Please don’t at(@) jeremy.
It’s mentioned in many places.
If you want him to read your post, this is the worst thing you can do.
Please don’t at(@) jeremy.
It’s mentioned in many places.
If you want him to read your post, this is the worst thing you can do.
I’ll remove it. Thanks for pointing it out.
+1 wrt to the effort needed to set up the work environment and create the datasets. We can rest easy, though, knowing that we’ve started developing a full machine learning / data science skill set. That is, we can tell potential employers that we don’t need carefully curated datasets or $12k custom desktops to make valuable contributions.
At least, that’s what I keep telling myself.
Hear hear! That’s what I keep telling myself while I apply for jobs…
Hello!
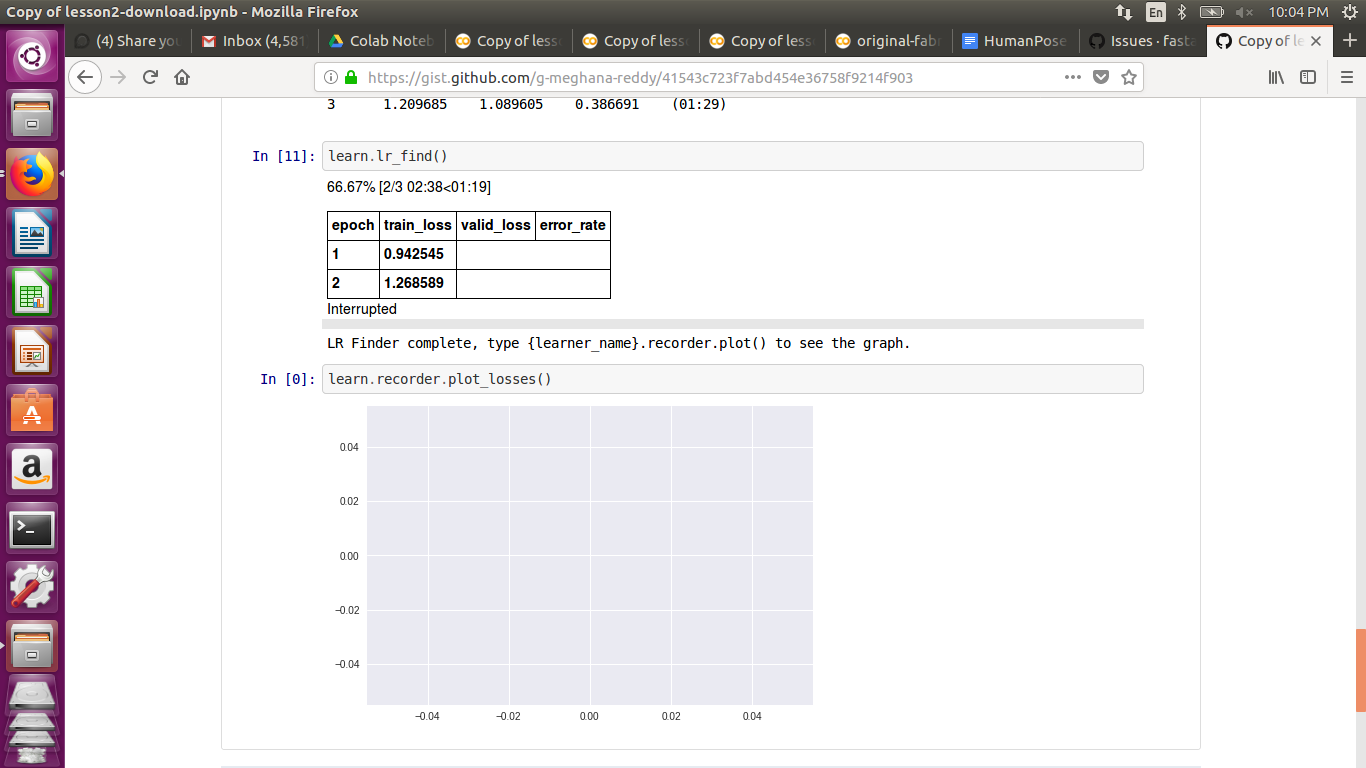
I am facing issue when I am using lr_find() in colab. It gets interrupted while running on the third epoch. It looks something like in the image. And due to this I am unable to plot losses as well.
