I used facial keypoint detection dataset from kaggle. (CNN+regression)
It’s a challenging problem. Mainly for two reasons.
- Only 1/3 of the training images have data of all the 15 facial keypoints.
- And, most of them are erroneous (see below).
As you can see, the training data is not very accurate.

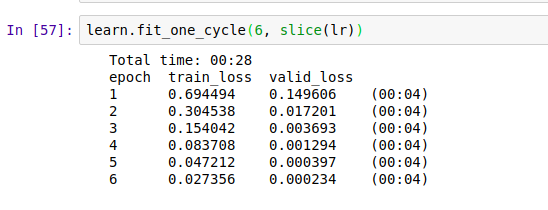
Rmse Loss
Predictions

What I learnt…
- The dataset was created using some software, or maybe a camera/device that gives out these key points. Whatever maybe, there must be a underlying mathematical model(fn) for that (camera/device/software). So, that’s what the neural network is trying to approximate, instead of the finding the actual key points. What I mean to say is, here the neural network is not trying to find exactly where is the mouth, eyes or nose; because we haven’t explicitly mentioned it in our dataset. Yoshua Bengio and team created this dataset, I would like to know if there was any intention of such sorts.
- if that’s the case, even if we predict the actual facial keypoints for the test set, we can expect a higher error.
Also, I have re-structured the original dataset into jpeg images. https://www.kaggle.com/sharwon/facialkeypointsdetectionimg. I think this will be helpful for beginners.
Notebook is still a work in progress. I’ll share a clean version soon.
Also, The submission file is a bit weird. I’m not sure why they are not evaluating on the basis of all the points.
To do:
- Clean the notebook.
- Submit to the competition.
- Use the whole data for training.