
National Congress of Brazil (Senate and Chamber of Deputies building)
Senators Facial Recognition with deep learning Fastai v1
I work at the Federal Senate of Brazil (above, a photo of my portfolio, photography is one of my hobbies) and I decided to create an image classification model to do the facial recognition of the 80 senators of the year 2017.
The dataset, created by Fabrício Santana, has a total of 10,000 public images of the senators. Each image has only one senator on it and the photos were cropped to get only their faces as shown below. The classes are unbalanced because some senators have more photos than others. For example, senator Aécio Neves has 325 pictures while senator Maria do Carmo got only 24. For the training phase I used 8,000 images and separated 2,000 images for the the model validation.
I got a fantastic accuracy of 99.3% using Resnet34 pre-trained model with the new fast.ai version. I did a similar model with the previous fastai version and I got 98,2% accuracy. It´s good to see that the fastai library is always getting better and better.
Among many applications, this model could be used to automatically label photos of the Social Media Department, streamlining and facilitating the work of photographers and reporters who do the journalistic coverage every day. It would also be possible to automatically register the presence of parliamentarians in committee and plenary sessions.
Let’s take a look at the code (notebook is available here: https://github.com/Nandobr/Fastai_v1/blob/master/eu_senators.ipynb
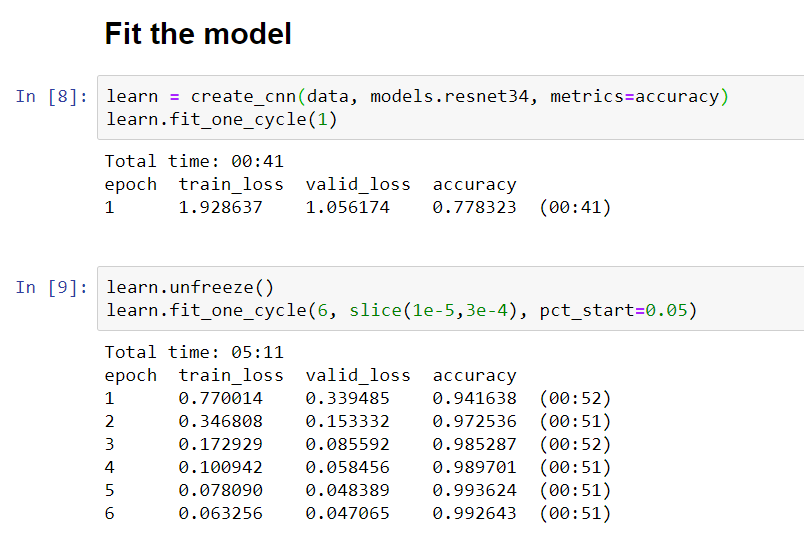
These are the numbers while fitting the model:
Here are some images examples:

At the end, it is always interesting to print a confusion matrix:
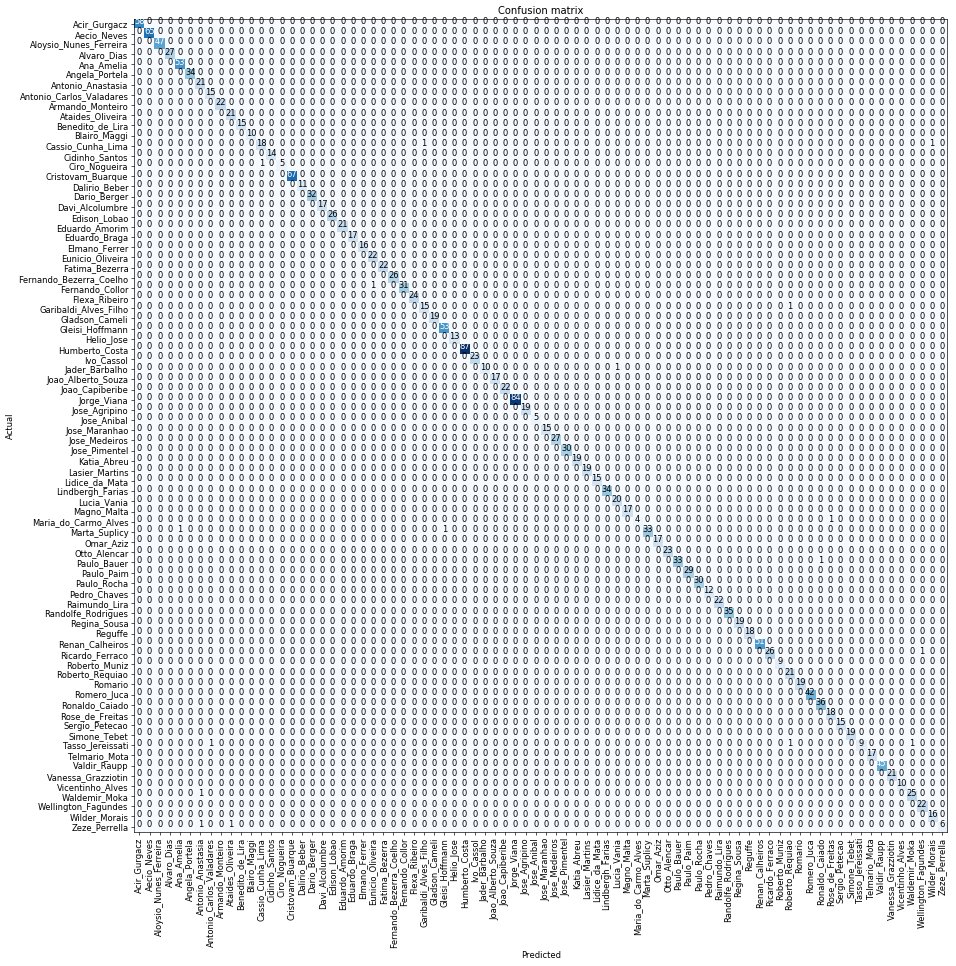
As next steps, I intend to publish an article in Medium and put an image classification application into production.
Finally, I’m glad to mention that our study group in Brasília, where I’m one of the organizers, is the biggest group of International Fellowship Students in Latin America. Thanks Jeremy, Rachel and all Fastai team for this opportunity!
Fernando Melo,
Twitter: https://twitter.com/Fmelobr
linkedIn: https://www.linkedin.com/in/fernando-melo-a6909720/