This is wonderful! ![]()
2 Likes
Great discovery. Here’s some useful info on that topic - hope it helps:
3 Likes
Just wanted to share my small contribution to the library. When I’ve tried to classify larger dataset (80k images, 340 classes) I got a memory-related error caused by underlying pytorch function call. I’ve introduced a new parameter that allows to overcome this obstacle: https://docs.fast.ai/vision.learner.html#Working-with-large-dataset
8 Likes
Hi everyone,
Instead of doing the Lesson2 homework-which was trying web deployment of a model, we- a few members of the Fast.ai Asia Virtual study group are trying building a mobile app (everything to run on the phone) : “Another Not Hotdog” app, but using PyTorch.
I’ve introduced the complete plan in a blogpost here.
@cedric has already created the framework needed for majority of the steps needed for step 2,3 mentioned in the blogpost.
You can find the Fast.ai camera repository Here.
Here’s a little video demo:
I’ll be thankful for any feedback.
Best Regards,
Sanyam
32 Likes
Then should we stop using ImageDataBunch.from_folder(...,valid_pct=0.4,..) ? Because I too might be having the same problem as henripal, it is giving as good as 95.6% accuracy on my native language character recognition of 84 classes with characters having sidebars and loops (which might be the State of the Art, I have to check more rigorously though), but guess what val_loss > train_loss; could this might be the reason my model is still underfitting? I’ve tried tinkering with lr, turned out it was fine, increased the epochs to as high as 10, which brought marginal improvements (bringing down the loss difference from 0.05 to 0.02 ) but now is taking 5 hours to train in colab.
Wrote up a blog post drawing on some ideas from lessons 1 and 2.
Appreciate feedback, comments. Also, more concerned if I’m revealing too much of the course material or not crediting properly.
1 Like
No, that’s not what the blog post says. Take a deeper look and tell us what you find! ![]()
PKrs_currency
Pakistan currency classification using deep learning, The model achieved a classification accuracy of 98.5%.
Python Notebook for training on this dataset
The link to gist of the PKRS_Classifier.ipynb
The link to github PKRS_Classifier.ipynb
This code is based on code from a fast.ai MOOC that will be publicly available in Jan 2019.
Dataset
I wanted to see how accurate a Neural Network would be at categorising images of currency. Being a resident of Pakistan i wanted to train it on the Pakistnai Rupee but a quick google search discovered that there were very little camera images of the different Pakistani notes on the internet so i created the dataset myself.
The different bank notes in the dataset are as following :
I took the 6 images below from this blog post, images in the dataset are my own.






Creation of Dataset
The first step was to find as many currency notes as i could, everyone in the family lent me their riches for science!
I then took pictures of all the notes and divided them in train and validation set, the distribution of the dataset is as following :
| Category | Train | Valid | Total |
|---|---|---|---|
| ten | 101 | 44 | 145 |
| twenty | 12 | 6 | 20 |
| fifty | 15 | 7 | 22 |
| hundred | 14 | 6 | 20 |
| five_hundred | 2 | 2 | 4 |
| Thousand | 5 | 3 | 8 |
| TOTAL | 149 | 68 | 217 |
| Percentage | 68.7% | 31.3% | 100% |
The data was distributed into a dataset directory structure as shown below:

4 Likes
Cool project @G_M! Kinda interesting what happened with your errors and accuracy after unfreezing. It looks like the model started to overfit quite a bit (epochs 8 to 13) and then corrected and stopped overfitting?
Did you try training for fewer epochs before unfreezing and then unfreeze and train to see if that gives better results? I’d be interested to see if that gives you anything noticeably different.
1 Like
Thank you @prratek
I am not sure why that is , maybe because after unfreezing the learning rate for the starting layers of the network is 1e-5 which is maybe very low that results in the weights to be adjusted slowly, the first 8 epochs were not able to change the weights of the starting layers that much and hence the effect of them changing occurred after the 8th epoch and then by the 13th epoch the gradient decent had changed the weight’s enough in the right direction to start improving the accuracy again. I am just guessing here ![]()
I have not tried that but it sounds interesting and i will try that. I am not sure what effect that might have.
