Hey Guys, I decided to work with Architectural Heritage Elements image Dataset dataset. And I think have achieved something better than SOTA for this dataset. The authors claim 93.19% whereas I achieve 97.155% with Restnet50 after some finetuning. There is a lot of further potential for finetuning I think.
Link to the paper i am currently comparing my results to. not sure if there are any further papers on this improving their results.
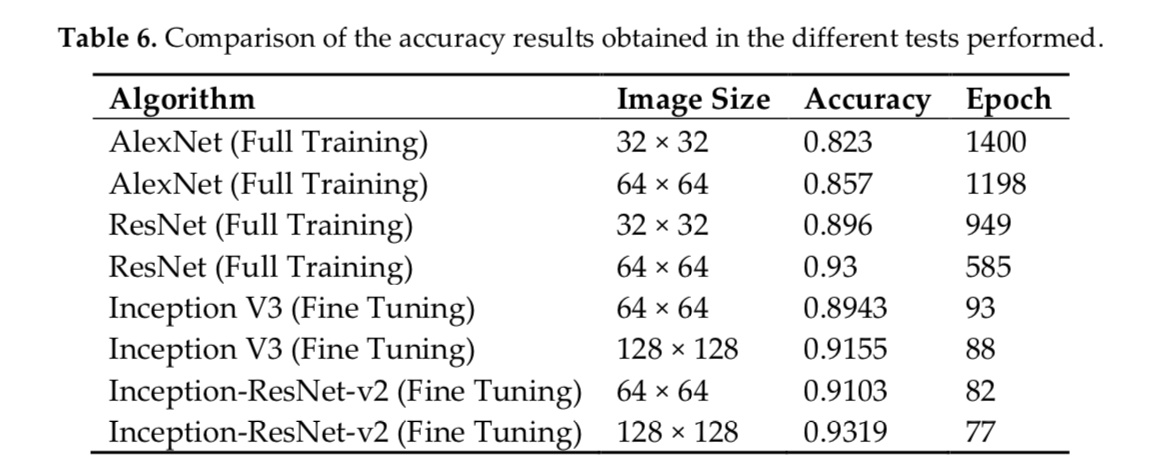
Paper introducing the dataset and accuracies. I am working with 128x128.
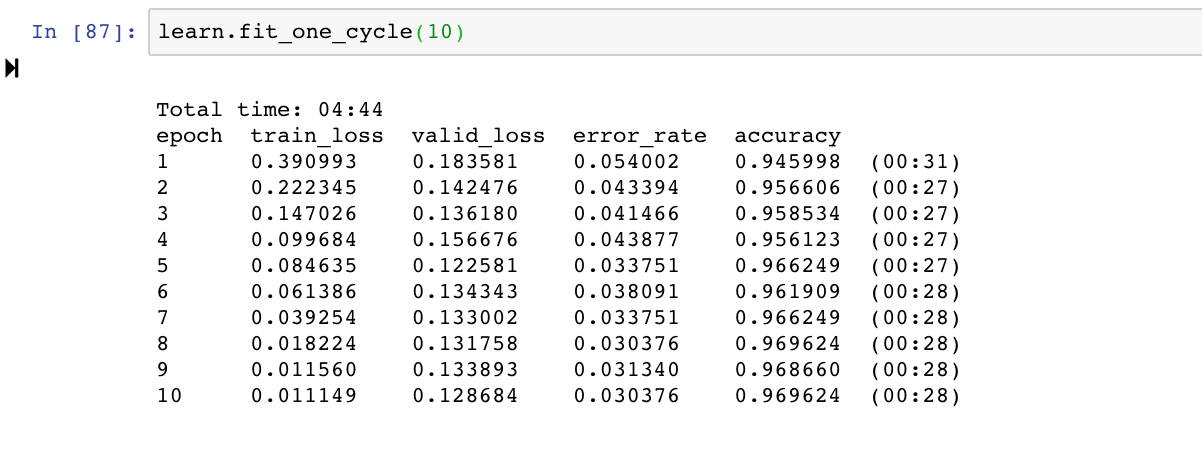
My model and accuracies:
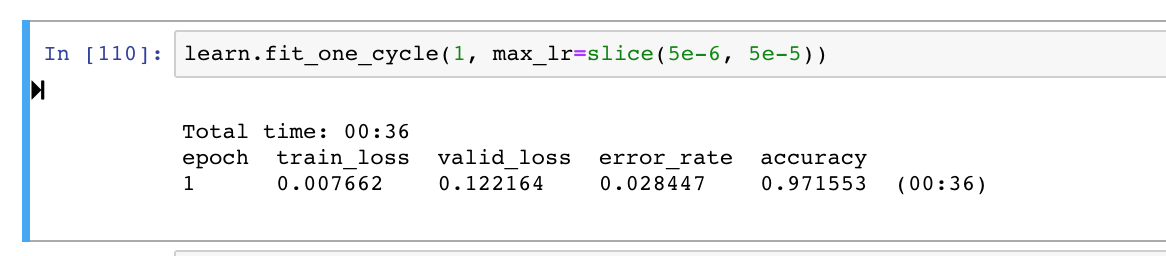
after some finetuning
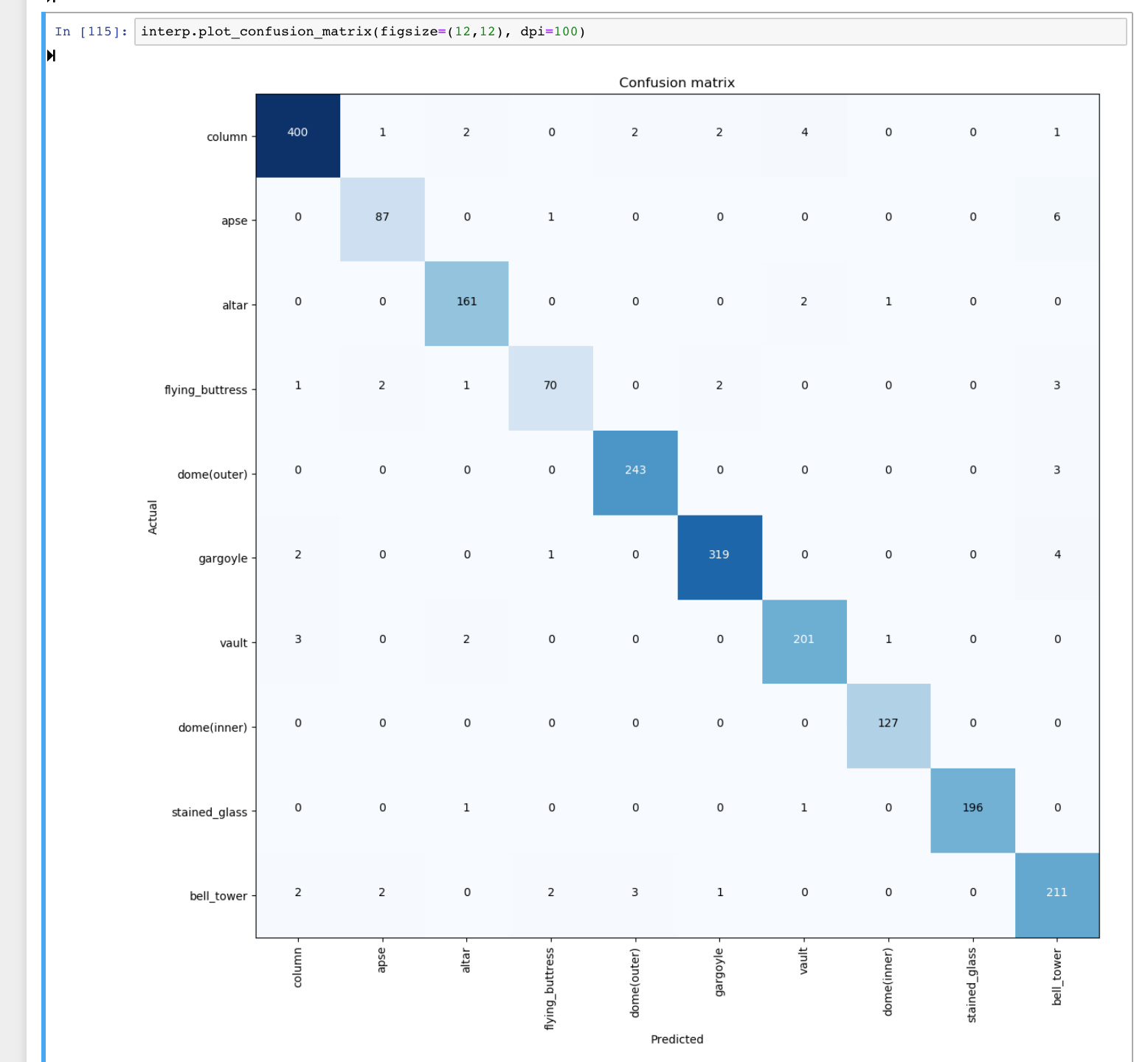
The model makes logical mistakes, as in it gets things wrong which makes sense

confusion matrix plot
cc @jeremy