Here’s a writeup I did for a competition I participated in on the Zindi competitive data science platform. The object of the contest was to use remote sensing imagery from different timepoints to classify what types of crops were growing in fields with given boundaries. I used a U-Net style approach and I found a really nice library called eo-learn to help with the processing pipeline for the remote sensing data.
6 Likes
Cricket vs Tennis ball
This is my second pass (had done V1 last year partially). Being and Indian, I had to do something with cricket. While we use both types of balls to play cricket, thought of asking machine to learn the differences (while we ignore those during the cricket session  )
)
A big shout out to @melonkernel CHRISTOFFER BJÖRKSKOG and his post for cleaning up the wrong images and generating URL list via a bookmarklet
Did this using Google Collab
So… was able achieve 98% accuracy even before unfreezing the laters… so just sharing it here.
PS: one of the images look as stupid as my silly experiment… hopefully I will be able to find something really useful eventually

1 Like
Hi mkulkhanna
Great job.
You presented a complex subject in an easy to digest style.
Cheers mrfabulous1 
1 Like
Hi, I entered a Kaggle competion for number recognition and I am currently ranked (11th, top 3%), this is my first Kaggle competition.
My profile: https://www.kaggle.com/rincewind007
5 Likes
For those interested, an energy kaggle competition opened up this week and I have a fastai 2.0 starter code available here
5 Likes
Hi
I tried a simple CNN on Kaggle, https://www.kaggle.com/mgtrinadh/basic-fastai-model, to try hands-on & understand on how to improve accuracy.
Am on lesson-5 & am all excited to try out a kaggle problem!
Best
Gopi
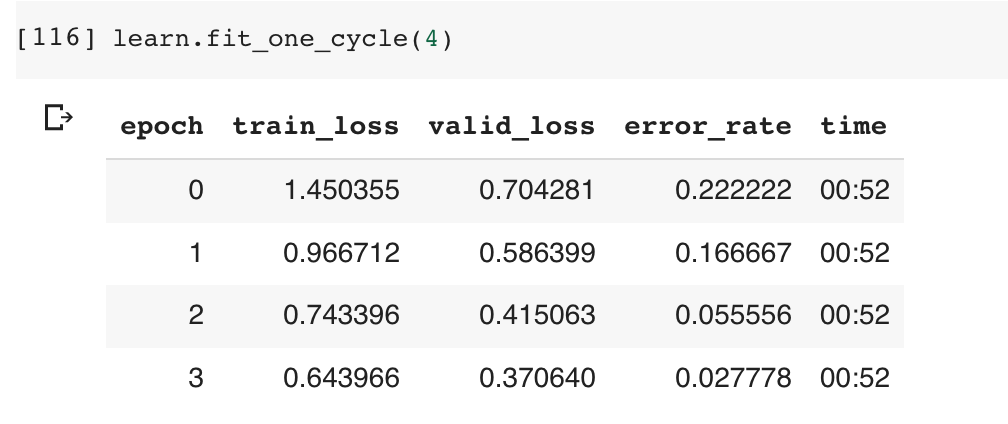
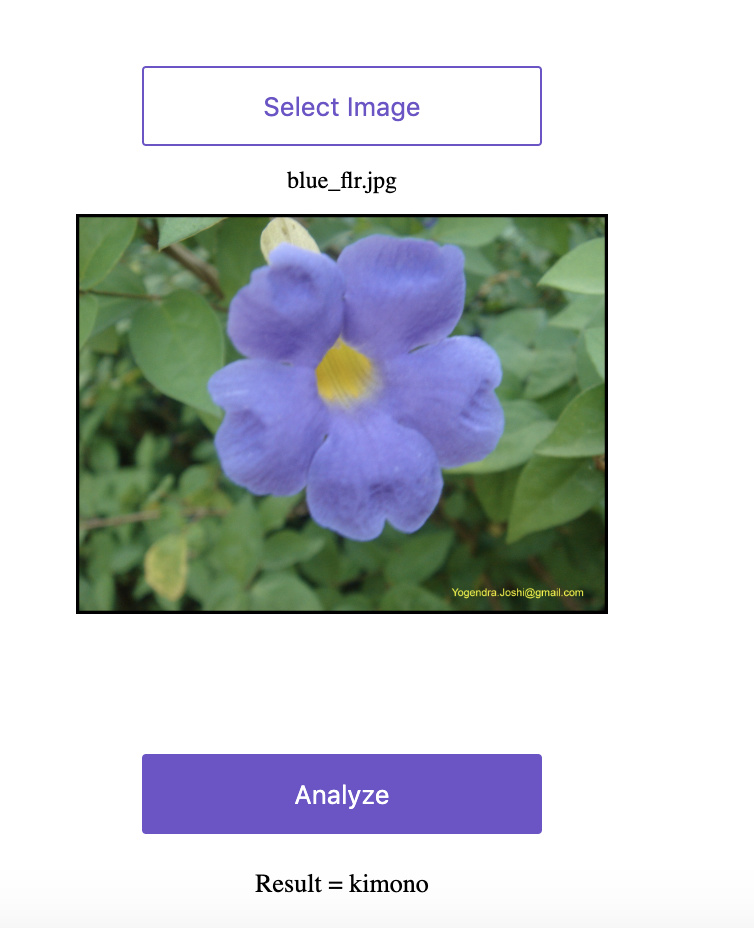
Just finished the second lecture. I made a model for classifying between East Asian traditional dresses - Kimono, Hanbok and Qipao. I was able