@MagnIeeT and me are working on the audio dataset from kaggle competition and converted them into images using Fourier transform(FFT).
We performed multiple first cut experiments taking top 3, 7 more frequent classes.
We are getting ~84% accuracy on 3 classes.
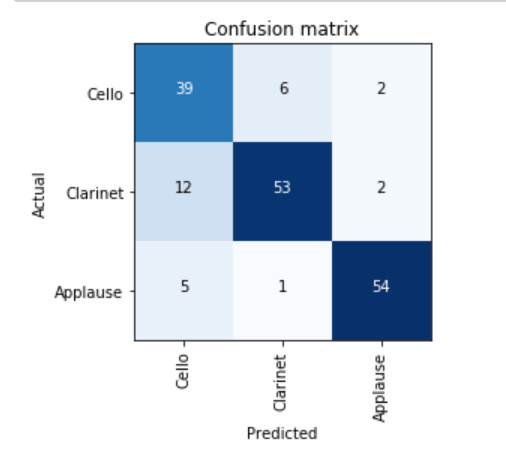
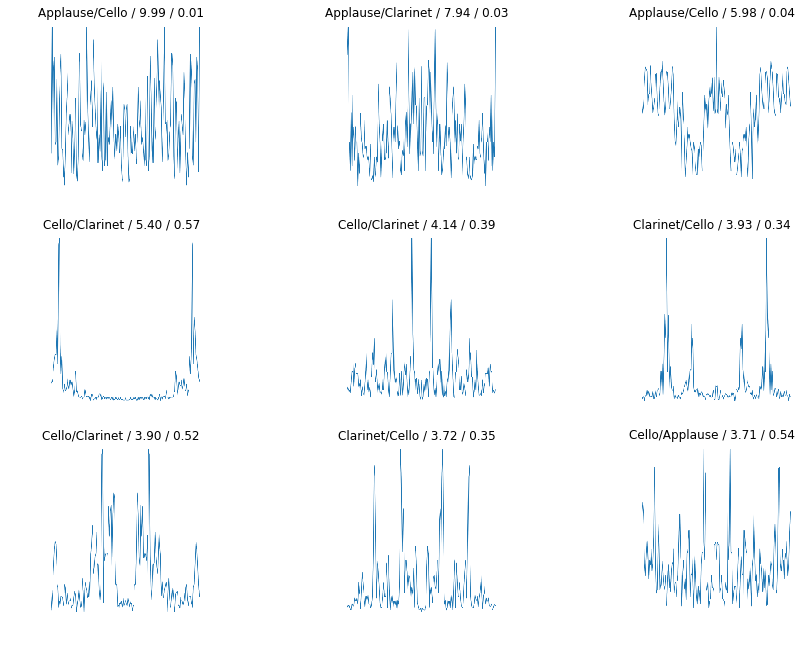
Few images of top losses(each graph is FFT of audio clip)
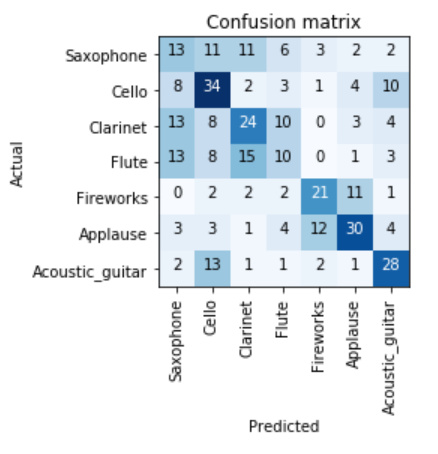
The performance degrades with increasing number of classes
Next steps will be to change how we are doing fourier transform on audio images (the sampling frequency of audio file. Window size we selected was 2 seconds, need to adjust corresponding to notes frequency). Need to test this approach on bigger datasets as our data is currently very small. Also we are planning to use spectrogram as tried by other users.
Google audio dataset is another good source providing 10 sec audio snippets. We initially planned to use but parked it for later as it is more suitable multi label classification