Done.
1 Like
I used jupyter nbconvert (it can also convert notebooks to other formats, such as pdf). Here is a bit more information on the exact steps that I took (there is also serving from github pages involved).
1 Like
For the object verification problem with new category I have posted last time, I change the technique used from binarizing the last layer to multi variate gaussian anomaly detection and the results is so much better. I have written it here: Object verification with new category added to model
The idea is we can based on the statistic of the features vector to calculate the probability of matching object. The multivariate gaussian anomaly detection is introduced in Andrew Ng course and summarized here: gaussian anomaly detection . I have changed a little bit from the original algorithms that I calculate the logarithm of probability because with high number of variables (128), the results can be too big or too small. Ex: Ex: 48 variables with 0.1 probability for each. The multivariate probability is 0.1⁴⁸ — Very small number
The histogram of probability of number 7 (which have the worst result from last time) and number 9 are below:
Number 7
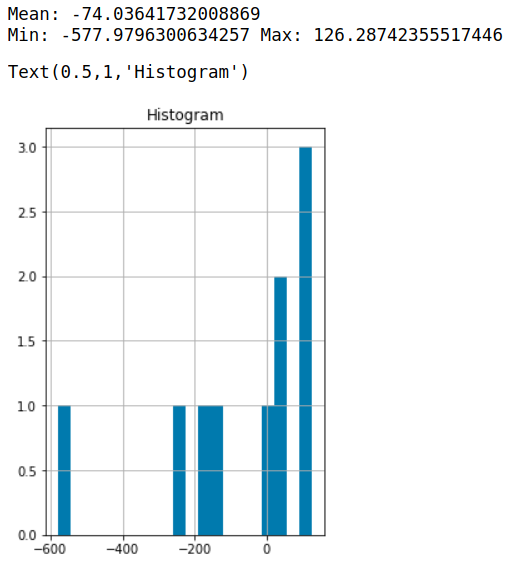
Number 9:

The probability of number 9 is much higher than number 7 this time. (I don’t know why the probability calculated by multivariate_normal . pdf in python > 1 , but I think the concept is the same so it is not a big deal)
Source code is here: source code
p/s: I haven’t tried the auto-encoder yet. I still think that the classification training will create a better feature vector to differentiate different object
1 Like
I trained a Language Model for arabic on a subset of sentences (I think 100000) from Wikipedia dump. the total dump is around 5GB, I trained on one file of 160MB, I couldn’t do more as even such small dataset collab kernel was on the edge! Also even with such small dataset the training took 3h!!