Definitely one of the more meaningful things to do with the whole family savings. 
3 Likes
No one is willing to give me all their money when i ask them, i don’t know why though 
They eventually come around to the idea.
1 Like
OK. Now I think get what the post says, it argues why cross validation is dangerous, and why the validation data must consist data that the model has never seen during training .It acts like a conceptual question to test whether the net is memorising the answers or not, and more conceptual question the better. For my dataset on my native alphabet recognition, the validation set should consist of characters written by people whose handwritten characters is not in the training set.
I guess I am right this time 
I found this really useful (and fun). Here is an adapted notebook that just runs until the loss is less than 0.1. A learning rate of 0.7 can need only 9 epochs; 0.01 closer to 800!
4 Likes

National Congress of Brazil (Senate and Chamber of Deputies building)
Senators Facial Recognition with deep learning Fastai v1
I work at the Federal Senate of Brazil (above, a photo of my portfolio, photography is one of my hobbies) and I decided to create an image classification model to do the facial recognition of the 80 senators of the year 2017.
The dataset, created by Fabrício Santana, has a total of 10,000 public images of the senators. Each image has only one senator on it and the photos were cropped to get only their faces as shown below. The classes are unbalanced because some senators have more photos than others. For example, senator Aécio Neves has 325 pictures while senator Maria do Carmo got only 24. For the training phase I used 8,000 images and separated 2,000 images for the the model validation.
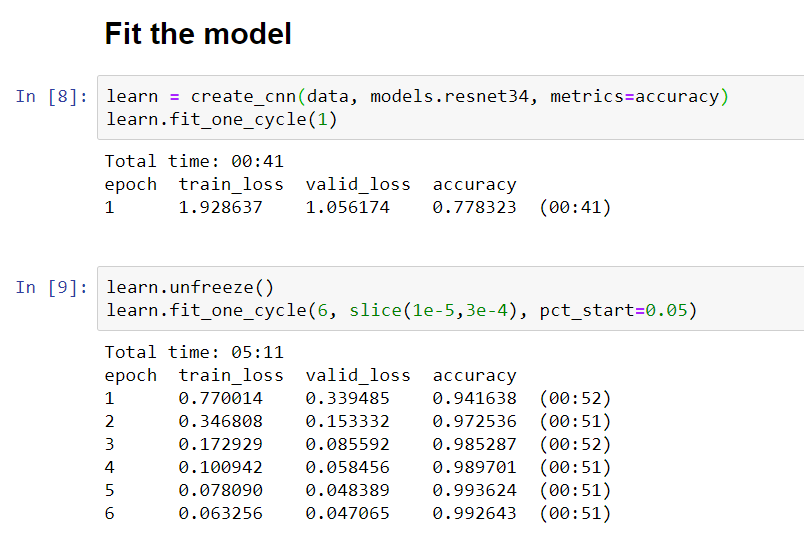
I got a fantastic accuracy of 99.3% using Resnet34 pre-trained model with the new fast.ai version. I did a similar model with the previous fastai version and I got 98,2% accuracy. It´s good to see that the fastai library is always getting better and better.
Among many applications, this model could be used to automatically label photos of the Social Media Department, streamlining and facilitating the work of photographers and reporters who do the journalistic coverage every day. It would also be possible to automatically register the presence of parliamentarians in committee and plenary sessions.
