Upgraded UCR Time Series Classification to image notebook
I’d like to share with you changes I’ve made to the OliveOil notebook I originally created based on some of the feedback received.
I’ve made the following updates gist:
- Modified data source so that any of the 85 univariate UCD data sets can be used now
- Added 3 new time series encoders
- Modified the time series to image encoders so that images of different sizes can be created, independently of the time series length
- Up to 3 encoder can be simultaneously used. Each encoder creates a single channel image, and a 3 channel image is created by combining them.
- Incorporated the new data_block functionality
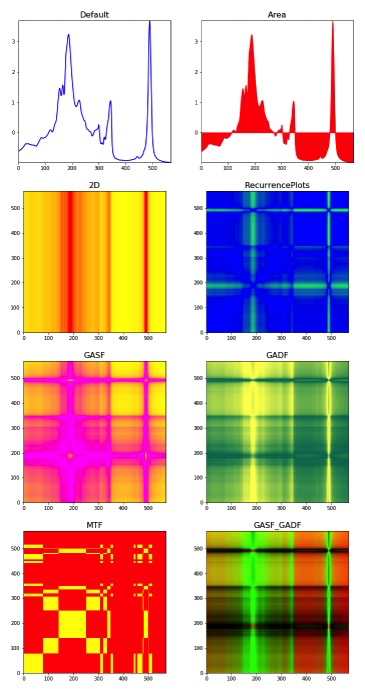
There are 7 image encoders available:
- ’Default’: raw time series
- ’Area’: time series area plot
- ’2D’: time series in 2D
- RecurrencePlots: Recurrence Plot
- GASF: Gramian Angular Summation Field
- GADF: Gramian Angular Difference Field
- MTF: Markov Transition Field
This is how the same time series would look like after an encoder is applied:
I’ve run many tests with this updated notebook. If you are interested, you can read the key learnings in the Time series/sequential data study group thread.