The result is not that great:
Total time: 2:11:32
epoch train_loss valid_loss accuracy
1 6.494748 6.450583 0.165572 (33:01)
2 5.982694 5.890470 0.187992 (32:54)
3 5.677928 5.628324 0.203663 (33:07)
4 5.383443 5.559011 0.208052 (32:29)
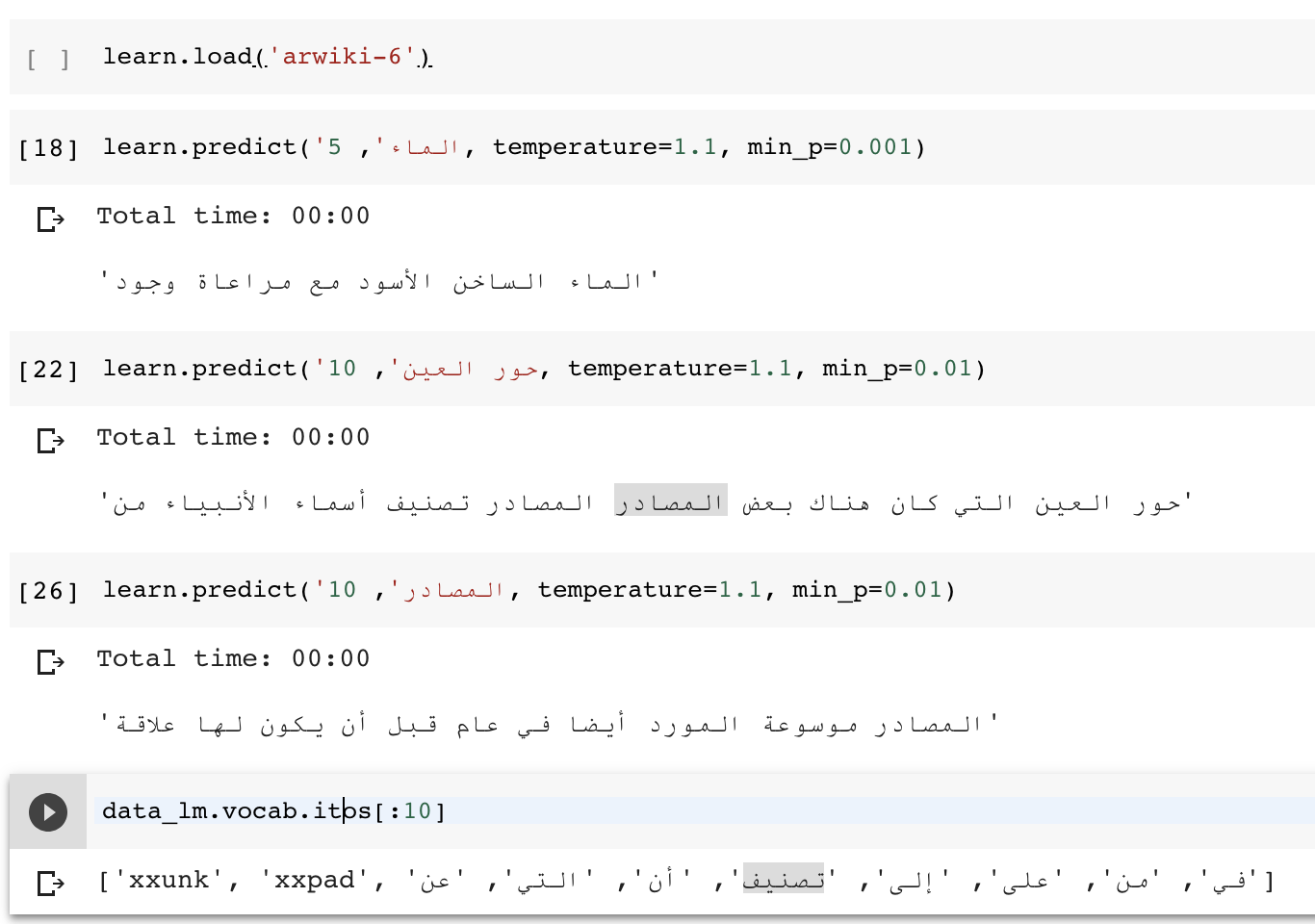
Here is entire steps from downloading the wikipedia dumps to the prediction - link
5 Likes
I made this a while ago, but didn’t share it with the group because I wanted to spend a bit more time.
Skin Cancer Classifier from:

Unfortunately, the dataset is highly biased. I used the default data augmentation settings + vertical flipping to mitigate these issues. More work can be done here.
nv 67%
mel 11%
bkl 11%
bcc 5%
Other (3) 6%
get_transforms(flip_vert=True)
I had it train overnight (roughly 7 hours) on resnet-50.
End results:
epoch train_loss valid_loss error_rate
496 0.003147 0.519515 0.074888 (00:50)
497 0.000316 0.526893 0.071892 (00:51)
498 0.000188 0.516914 0.071393 (00:51)
499 0.000186 0.522218 0.072391 (00:50)
500 0.000057 0.522059 0.072891 (00:50)
92.7% accuracy, the highest I could find in the kaggle kernels was around 78% accuracy.
You can see the error rates dropping after a while as fit_one_cycle adjusts over time.
End results confusion matrix:
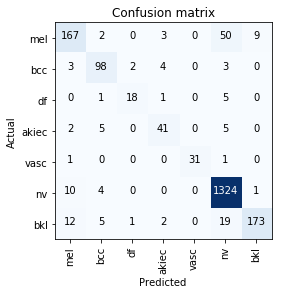
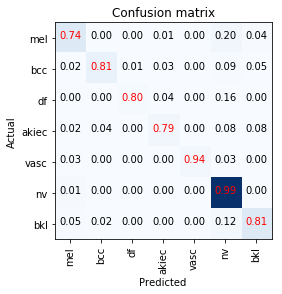
18 Likes
I’ve been reading the fastai library source code during my Thanksgiving trip both in the old school way (a decent-sized printout) and using VScode to navigate it. As a minor project I decided to visualize the key dependencies in a simplified way, and I’ve found the output helpful:

25 Likes
Hi,
I hope everyone is enjoying the holiday weekend. I made an age regression model using the wikipedia dataset. Notebook here.
