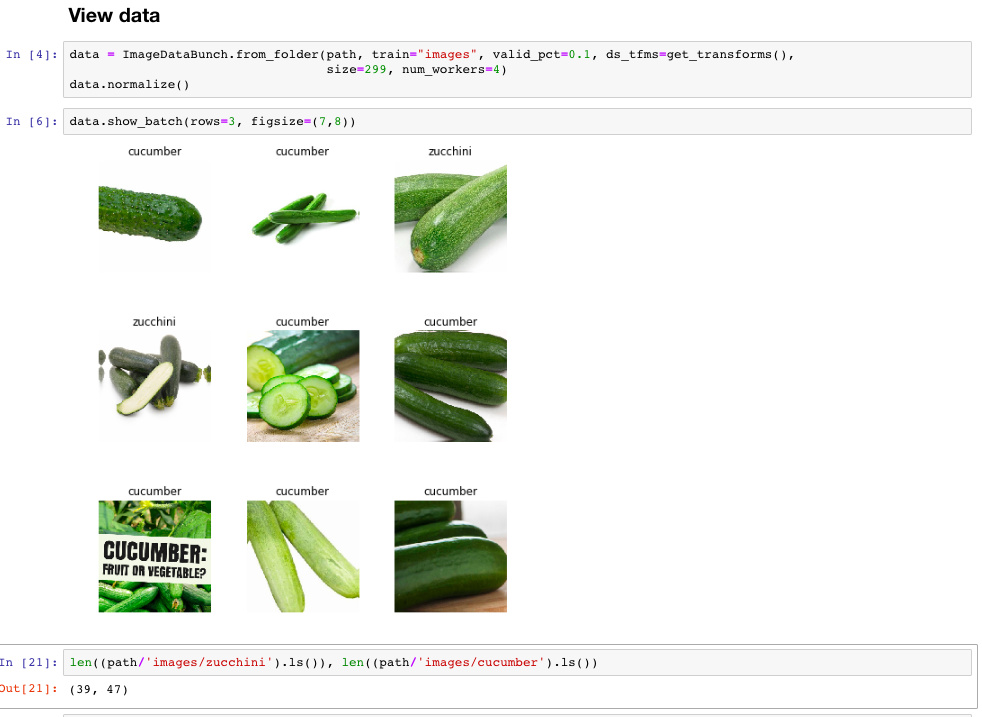
With 39 zucchinis and 47 cucumbers …
a ResNet50 with input size 299 managed to perfectly distinguish between the two on the validation set (10% of the above numbers) after 2 epochs:
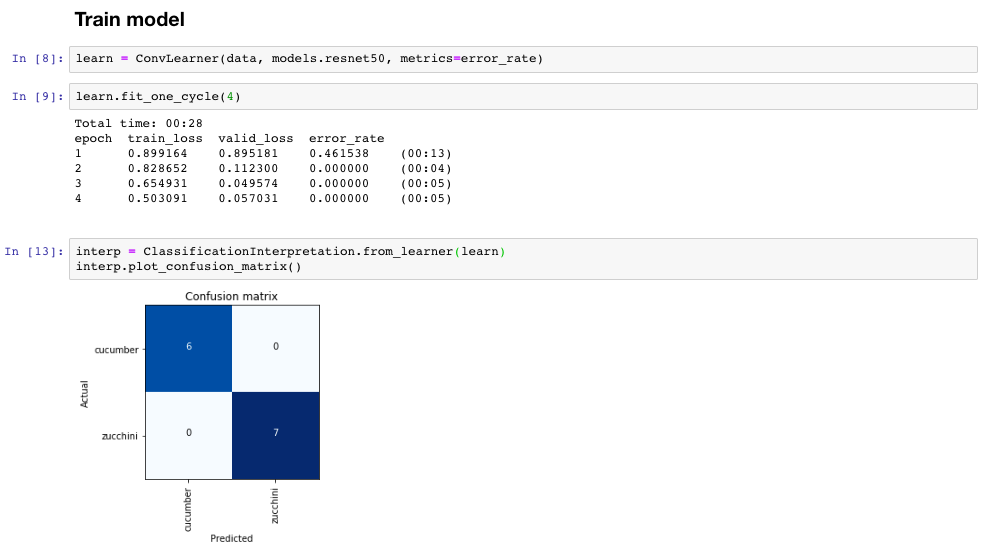
I know we must be careful when interpreting results on a validation set with 13 samples but I had a limited number images and wanted to share the results in any case. The fact that training loss >> validation loss is probably an indication that my validation set is not difficult enough.