Downloaded the Urban Sounds database a while ago (trainingset with 5425 sounds in 10 classes (drilling, jackhammer, dog barking etc.) Converted de soundfiles (wav) into spectrograms (pictures repsesenting the sound) using the librosa package (Python).
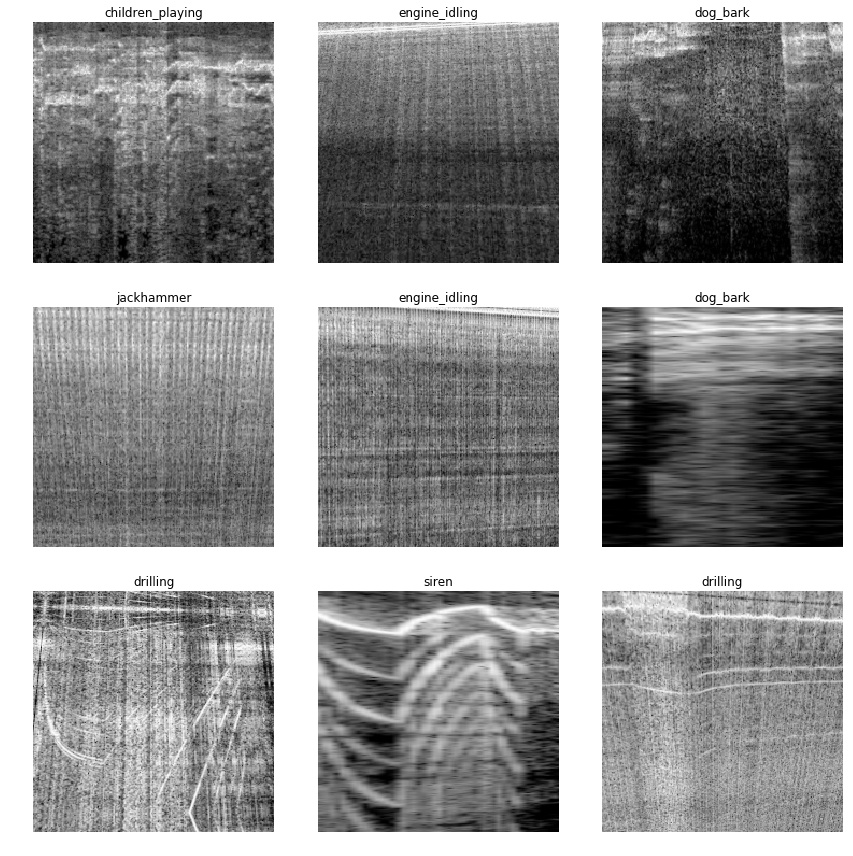
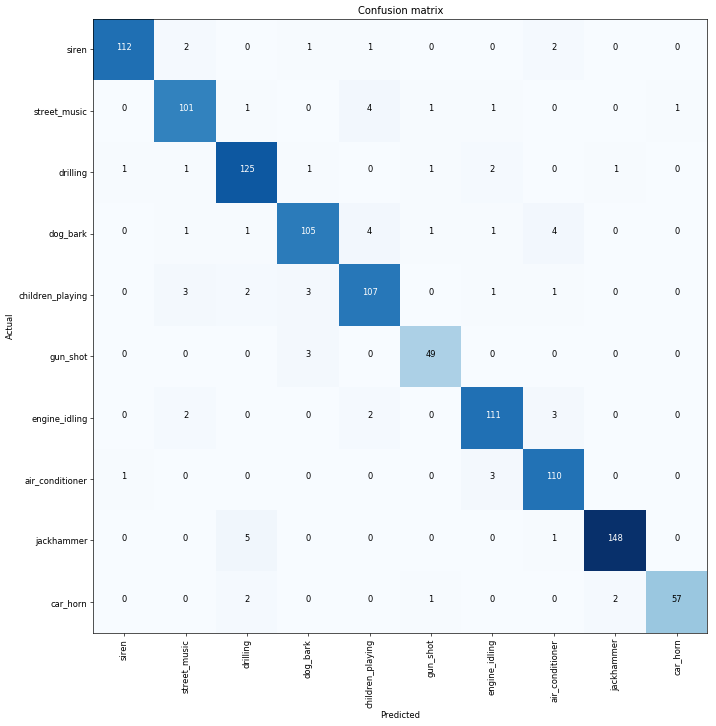
Got a 96% accuracy! on the first attempt using the code in lesson 1.
More to come!