To demo it, I made a web app at https://youngmeup.now.sh/
I added my own special linear layer at the end that I call the “soft-focus” layer. Through the magic of math it removes 10 years 
Thanks, Jeremy, Rachel and the fast.ai team for making it so easy to build cool stuff!
8 Likes
I built a language model on 26 works of fiction from Project Gutenberg. Here’s the notebook.
To train the model, I used paragraphs of text as observational units. Then I looked at how well the model was able to determine which work of fiction each of the paragraphs in the validation set belonged to. There was some class imbalance, so the final accuracy score of 71% may be a bit misleading. But looking at the confusion matrix, it does seem like the model performs well above chance, even for under-represented texts. The model’s most frequent source of error was due to misattribution of a different text written by the same author (e.g. one Charles Dickens book sounds a lot like another).
Two handy coding tips I learned:
-
plot_confusion_matrix()creates apltobject which can be manipulated directly (for relabeling ticks and axes, for example). This is nice because the method itself doesn’t return a Pyplot object - but once you know that thepltspace is currently representing the confusion matrix plot, you can adjust it as needed. - The
ClassificationInterpretationclass infastai.vision(which includesmost_confused,plot_confusion_matrix, etc) can be used for text classifiers, too. Super handy.
^ Apologies if those were already noted in class, I’m a bit behind on my lectures.
Happy holidays to all!
6 Likes
Hey lovely course community,
I wrote a blogpost about the inner workings of CNN. My aim is to put together a post series that guides the reader through the network - from an input image to the parameter optimisation - and thereby providing a introductory resource for those not familiar with the maths behind CNN yet. In doing so, the goal is to be as comprehensive as possible on the one hand and concise on the other.
The post is the first part in the planned series. And there will be more to come in the coming days and weeks.
As I started dealing with CNN and deep learning in general a few months ago, I’m sure there is room for improvement and I would be more than happy to get feedback.
4 Likes
Hey there! So this week I participated in this challenge. Using only the defaults of fastai library, I could get to top 26. Thanks all
4 Likes
Nice work. But I would be worry about overfitting. Such a big gap between train and validation loss may suggest it.
1 Like
While I normally agree, the metric I was most closely watching is errors of the validation set, rather than the loss.
