I made this a while ago, but didn’t share it with the group because I wanted to spend a bit more time.
Skin Cancer Classifier from:

Unfortunately, the dataset is highly biased. I used the default data augmentation settings + vertical flipping to mitigate these issues. More work can be done here.
nv 67%
mel 11%
bkl 11%
bcc 5%
Other (3) 6%
get_transforms(flip_vert=True)
I had it train overnight (roughly 7 hours) on resnet-50.
End results:
epoch train_loss valid_loss error_rate
496 0.003147 0.519515 0.074888 (00:50)
497 0.000316 0.526893 0.071892 (00:51)
498 0.000188 0.516914 0.071393 (00:51)
499 0.000186 0.522218 0.072391 (00:50)
500 0.000057 0.522059 0.072891 (00:50)
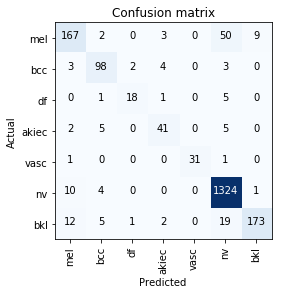
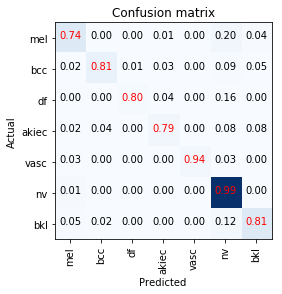
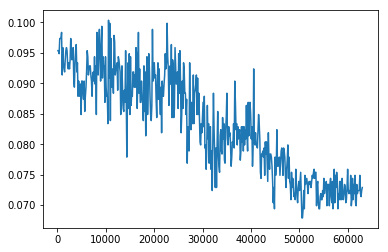
92.7% accuracy, the highest I could find in the kaggle kernels was around 78% accuracy.
You can see the error rates dropping after a while as fit_one_cycle adjusts over time.
End results confusion matrix: