I created a text classifier, which is able to detect language of handwritten document based on images. Dataset contains handwritten text in four languages: Bangla , Kannada, Oriya, Persian.
Here is sample dataset:

I used the lesson 1 notebook. With resnet50, accuracy of classification is ~97%.
Here is the prediction top losses:

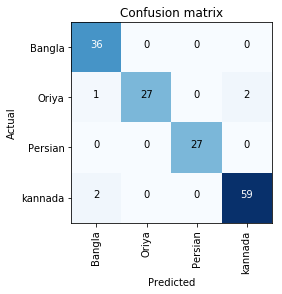
and this is confusion matrix:
I used dataset provided by authors of this paper.
Next step would be to include other Indian languages and improve the classifier.