Contrast the loss of the validation (orange) to the error rate of the validation set:
loss:
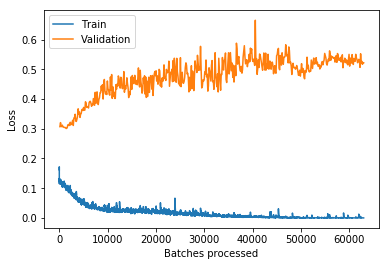
validation error rate:
What this tells me is the overall accuracy of the model improved, and it was less confident about its decisions.
(@jeremy: I would love to hear your opinion on this, I could be way off base)
1 Like
I tried working on Ultrasound Nerve Segmentation from Kaggle (https://www.kaggle.com/c/ultrasound-nerve-segmentation)
Following are the results on validation dataset :
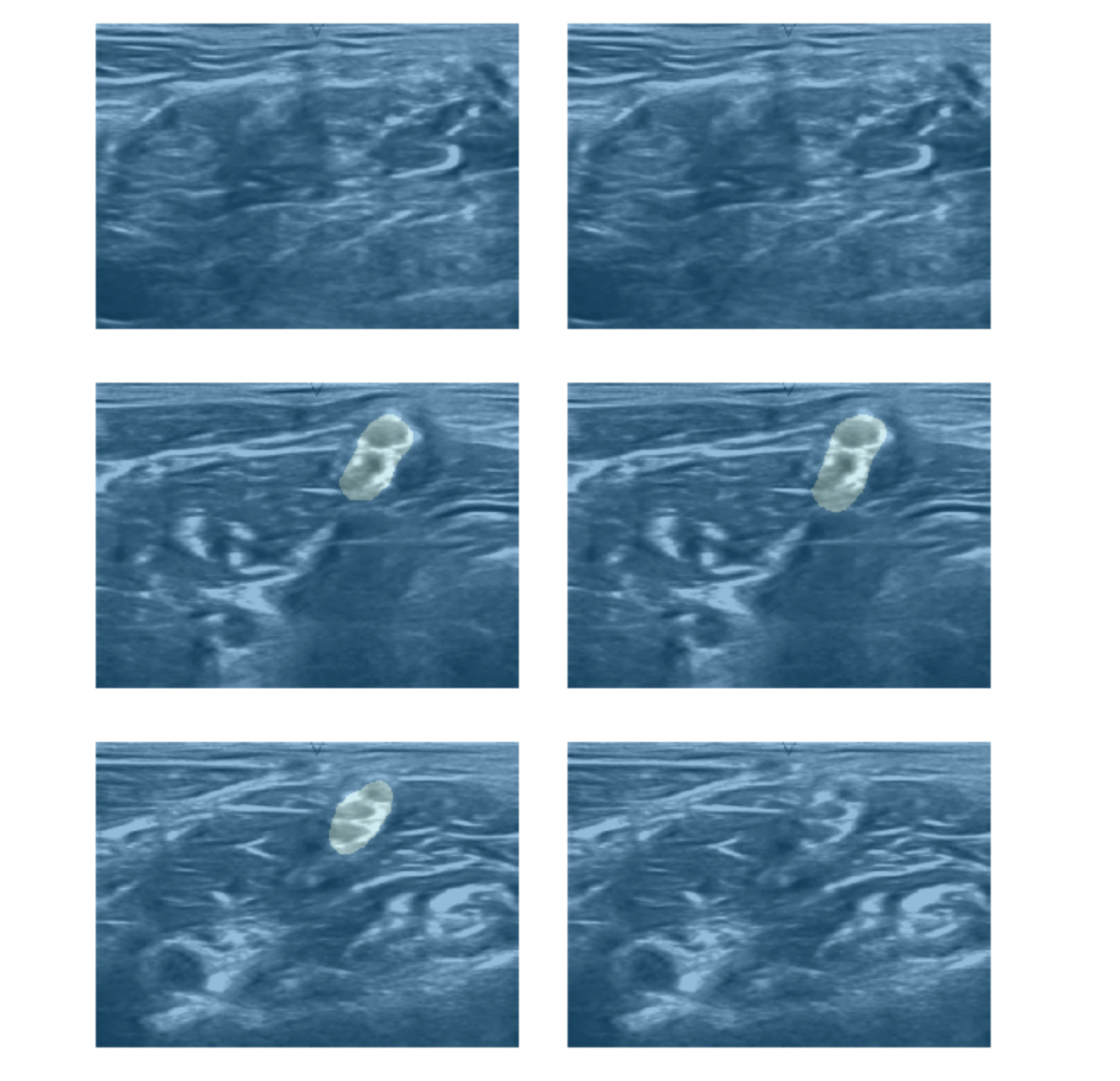
I tried to generate predictions for submission to Kaggle.However I am not sure if the approach followed is valid. Please suggest.
https://gist.github.com/ksasi/06c4adab25d03f27f6d9526df551c3c8 is the link for the notebook.
4 Likes
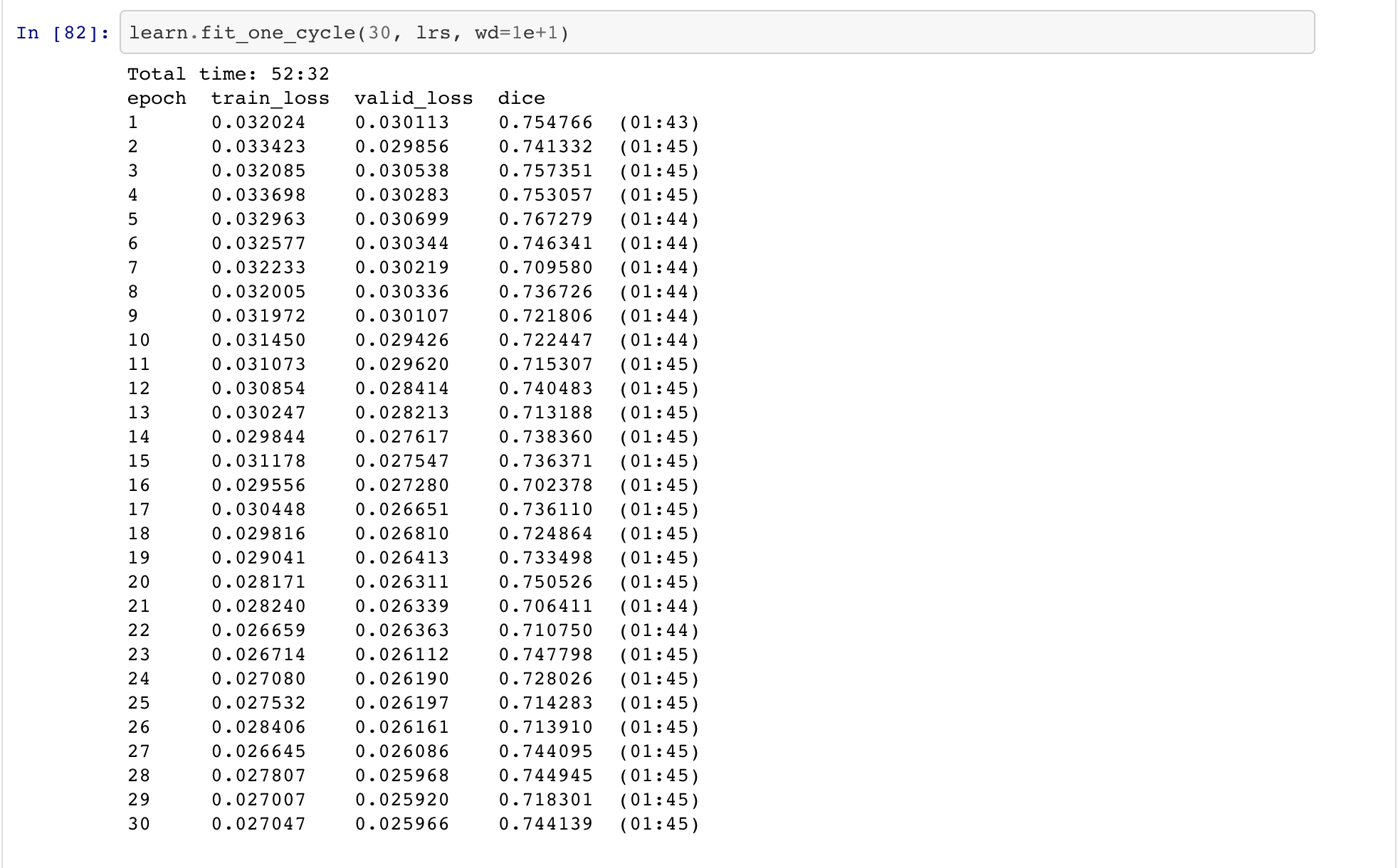
The overall accuracy improved, and it became over-confident of its decisions.
3 Likes
I just finished the second part focussing on the fully-connected layers.
2 Likes
For gaming enthusiasts, I decided to tackle on a nice kaggle dataset called 20 Years of Games. Using the techniques used in the ‘rossman’, which we will learn next week, I hope to improve these results.
Since the process was interesting, I’ve written the following short Medium post describing the details of the process.