Link to colab- https://gist.github.com/g-meghana-reddy/41543c723f7abd454e36758f9214f903
(Dataset is collected from Google images)
@Meghana_G After lr_find() you need to use learn.recorder.plot() instead of learn.recorder.plot_losses() Your learn.lr_find() can be interrupted if loss is constantly increasing. There is no point in checking more with higher learning rates if losses is already getting worse. Once it is done, you can use learn.recorder.plot() to see how it performed.
Check https://docs.fast.ai/basic_train.html#Recorder.plot and https://docs.fast.ai/basic_train.html#Recorder.plot_losses for the difference between plot and plot_losses
But in lesson 1 notebook (unmodified) also I am facing the same issue ( getting interrupted )with lr_find(), previously it was not the case.
Made a simple image classifier that can distinguish between alligators and crocodiles.
After cleaning the data a bit and playing around with the learning rate, the accuracy turned out to be 85%. Which I think is good since they’re very similar classes. The code is here https://gist.github.com/mlsmall/5f84c685267f5733a0e4882b03dfb34c.
You can test it yourself here: https://zeit-wibwuxpygu.now.sh/
If you’re using the Zeit guide to build your web app, be careful on how you name your classes. You may have to switch the class names around.
Hi, we have published all of the source including the model training notebook, model weights, inference server, and javascript face tracking.
For more info check it out:
@gokool describes how he trained the model on the large AffectNet dataset. @lauren describes how she made a high performance fastai inference server, and I describe how we increased performance by cropping the faces client-side.

The demo is still live here:
https://fastai.mollyai.com/
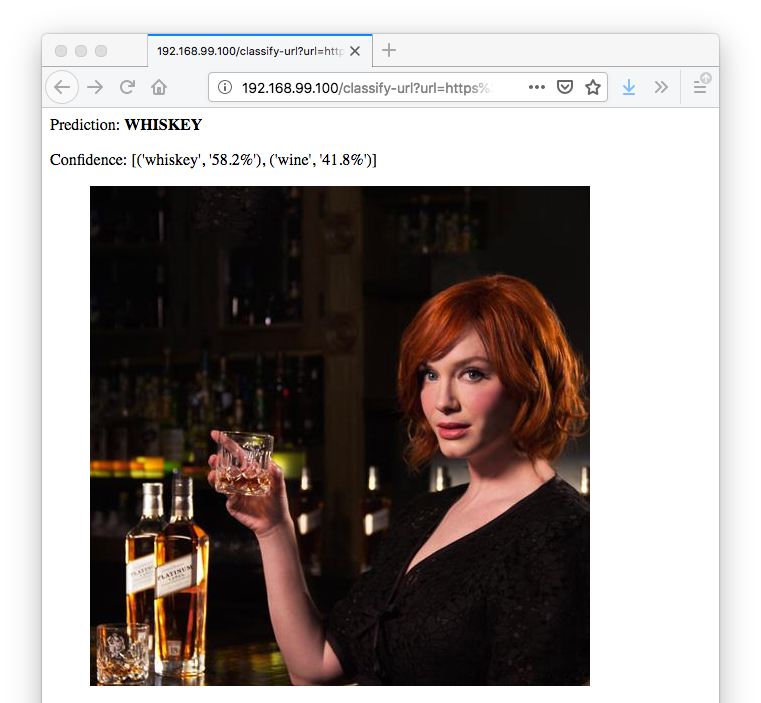
I made a simple whiskey or wine image classifier.