to achieve 95% accuracy . On retraining the models several times, I kept on getting different Learning rate curves. I am not sure why that happens but I will be asking that on the forums after this post.
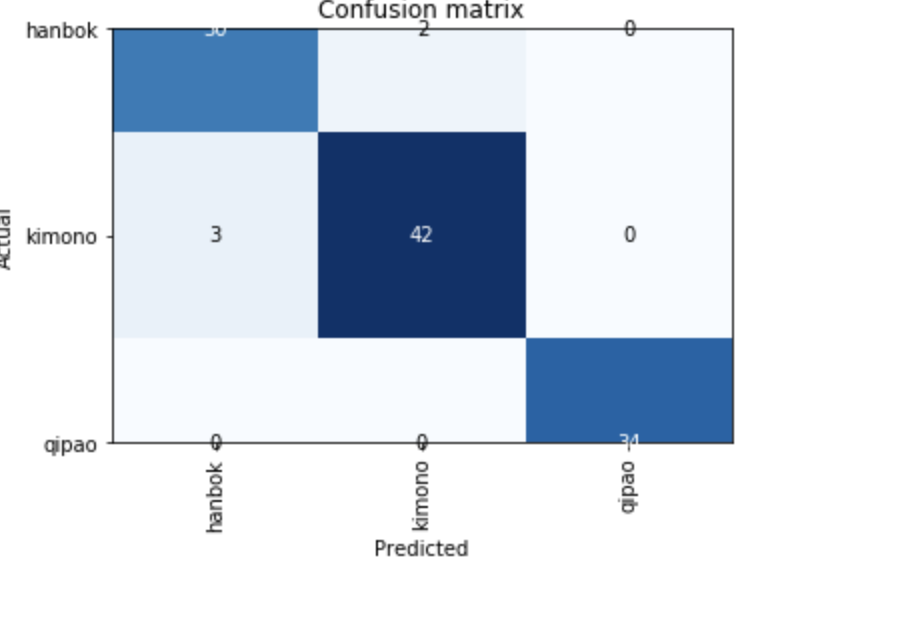
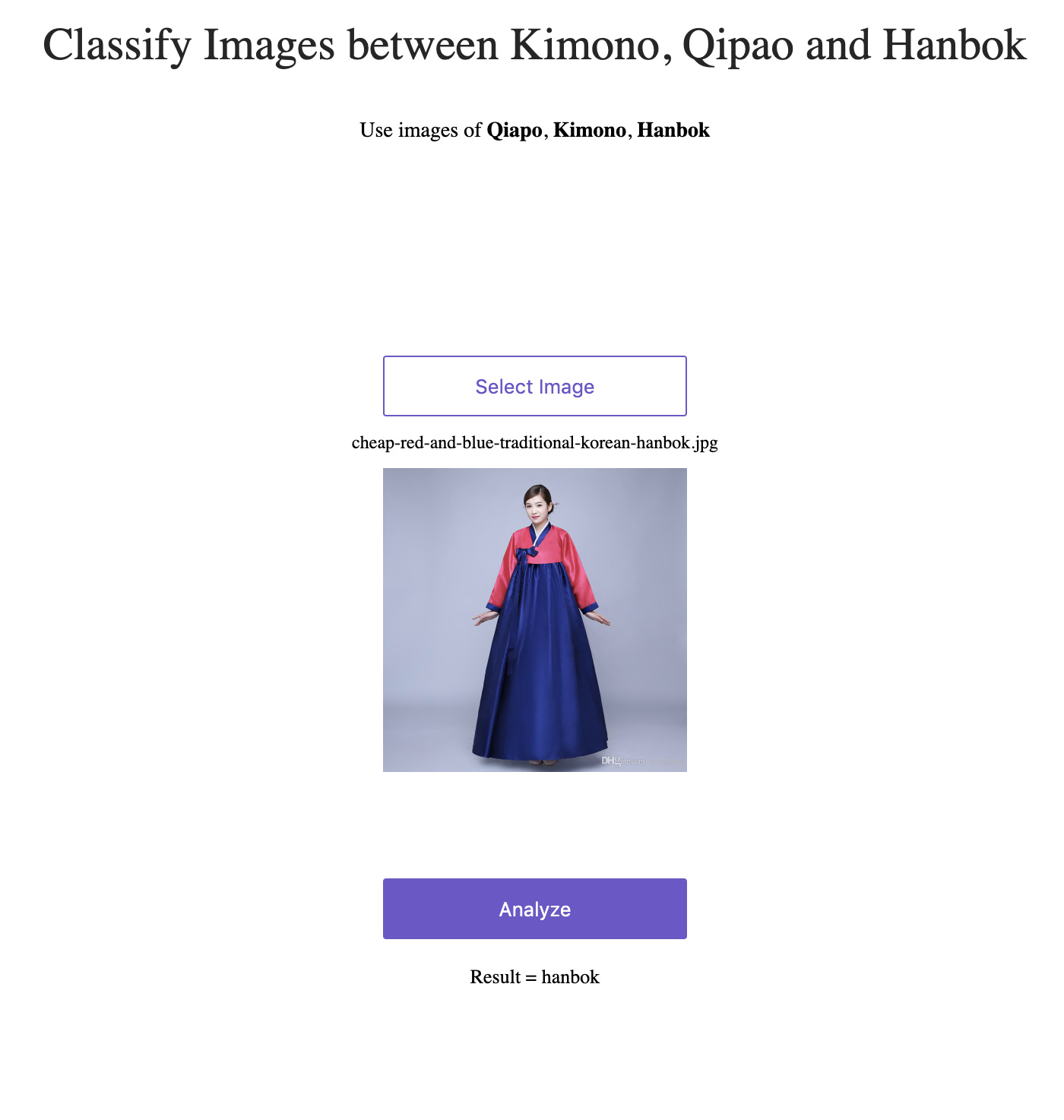
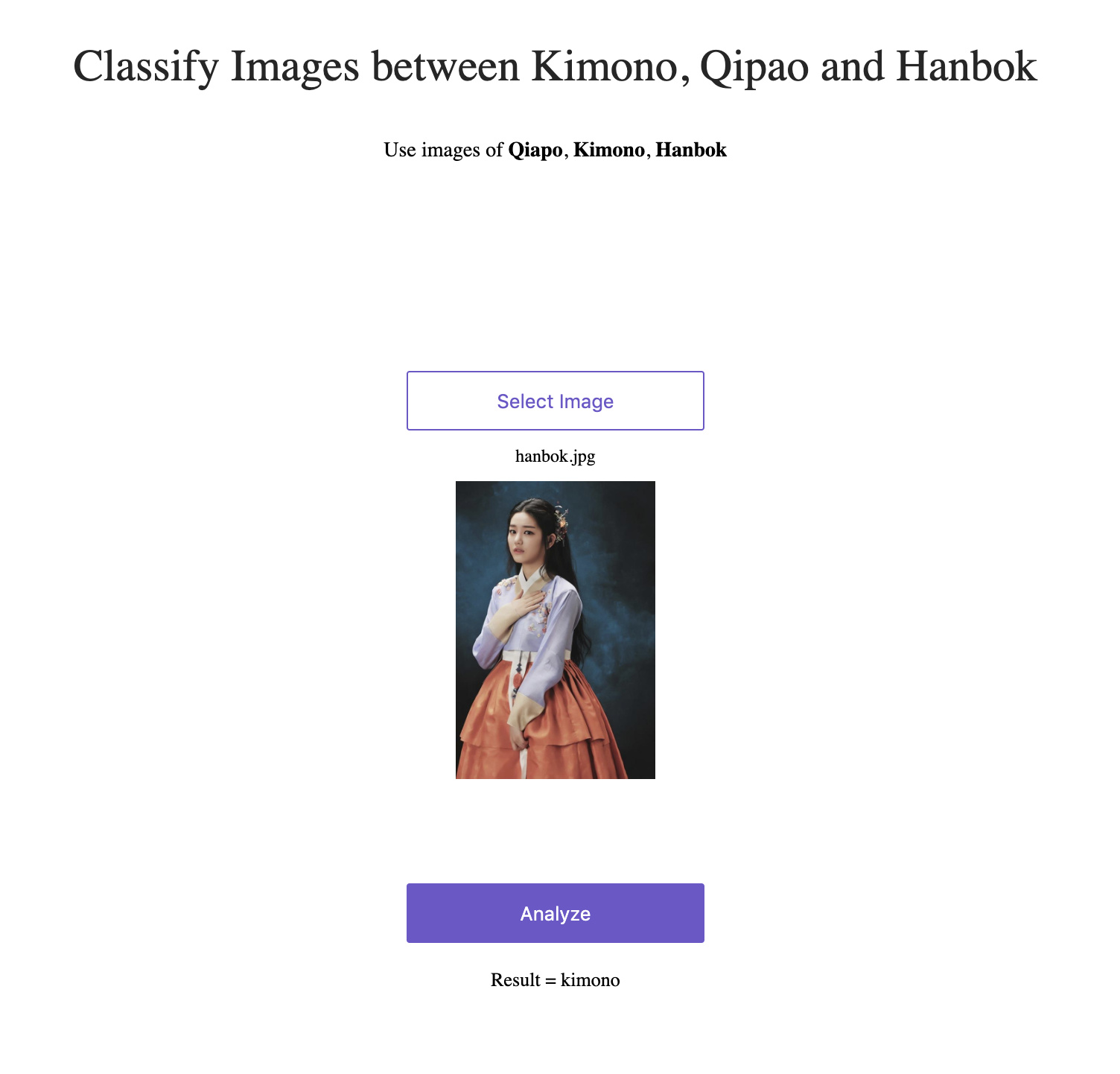
The model could classify a Qipao correctly. However, some times it classified a Hanbok as a Kimono.
Web link to the production : Traditional Dress Classifier
Detailed Medium Blog Post : https://medium.com/@varundhingra004/classifying-east-asian-traditional-dresses-using-deep-learning-and-computer-vision-59dc71f97d77
3 Likes
Hi to all!
