I always have to manually clean up my Whatsapp downloaded images folder because Memes and other images sit in same folder along with camera pics shared by my contatcs.
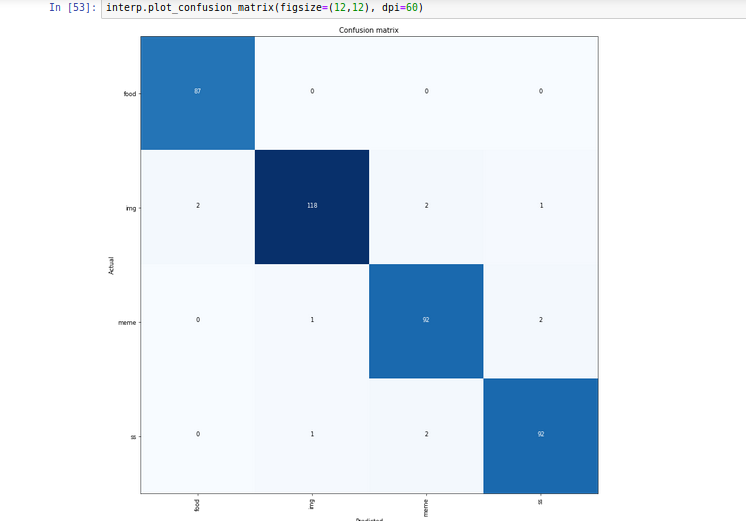
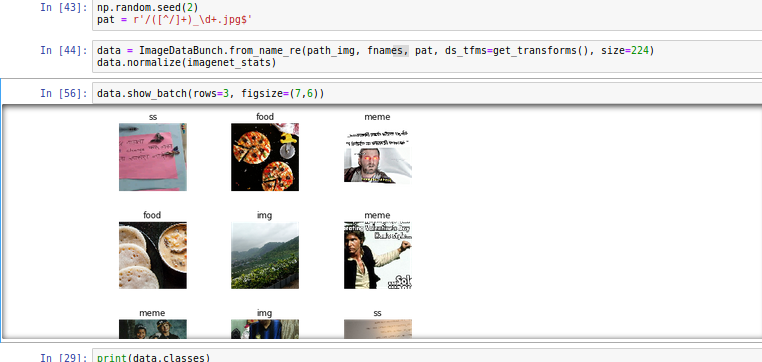
Hence i trained 34 model with 2000 images without unfreezing, 1000 manually classified images from my own Whatsapp and another 1000 sourced from google search.
I think google photos have similar model built in to remove clutter but it does not detect memes.
I am planning to have bigger dataset and testing set and see how it goes.