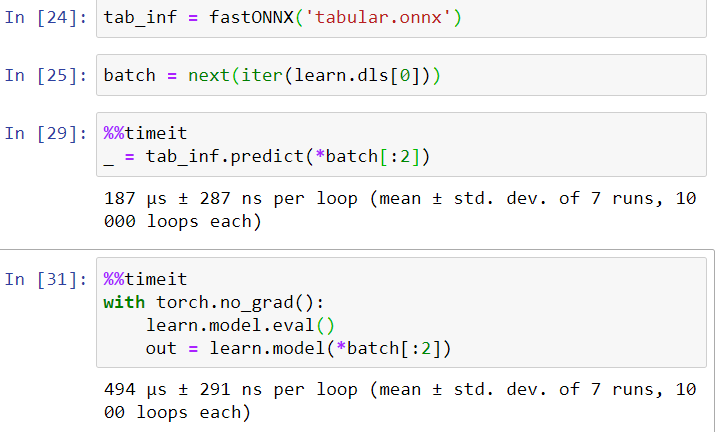

7 Likes
I used the Google-512 data set to create a classifier that identifies the dominant color in an image.

3 Likes
This is very cool!
Is it possible for your improvement to be brought into fastai itself? Or are there design decisions you had to make that are incompatible with fastai?
1 Like
Yes to this. Specifically there is no progress bar now (that takes extra time) and callbacks no longer exist in my version. It’s geared towards deployment only (hence fastinference) by pulling away as many extra bits as we possibly can to make it barebones speed-based. (As much as I would like these to apply)
Basically I systematically peeled back a few of the inner layers of fastai to get this speed boost, but of course everything must have a cost, no such thing as a free lunch ![]()
2 Likes
My notebook: https://gist.github.com/misham/0f429bdc61c53190b633d4f7bd6b3360
I’m experimenting with content from Lesson 1 and started with MNIST data from https://course.fast.ai/datasets. I went through the Learning Rate finding exercise and re-trained the model using a couple of different learning rates. However, I got results in the 99% range and that seems like I’m over-fitting the model here. Hoping to get some clarity on the following questions:
- Is the model over-fitting?
- How should I interpret the
lr_finderresults? The graph is “confusing” as it’s just climbing up. The dip is so minor, is it “significant”?
Thank you
Now includes text support for the AWD-LSTM! Including intrensic attention (via learn.intrinsic_attention) and sped up .predict by 10x (get_preds didn’t see that much of a speed boost)
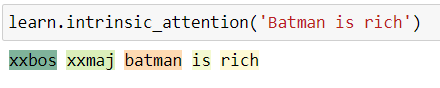
4 Likes
Hi everyone!
I wanted to try and determine whether a person’s way of typing on messaging platforms could be used to identify them!
I’m from India. Usually when we chat with our friends on messaging platforms, my friends and I tend to type in Hinglish- a cross between Hindi and English- it consists of several Hindi words written in English and involves mixing them to talk.
So I first had to train a model that could predict the next word in a Hinglish text.
So I took a whatsapp communication of myself and a friend and trained a model using the fastai library and got a 70 percent accuracy while trying to identify the person typing a message! Its really fun and you cant try it out with your own chat data as well if you like! All you have to do is export your chat in whatsapp to the colab and run the cells!
https://colab.research.google.com/drive/1X2TntPeN5ZwdJWNjbLGZGEDwl8_TGFRI?usp=sharing
I’d really love to know how i can improve on this project and make it cooler!
Thanks a lot you guys!
4 Likes
Hi everyone,
I wrote a short story on medium about TorchServe, what it is and how do you use it to deploy your pytorch models or fastai models. You can also see what’s been added to the latest version and a “Hello World” MNIST example with PyTorch. Dig in!
4 Likes
Hello guys!
Silvia from Sweden here.
I made a small project looking into how to detect fake face images generated by AI using the Lesson 2 material as the base for building my classifier. I came to some interesting conclusions shedding some light on how GAN-networks may work “behind the scenes” with face images.
I was setting the goal to fit the model to perform well in production (99,99 accuracy) and not only for the validation set (99,21%). The result made me proud since it’s my first go at building an ML-classifier. My background has been iOS-development for many years but I’m currently wanting to switch into Data Science and the Fastai course material has been invaluable for me. Thanks so much 
Any thoughts, feedback, or cheering would be much appreciated. Open for discussions on the result!
The promised Part 2 of the blog post has been delayed because of me and my family infected with covid19 just a couple of days after Part 1 was published. We finally came out from the tunnel, and the rest of the writing is now underway - first I just have to remember what I did…  .
.
https://blog.jayway.com/2020/03/06/using-ml-to-detect-fake-face-images-created-by-ai/