The classifier is quite “confident" around James Bond:
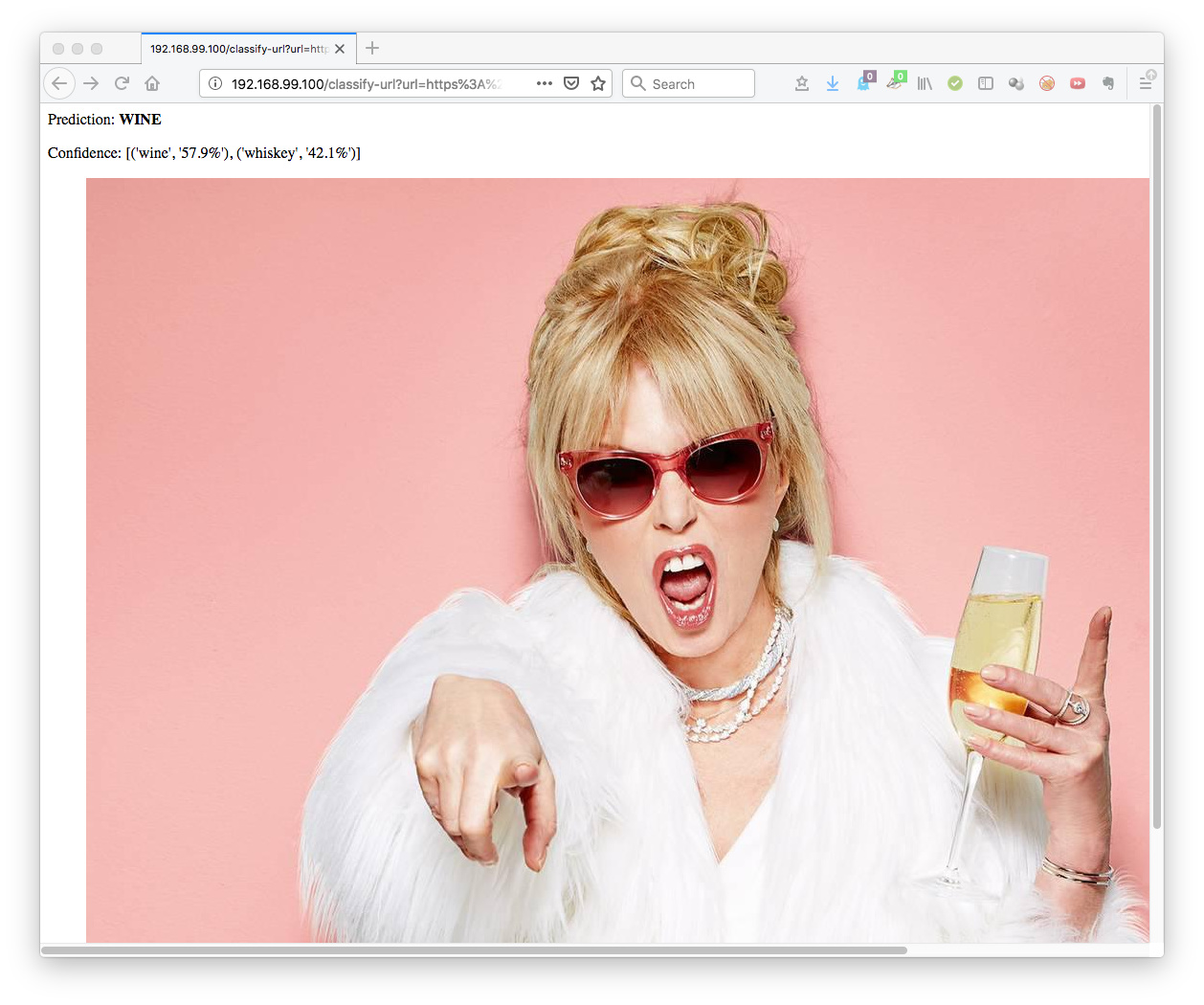
Less confident about Patsy from Absolutely Fabulous (it’s less confident but in fairness her glass might have both):
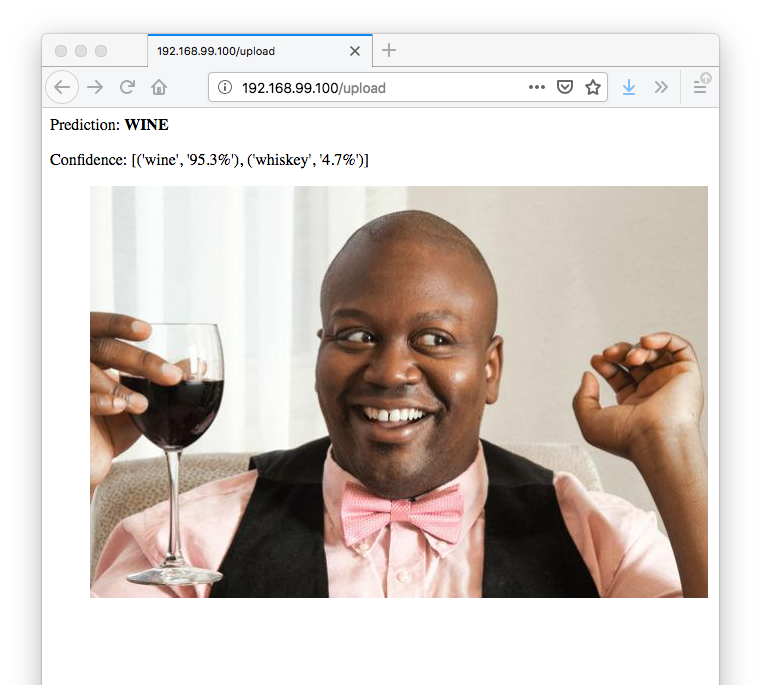
It does well as with Tituss Burgess:
The classifier is a lot less confident around Christina Hendricks:
As I feed the app more images (and let my friends play with it), it seems like what I would really want to do with images from "the wild” is to first focus in on the area of the picture that has a glass, then crop to that part of the image, and classify that cropped part. Do folks have any advice or examples for how to tackle such a step-by-step process like that (or a similar one)?