The accompanying notebook can be found at this gist.
2 Likes
Added SVG with clickable hyperlinks to the fastai library source code (see notebook)
2 Likes
Hey everyone! I adapted the LIME repo to generate explanations for model’s predictions.
Here’s what the explanations look like:

Green part shows where the model reacted positively for a particular class and red highlights parts where it reacted negatively.
Here is the video from authors explaining the intuition behind the technique. You can find the notebook here.
If you find any mistakes or have suggestions, feel free! 
34 Likes
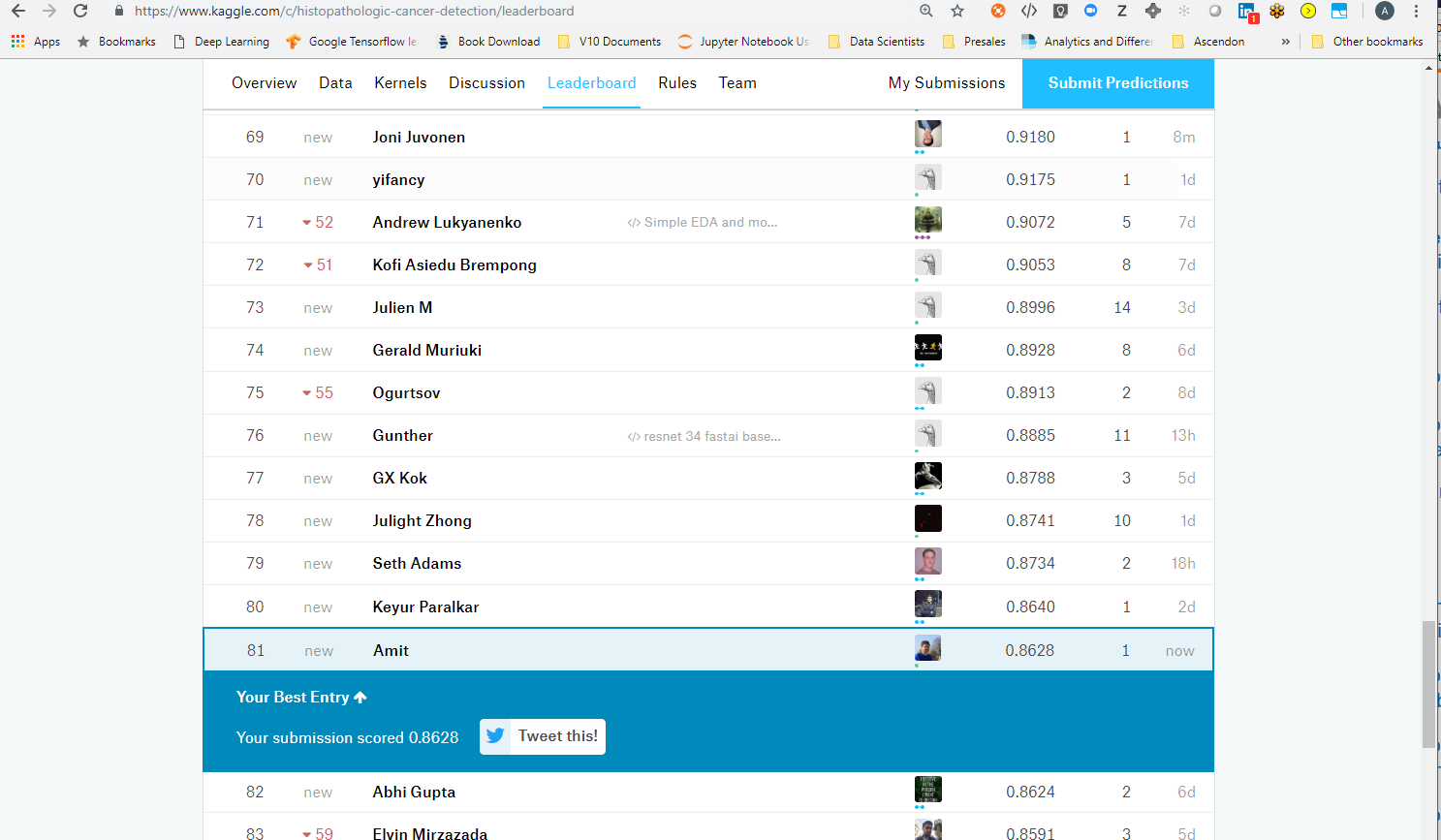
I am quite late into this arena. Have used my learning from fast.ai courses and able get rank within top 100 into the competition. I have used resent model, adaptive learning and unfreezing of selective layers. Still working on this to get into top 10…
https://www.kaggle.com/c/histopathologic-cancer-detection/leaderboard…
4 Likes
Hey everyone,
I am slowly catching up with the rest of the class. I am still on Lesson 2.
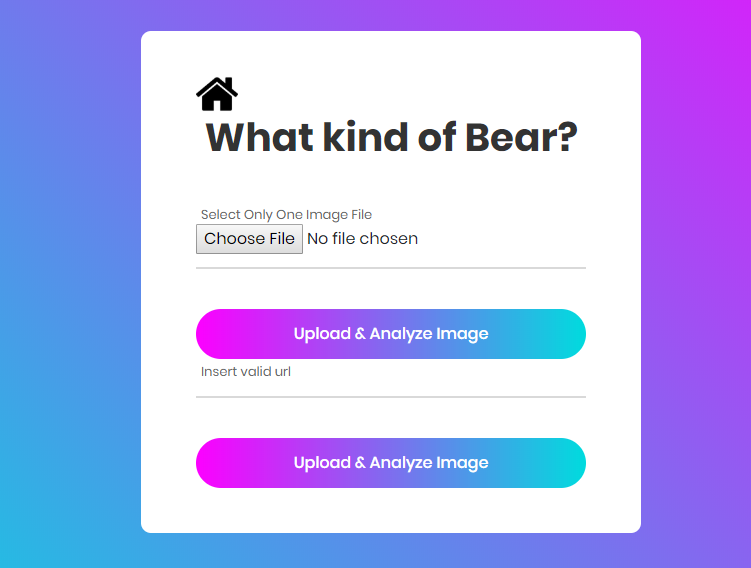
I combined Pankaj Mathur’s very nice web app layout and Simon Willison’sidea of also including the option of adding URLs and did a black/grizzly/teddy finder app.
You can check it out here:
https://which-bear.now.sh/
5 Likes