Hi all,
I just wrote my first blog on building a deep learning model to distinguish pictures from 10 animated classic movies (Disney’s The Little Mermaid, Beauty and the Beast, Pocahontas, Tarzan, Mulan, Hercules Disney and Ghibli studio’s Castle In The Sky, Howl’s Moving Castle, Kiki’s Delivery Service and Princess Mononoke), including:
- Guides to extract images from movie frames
- Validation set splitting strategy
- Fastai training with Resnet50 to reach 94% accuracy
- Debugging model with Grad-CAM
- Publish it as a simple web application using Amazon Beanstalk (all thanks to @pankymathur) which also includes the Grad-CAM visualization for your uploaded image.
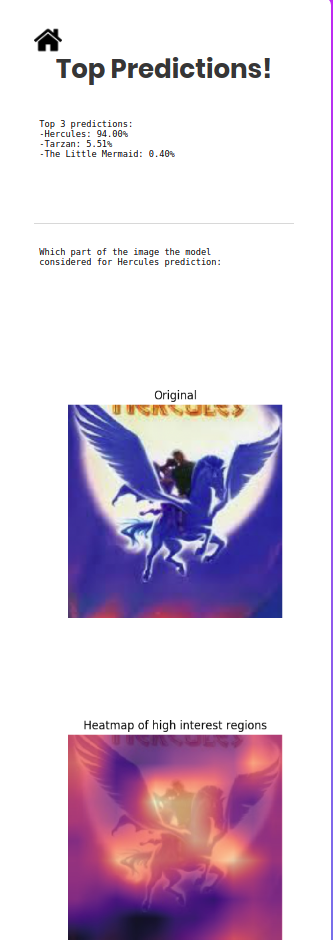
There are few interesting thing when doing this project, but perhaps the most surprising one is how well resnet model can recognize real-life image of cosplayers, even though it was trained entirely on a different data distribution (2D images from movies and black-and-white sketches).
Here are few correct predictions where model actually focuses on human faces to make decisions:

Blog post is on Medium (also on my personal site. Live demo is here. Any feedback is welcomed!