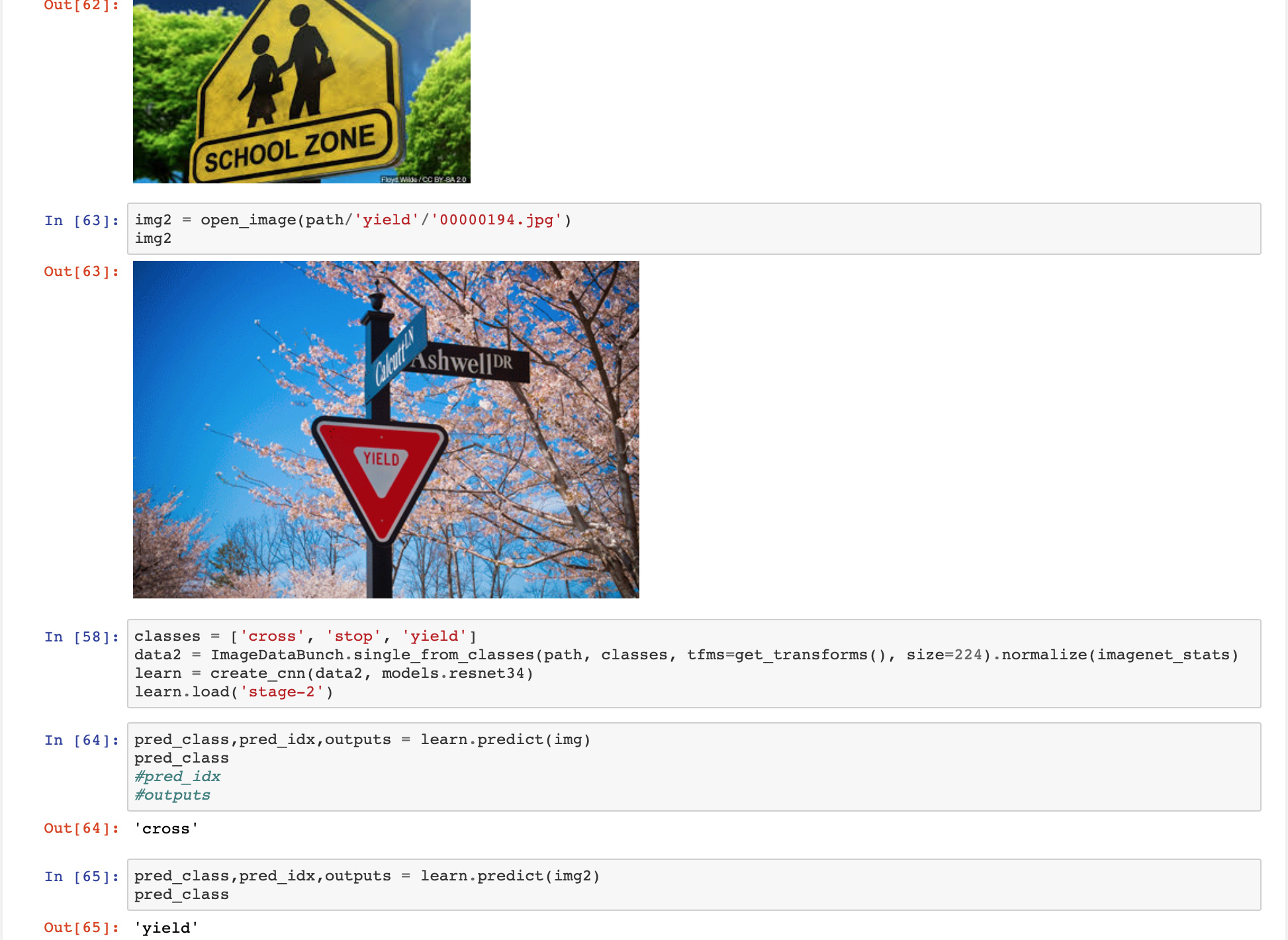
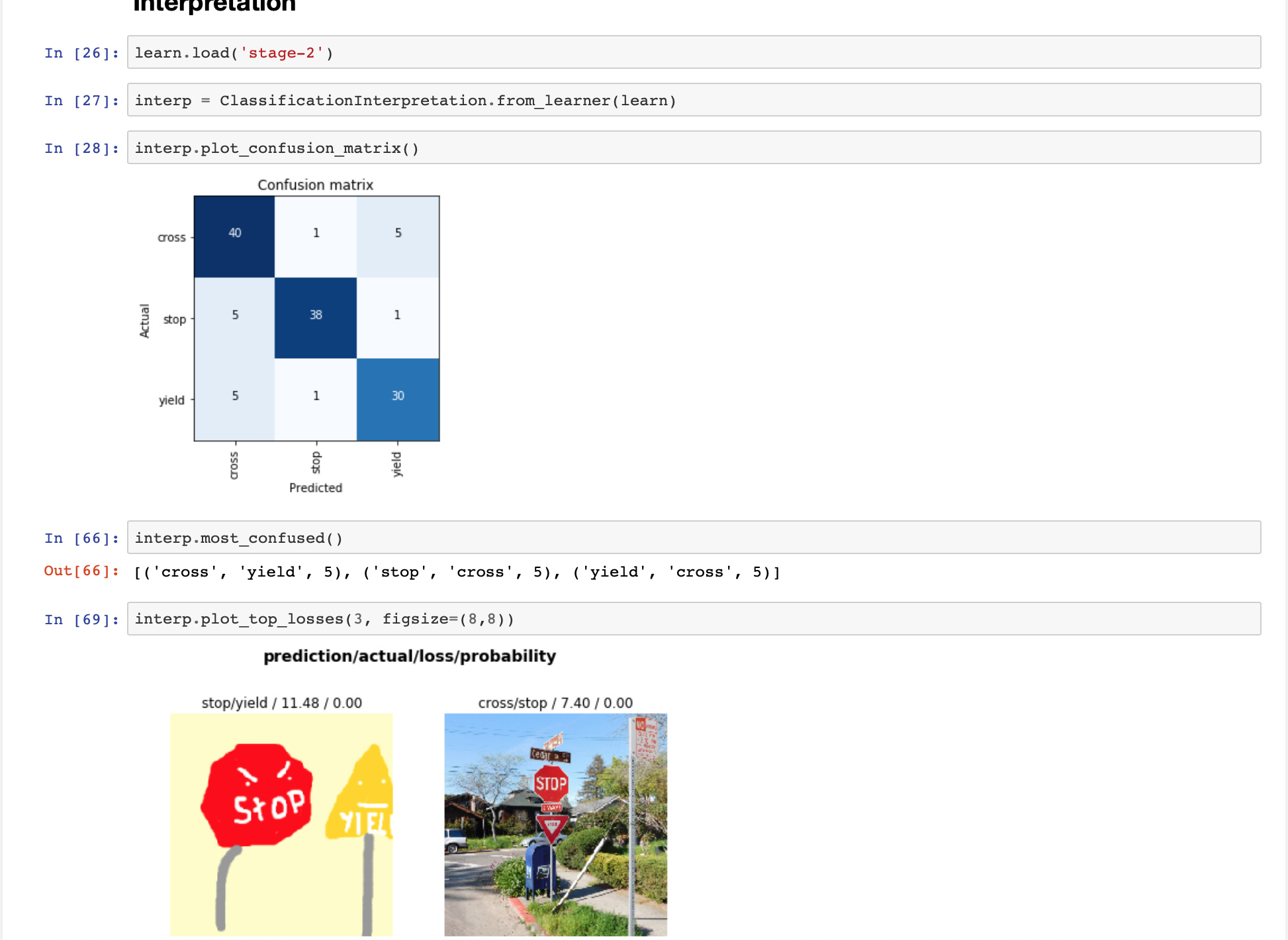
Created the image classification to classify stop, yield and school crossing; Here is the snapshot of my notebook. Need to clean up the date to get more accuracy - currently getting 14% error.