10 Likes
@corabius This is your first ever ML classifier?! I’m deeply impressed, amazing work! I’ll read the complete blog post tomorrow
1 Like
Hi everybody!
I’d like to share my first project, which I finished today. It’s a web app that lets you draw a digit and tries to recognize it. To make it a bit more interesting, it also shows the probabilities of all numbers.

The deep learning part is pretty straight forward, I used a ResNet18 and MNIST.
I spent 99% of my time on the app, getting it to work on desktop/mobile devices, getting to know Vue.js, and a lot of bug fixing…
Things that I learned:
- 99.x % accuracy during development doesn’t mean 99.x % in production. For example, the dataset consists mainly of American style digits, European 1’s and 9’s look a bit different and definitely perform worse.
- It would be useful to have an “other” or “none” category for weird shapes.
- ResNet18 is probably overpowered for the task, I’d rather have it run faster for the sake of accuracy, maybe I’ll change that.
- I have no idea how to make it work on more than one digit
This was quite a bit of work for a trivial deep learning task, but it was fun and I learned a lot for further projects.
Cheers, Johannes
9 Likes
Yes it is
Later today I’m planning on publishing the second part of the blog post more focused on understanding the features of AI-generated face images and it’s implications.
Nice work, cool application!
My blogpost (which you say you are planning to read) explains my thinking around accuracy in training/validation versus production. I also explain how I went about to change the production accuracy to become better than the accuracy obtained for the validation set. I believe you can go ahead and apply the same thinking to your project to improve the production accuracy if you would like.