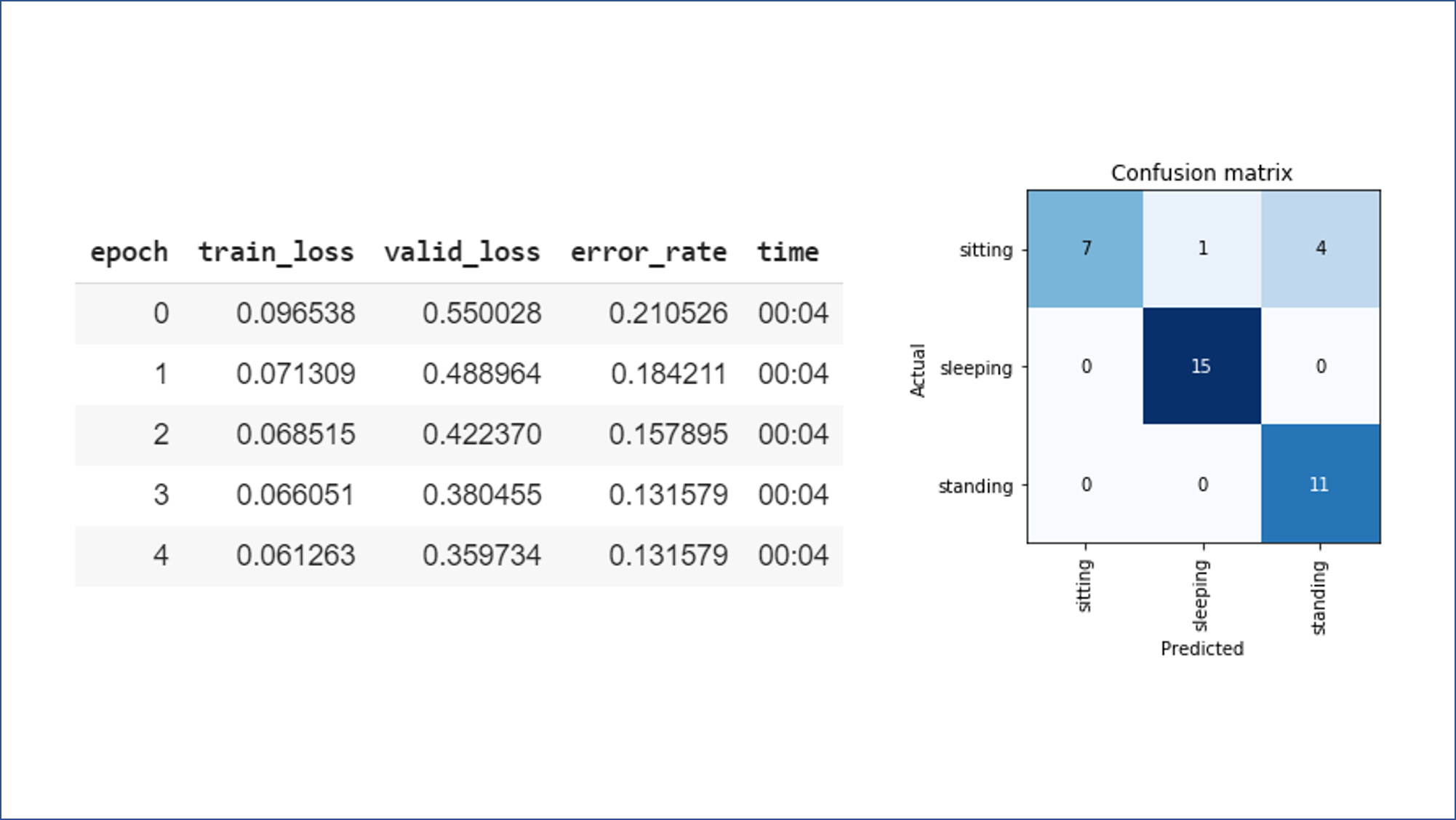
I used the tutorial on how to download pictures from google images to assemble a dataset, to train a so-called “Baby Monitor”. Its purpose is to take a picture of a baby in the crib and predict if the baby is sleeping, sitting or standing.
As you can see in the picture I got a 13% error rate, which is pretty good considering that I only used the defaults (the model was a pretrained resnet34 architecture) and my training set is around 170 images for three categories.
I have two questions:
- In my experiments most of the time the validation loss was lower than the train loss. Why is this happening and is it that bad?
- Is it really that easy to get such good results?!
nicely done! Also nice medium article. I have never tried doing that, let me try that. I am also experimenting with Lesson 2 & 3 currently.
Few queries
- Which tool did you use for images? How large was the final training/validation dataset? My experience was that out of 500 Google Images URLs for each class I only got 50-70 images which are valid, rest were deleted as invalid.
- I am trying to make my model tell me “I don’t know” when someone gives an irrelevant image. Would you want to collaborate? (as you can see your deployment can also help from that so it can tell something is not even a dress )
Hope I am not too nosy!