Let’s take a look at the code (notebook is available here: https://github.com/Nandobr/Fastai_v1/blob/master/eu_senators.ipynb
These are the numbers while fitting the model:
Here are some images examples:

At the end, it is always interesting to print a confusion matrix:
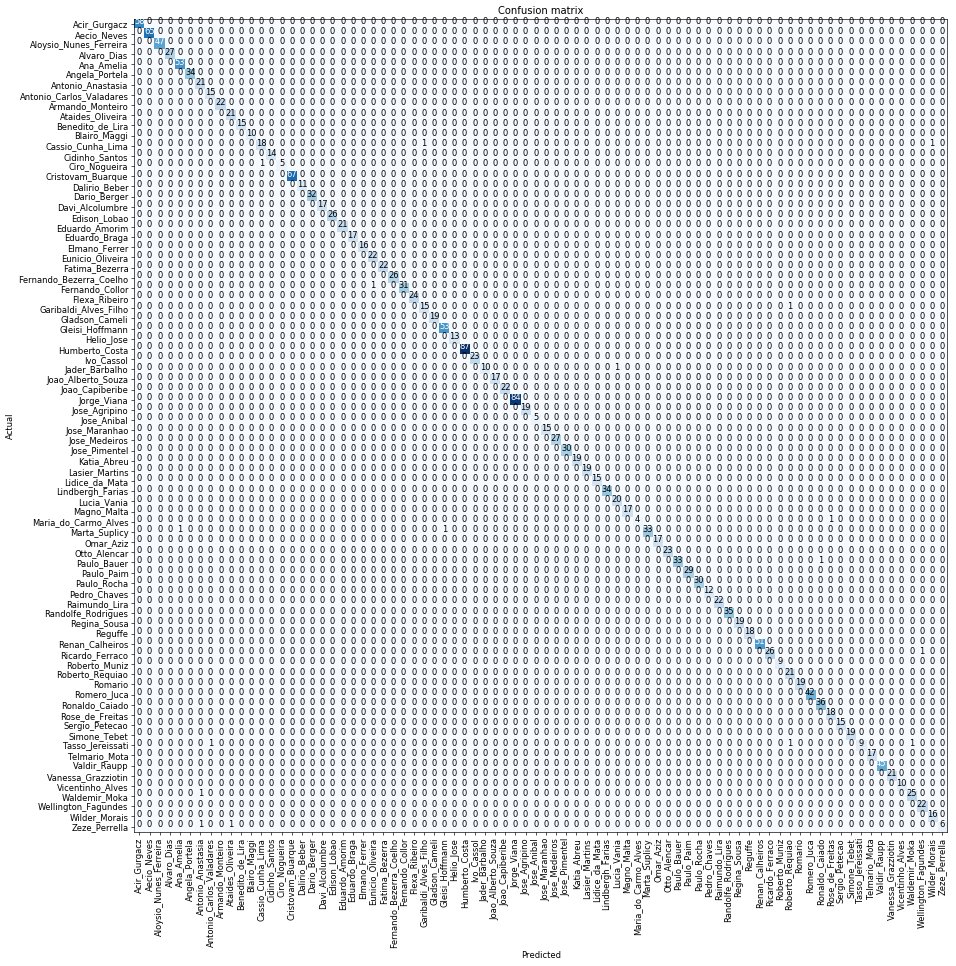
As next steps, I intend to publish an article in Medium and put an image classification application into production.
Finally, I’m glad to mention that our study group in Brasília, where I’m one of the organizers, is the biggest group of International Fellowship Students in Latin America. Thanks Jeremy, Rachel and all Fastai team for this opportunity!
Fernando Melo,
Twitter: https://twitter.com/Fmelobr
linkedIn: https://www.linkedin.com/in/fernando-melo-a6909720/
16 Likes
Hey that’s cool. Did you have much trouble getting the model converted to onnx? Really curious if you’re able to go from onnx to CoreML on iOS!
1 Like
I was also thinking about grey scale images.
in RGB we have three channels 1
in Greyscale, we have 1 channel
Should we do something different in Greyscale images ?
Michal
1 Like
This is really cool. I was wondering if visualising the layers show what makes the countries distinctly them!
2 Likes
I am playing with the download_image.ipynb. I have write some script to automatically scrape Google Image by passing a dictionary of search list instead of manually typing in Google.
I have encounter some problem and would love some help:
- The download_images progress bar often stuck at 99%, I am not sure why. I have to use max_worker=None to avoid this but it is also much slower as a result.
- I love the little JS script from @lesscomfortable to scrape Google Image. But I want to do this in Python script. I use request to get html from Google Image, it does not get as much image as manually scrolling down and press the “show more result” button, I am not proficient at web scraping, would love some help here how can I mimic a web browser and doing these scrolling and pressing work for me with python script.
You could “triplicate” the 1 channel, to get a “pseudo” colour image.
2 Likes