This is my work for lesson 2 and It’s my first article! much appreciated if you can give some comments 
Thx
Accuracy is about the same for resnet34 and resnet50 (no unfreezing yet):
Total time: 04:43
epoch train_loss valid_loss error_rate
1 3.811586 2.541733 0.616438 (01:13)
2 2.713833 2.102657 0.515279 (01:11)
3 2.036132 1.925441 0.484721 (01:10)
4 1.560148 1.894532 0.474183 (01:08)
Which is quite amazing for 93 mushroom classes and a noisy dataset; when looking at the wikipedia of the 15 a lot are actually not distinguishable by picture only.
Update: next to that I discovered a lot of rare subtypes get confused because dataset noise due to googling the images automatically. E.g. when looking for the ‘hairy X’ it also finds images for the ‘shaggy X’ and the ‘yellow X’.
Would be great to include this info in the app (‘probably it’s X, but it’s often confused with [the poisoned] Y’). Or to check what’s the probability someone using the app is getting ill because of a wrong prediction …
I made a classifier that differentiates between three Indian dishes: Khakra, Papad and Parantha.
This will identify whether the food is papad, khakra or parantha. These are common Indian dishes that are round, similar in colour but differ in thickness and taste.
The accuracy is 87.5%, which I think is alright given that it misclassified 4 images and trained on only 91 images. I am having some issues with deploying the webapp. Will add that here when its done. The notebook is here. PS: It’s written specifically for colab.
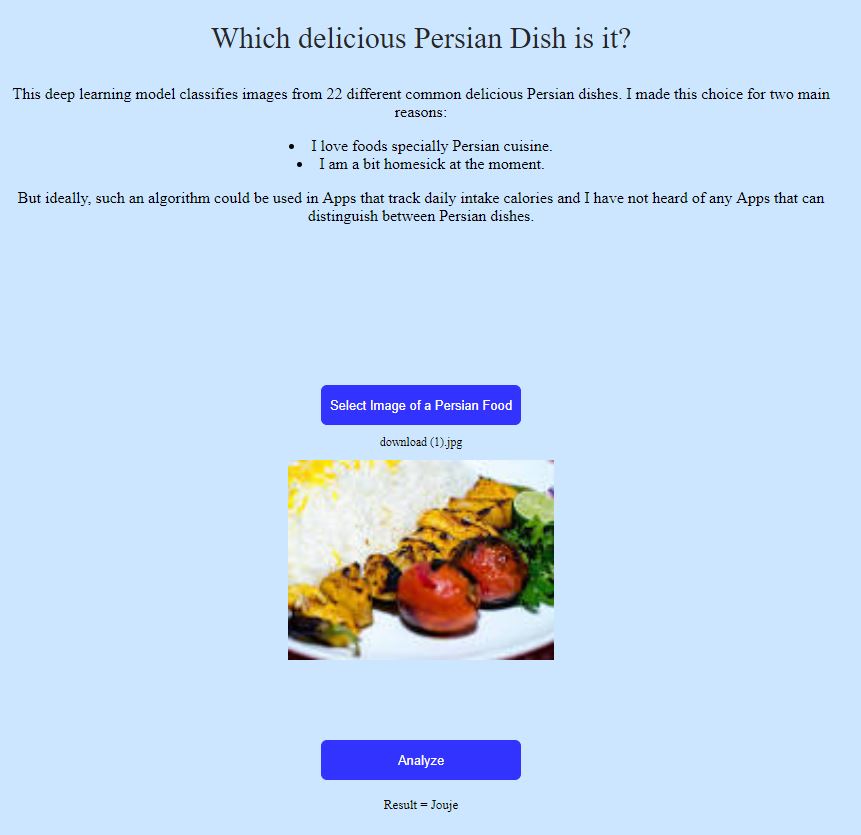
Hi all, I made a classifier for 22 different Persian dishes, using around 80 images from Google for each class. I deployed it using this guide. Thanks to @jeremy, @simonw and @navjots, It was straightforward for some like me without any background.