Hey Dimitris
This happens with me as well. After searching the net for answers, I found that there are 4 main reasons for validation loss being lower than training loss as listed below. Usually this happens when you have a small dataset or you train for too few epochs as random error is high in such cases. We can expect a small margin of error due to reasons 1 and 2 also as mentioned below. My understanding is that if the validation loss is equal to or slightly more than training loss then it is the best scenario.
The 4 reasons-
Credits
1: Regularization is applied during training, but not during validation/testing.
2: Training loss is measured during each epoch while validation loss is measured after each epoch. On average, the training loss is measured 1/2 an epoch earlier.
3: Your validation set may be easier than your training set or there is a leak in your data/bug in your code. Make sure your validation set is reasonably large and is sampled from the same distribution (and difficulty) as your training set.
4: You may be over-regularizing your model. Try reducing your regularization constraints, including increasing your model capacity (i.e., making it deeper with more parameters), reducing dropout, reducing L2 weight decay strength, etc.
2 Likes
Hello everybody,
I want to share some work from the previous months:
- You can find my notebooks for the 117th place solution [0.718] using PyTorch & fastai from the Recursion Cellular Image Classification kaggle competition on GitHub.
- I also created a kaggle kernel with a fastai v1 dicom databunch with visualization for the ongoing RSNA Intracranial Hemorrhage Detection kaggle competition.
- And I gave a short introduction to the fastai library at the Vienna Deep Learning meetup.
Thank you all for the great & encouraging community! The last months I really learned a lot from you!
4 Likes
Hi @jeremy,
I want do deploy Image Classification on Android using Pytorch Android API.
It requires .pt file, but using learn.save() i am getting only .pth file.
So how can i convert .pth file to .pt
This should be helpful: https://pytorch.org/tutorials/beginner/saving_loading_models.html
The reason for the imbalance is that the dataset is actually 1/3 Normal, 1/3 Bacterial Pneumonia and 1/3 Viral Pneumonia. I recently tried classifying viral vs bacterial, parsing the filenames within the PNEUMINIA folder to get the labels.
Unlike NORMAL vs PNUEMONIA, where many have achieved accuracies in the high 90’s, I was only able to achieve around 77% accuracy for bacterial vs viral. I would be interested to learn if anyone has been more successful.
My notebooks can be found at: https://github.com/williamsdoug/ChestXRay
Hi,
I used the Fatkun image downloader. It has been mentioned in the forums in another topic. My dataset consisted of 670 images.
Thanks for showing me the importance if having an ‘I don’t know’ class. I feel there are two ways of making the Neural Network say “I don’t know” :
-
Create a new class labeled as ‘unknown’ and fill it up with images of everything that is not related to your problem. However, this is very unrealistic.
-
Try to extract the features from the Neural network and pass the features through a Machine Learning classifier (Like a decision tree or SVM). This method however requires us to get some knowledge on Neural Network theory.
1 Like
Hi everyone! After 5-6 months of intensive studies I deployed my first Deep Learning app. It is a personal project that I have worked on and felt it would be cool to deploy it. The app allows users to turn random pictures into paintings of 3 old masters Van Gogh, Monet and Cezanne. You can check out the app at photo2painting.tech
The app is a demonstration of how CycleGan models work in production and is deployed on a Digital Ocean droplet (free with Github as I am a student). The project is still on development, so I am eager for your feedback. Feel free to contact me if you want to collaborate on the project. If you guys want to check the code, I have open-sourced it here
Here are some examples:


16 Likes
Hi Attol8 hope you are well!
Your app is marvelous, you have done a great job and have created a good application of the course content.
The app shows your 5-6 months of intensive study have been well spent!
Cheers mrfabulous1
Thanks for the wise words @mrfabulous1
Hello @henripal, @daveluo and @lesscomfortable,
I saw that you worked all with satellite images. I am currently accompanying a group of students from the University of Brasília on Deep Learning. One of the PhD students is working on a DL project with satellite images and would like to use a pre-trained model with satellite images but they have more than 3 channels. How did you handle this problem? Thank you.
A post was split to a new topic: Share you work here - highlights