1 Like
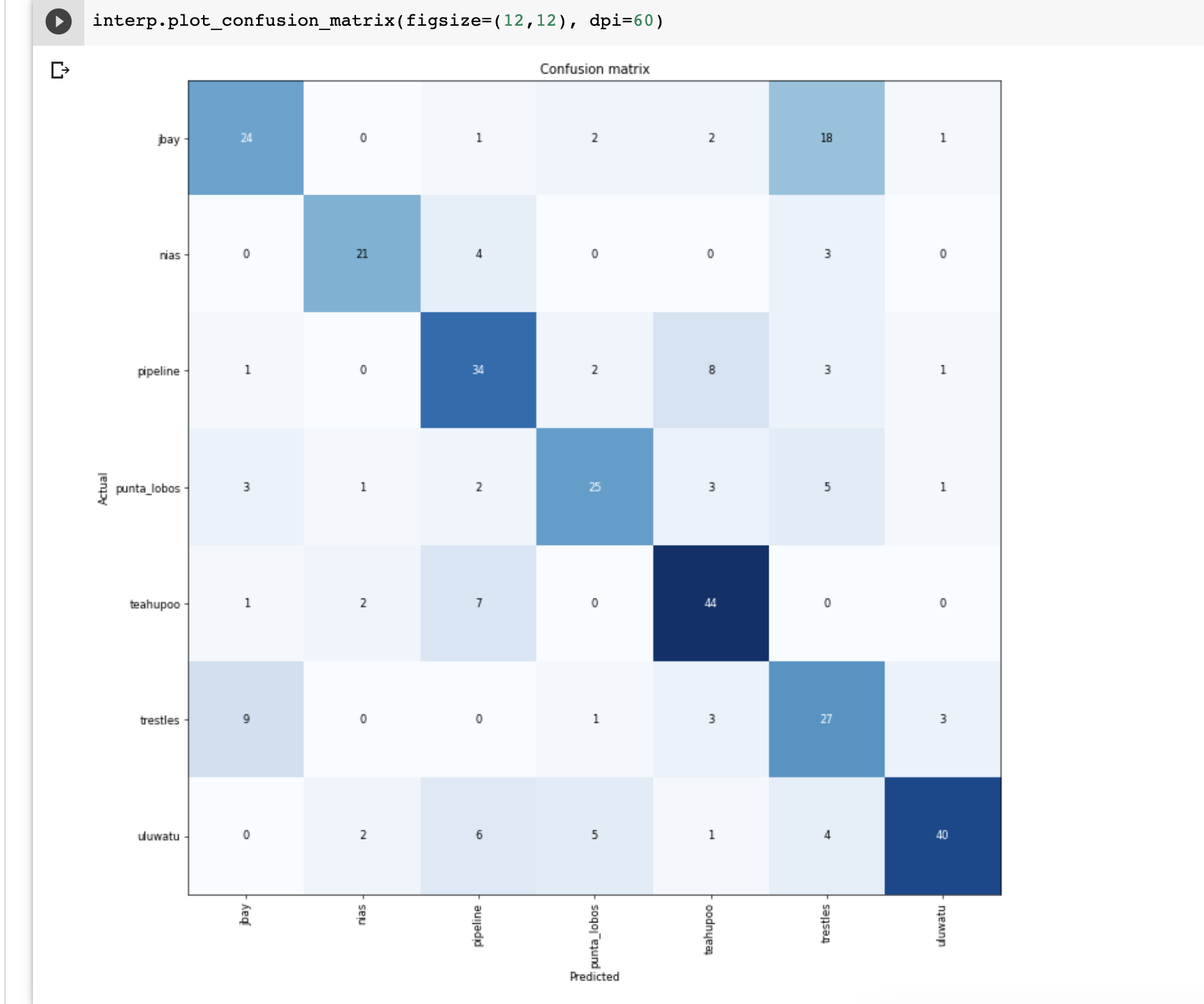
For trying to practice with lesson 1, I made an image classifier for some of the world’s famous surf spots.
I created an image data set with fastclass. Got around 250 images of each surf spot/wave, and manually cleaned them.
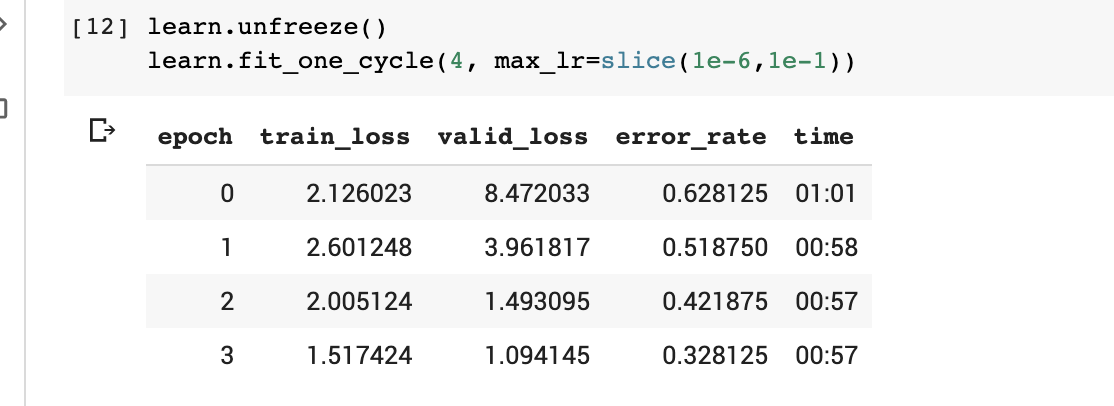
Managed to get to only 67% accuracy, with resnet50 after fine-tuning.

The closer photos are definitely very hard to identify.
The biggest confusion appears to be between California’s Trestles and South Africa’s J-Bay, and between Pipeline and Teahuppo (they can look similar in the biggest days on a close shot picture)
2 Likes
Hello Everyone
Hope you’re all well. I just got through coding my own interpretation of Lesson 1. Built a classifier based on the fruits360 dataset(https://github.com/Horea94/Fruit-Images-Dataset). Their research paper shows the highest accuracy they achieved was 98.66%.
Using fastai i managed to attain an accuracy of 98.82% on resnet34 and an accuracy of 99.84% on resnet 50.
Since i’m new to this machine learning domain
Note: i did work on keras and tensorflow before but those require a very deep ml knowledge to understand, this is why i love fastai, i’ve already understood a lot of concepts in deep learning just by coding in fastai than i did in the past whole month of coding in keras)
Anyways i’m confused on whether these accuracies are good or not meaning has the model overfit or sth?(midway through lesson 2 will prolly understand overfitting after all the lessons)

Here are my results for resnet 50

Kudos and loving fastai thanks for an awesome approach to deep learning!
4 Likes