Here is the App: https://persiandish.now.sh/
Like @visingh, I attempted to classify architectural styles. In contrast to that effort, though, I used images retrieved from a web search using the Bing API. After obtaining the images and cleaning up the file names, the code pretty well mirrors the notebook template provided from the lesson. Accuracy ended up in the high-80%s, if I remember correctly, without much tuning. As an educational exercise, I’m pleased with it; as a real model, it would be wholly inadequate. Check out the gist here if you want.
This is great! It seems not easy to teach a machine how to tell when a person is happy or not. I’ve been working on something similar. I want to classify images of people when they are sad, happy, or angry and the best accuracy I could achieve so far is only about 68% 
Butterflies are very beautiful. I’ve often wanted to know the name of butterflies that I observe in the wild. In my home country of Malaysia there are over 1000 identified species of butterfly, each with its own distinct features and coloration. Making a classifier to help with conservation and casual identification seems like worthy project to set myself to.
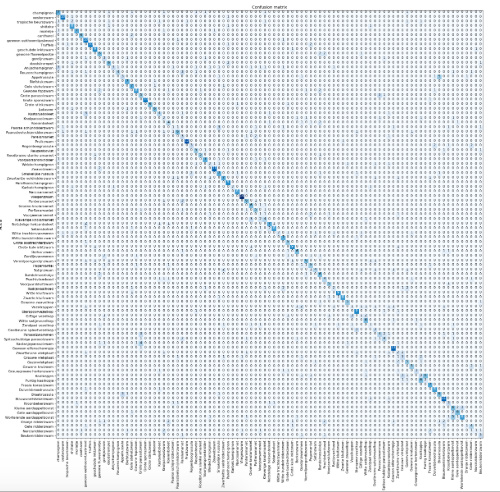
To start with, I made a classifier that identifies a butterfly by its family-rank. This also seems like a good case to benchmark the fine-grain classification capabilities of the resnet34 model, as the visual difference in features between butterfly families are extremely small.
These are the notable visual features that distinguish each of six families:
Swallowtails (Family Papilionidae): Notable for having tail-like appendages at the end of the wings
Brush-footed Butterflies (Family Nymphalidae) : The largest family of butterflies, called brush-footed for having tiny forelegs that are used as tasting appendages.
Whites and Sulphurs (Family Pieridae) : Most Pieridae have white or yellow wings with markings in black or orange.
Gossamer-winged Butterflies (Family Lycaenidae): Tiny butterflies that have wings that are often streaked with bright colours.
Metalmarks (Family Riodinidae): Wings of butterflies of this family are notable for the metallic-looking spots on the wings.
Skippers (Family Hesperiidae): Should be the easiest to differentiate, skippers have a robust thorax similar to a moth, and antennae that end with a hook.
I acquired ~200 images of examples of each family from Google Images using the wonderful little javascript tool written by @melonkernal to exclude irrelevant images and collect the image urls for my dataset.
