I wanted to represent for the Caribbean programmers. So I built a classifier to classify Trinidad & Tobago Masqueraders versus regular islanders.
Here is a sample of my dataset

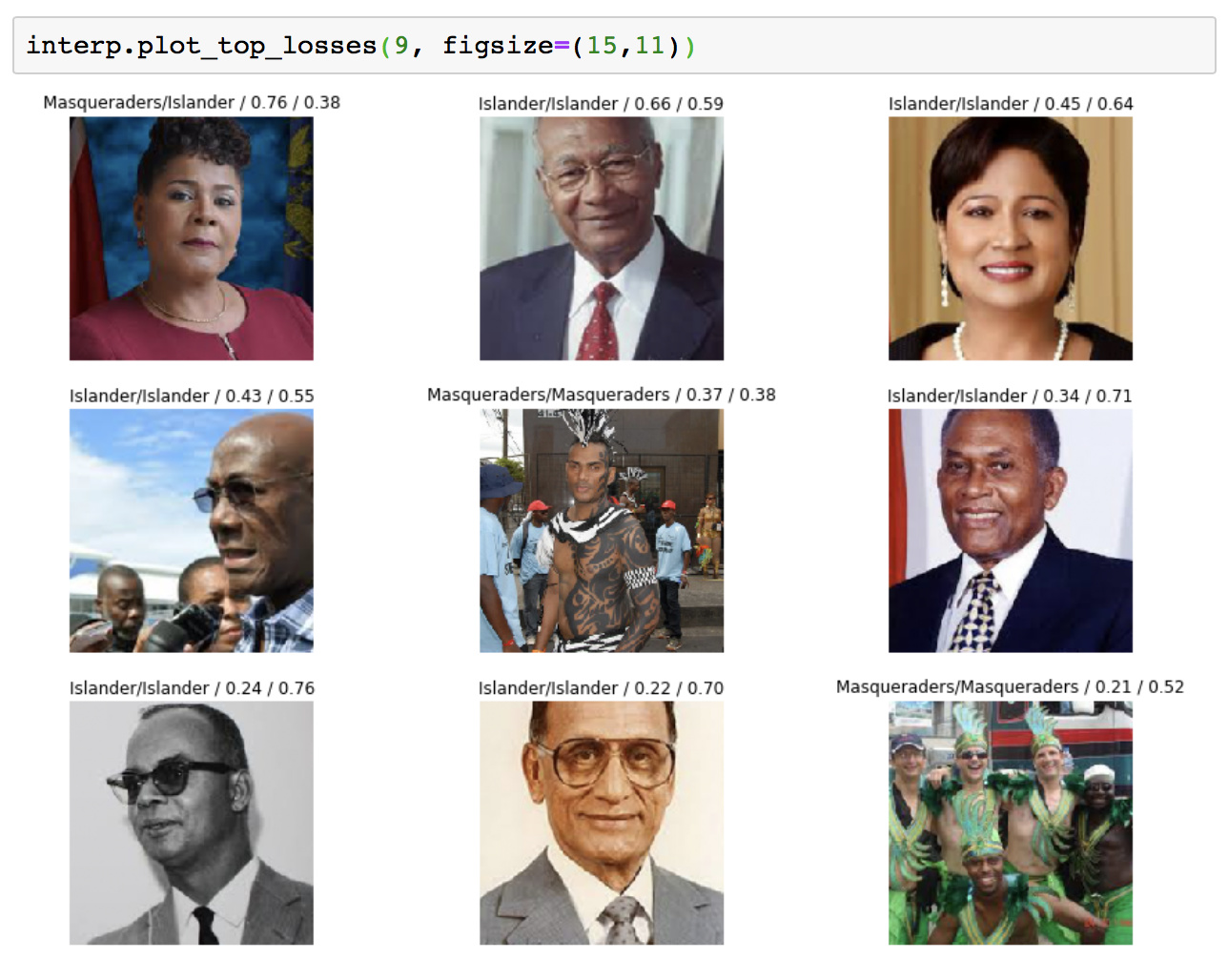
Here is a sample of my predictions
Here is my confusion matrix

Pretty decent results for a very small dataset. Notebook will be forthcoming.