My Input data from google image

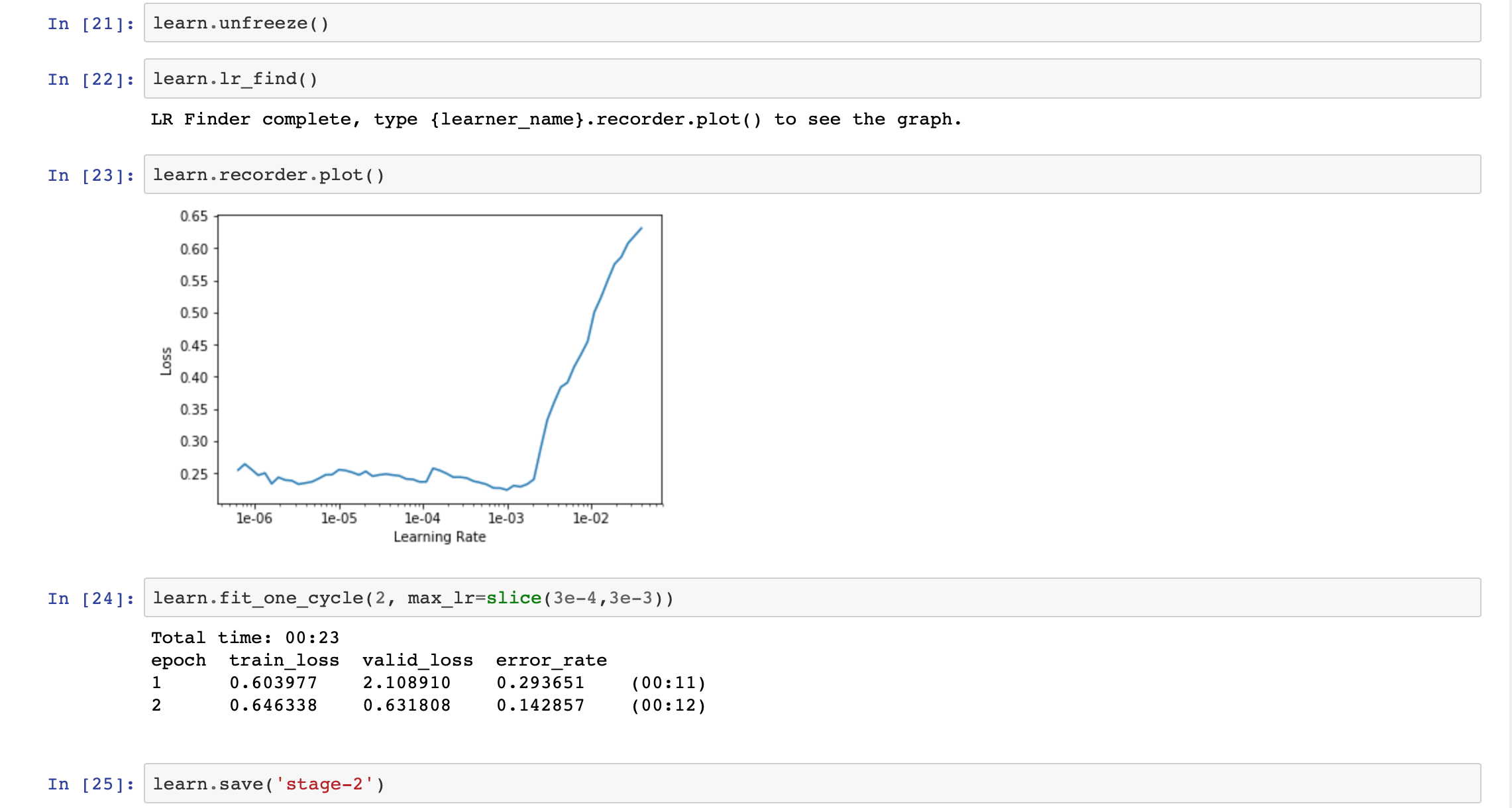
Train model/rate
Inference - pretty cool