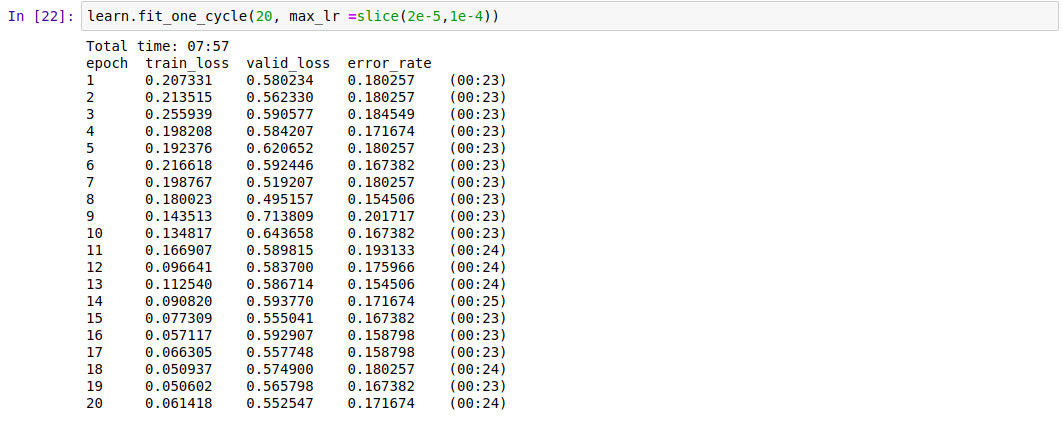
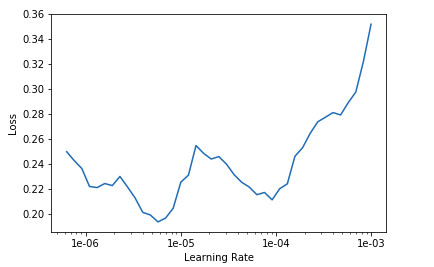
After initial training this is the plot for the learning rate:
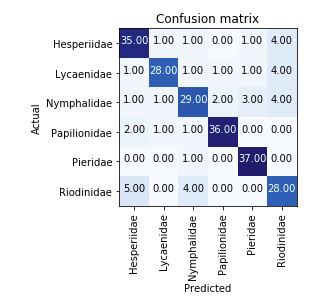
Here is training after unfreezing with the confusion matrix:
And here are the top losses:
The gist for my notebook can be found here
I deployed the app to heroku by following the example of: @simonw @nikhil_no_1
https://butterfly-family-classifier.herokuapp.com/
What I would do differently:
I’d love to hear feedback!
It’s my first time getting into fast.ai but I feel like I’ve learnt a huge amount from just working on a single problem. Thanks @jeremy @rachel for making this course available for us!
I got most of the data using search engines and listing sites. I did also use VMMRdb (which I believe sourced its data from Craigslist), but since it’s US data I only extracted the data relevant to Australia.
I used resnet50 and created an image classifier that tells you what type of martial arts someone is potentially practicing. I used the following types:
aikido
boxing
brazilian jiu jitsu
judo
muay thai
tae kwon do
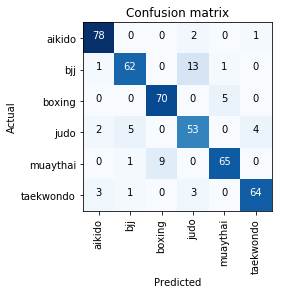
I was expecting it to have problems with bjj/judo and boxing/muay thai. The results are quite stunning.
Example inputs:
Confusion matrix:
After running lr_find, I got the following results:
Total time: 04:48
epoch train_loss valid_loss error_rate
1 0.146283 0.391842 0.142212 (00:23)
2 0.160035 0.454250 0.158014 (00:24)
3 0.182352 0.466424 0.142212 (00:24)
4 0.200035 0.458152 0.142212 (00:24)
5 0.219165 0.472904 0.148984 (00:24)
6 0.177640 0.443418 0.128668 (00:23)
7 0.146477 0.357820 0.108352 (00:24)
8 0.118247 0.382005 0.115124 (00:24)
9 0.090084 0.347515 0.108352 (00:23)
10 0.071671 0.363055 0.108352 (00:23)
11 0.057950 0.387287 0.124154 (00:23)
12 0.044172 0.372846 0.115124 (00:23)





:max_bytes(150000):strip_icc():format(webp)/18122037943_a9767be980_h-58b8e0403df78c353c24302b.jpg)
:max_bytes(150000):strip_icc():format(webp)/8971741860_0d0abb92cb_o-58b8e0395f9b58af5c9020a5.jpg)
:max_bytes(150000):strip_icc():format(webp)/14311264791_7d2aed2e6b_o-58b8e0303df78c353c242ffe.jpg)
:max_bytes(150000):strip_icc():format(webp)/8904502866_c791943364_o-58b8e0275f9b58af5c901f9c.jpg)
:max_bytes(150000):strip_icc():format(webp)/16601951821_534d393598_o-58b8e01f3df78c353c242edc.jpg)
:max_bytes(150000):strip_icc():format(webp)/GettyImages-518346597-58b8e0163df78c353c242e73.jpg)