I’ve been working this week on using fast.ai to enhance my app, Magic Sudoku, which scans and solves Sudoku puzzles and displays that solution over the top of the real one in AR.
When I made the app in 2017 (my writeup is on Medium here) I didn’t really understand how the ML part worked – I just bumbled through adapting a Keras MNIST tutorial to train my on my own dataset of scanned puzzles.
Now that I’ve been watching the fast.ai videos, I feel like I have a much better understanding of what’s going on and am starting to customize my model to do new things.
One of the things I’ve wanted to do for a while now is expand my model from 10 classes to 20 to allow it to read (and differentiate between) handwritten and computer digits. This will let me expand the capabilities of the app beyond just solving empty puzzles to letting people scan their completed puzzles to check their work and scan their in-progress puzzles to see if they are on the right track and get hints without having to look at the full solution in the back of the book (spoilers!).
So far the hardest part has been getting my new model to play nicely with Apple’s CoreML and Vision libraries. I finally got that working this weekend though and am finally seeing the results! Here’s a puzzle I scanned with my newly-improved fast.ai-trained model.
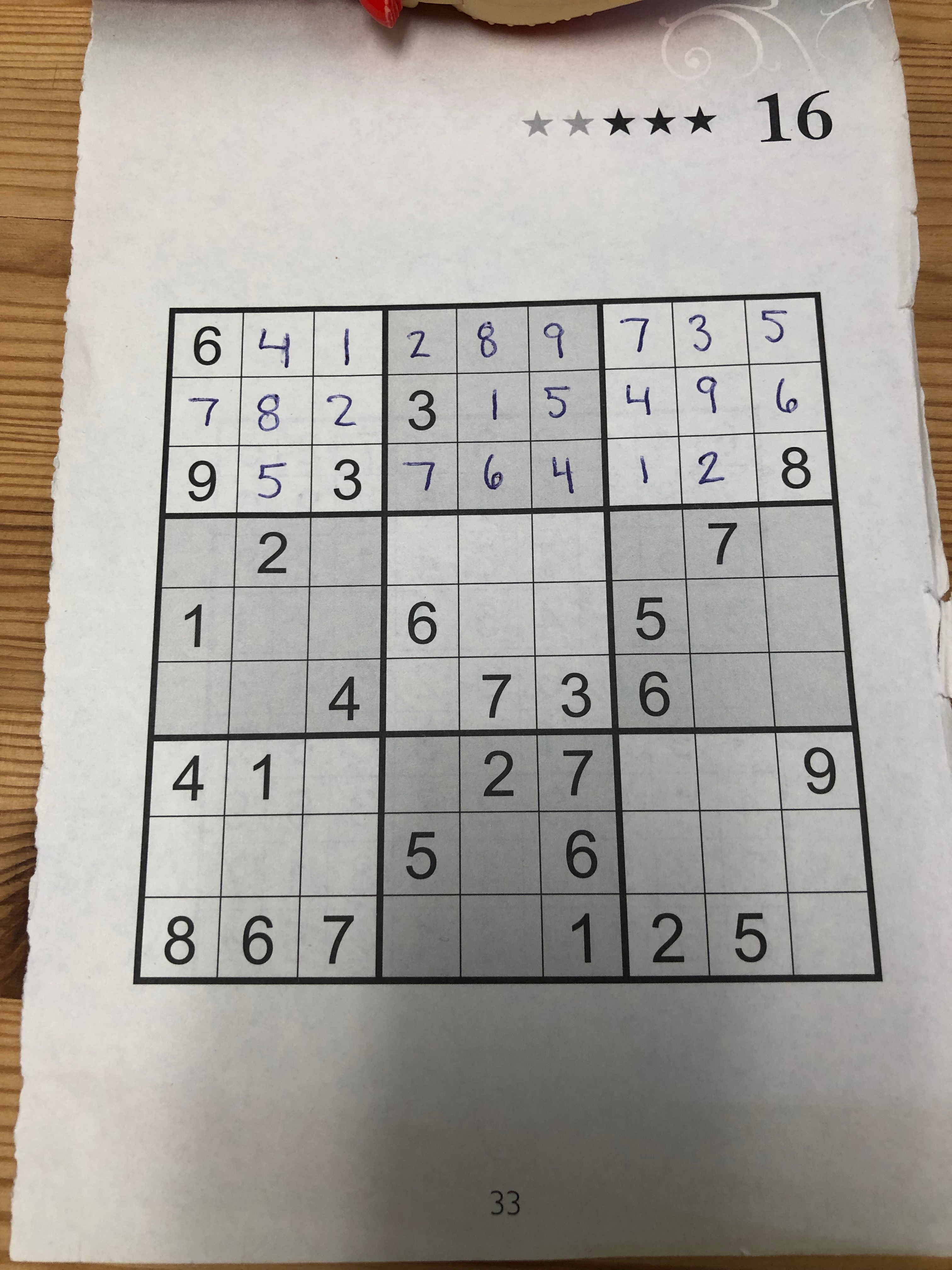

Next up on my to-do list is:
- Writing the actual app features that use the new data from the model
- Speeding up inference (right now it’s doing 1 square at a time)
- Better data augmentation (right now it’s not doing any)
- Trying other model architectures (currently using resnet34 starting from pre-trained weights but thinking that may be overkill for such small images)
- And possibly collecting more real-world data depending on how it does with some random guinea pigs’ handwriting (may end up using MNIST data in my model as well but the format is slightly different).
I’m excited to keep working on more projects with fast.ai. I’ve got about a hundred ideas… but I already know the next 2 projects I’m going to be working on this spring!