Hi All,
After a lot of pain and persisting through it, finally able to run a couple of experiments on the google audioset.
Here is the notebook to work on google audioset data. At a high level, audioset data contains human annotated labels (based on audio) in various youtube videos almost~2M. The annotation data has links to these videos, labels and the 10s clip in the video used. So we need to download the relevant youtube videos to prepare the dataset. This took a lot of time for me even with multiprocessing. Any suggestions on how to improve this are welcome.
Post download of data, below notebooks are used to convert audio clips to images of spectrogram images(thanks to @etown for the code) and run two experiments
-
Dog Bark vs Cat Meow - Had close to 4.5k audio samples and ~5GB of data. Got an accuracy of 93%.
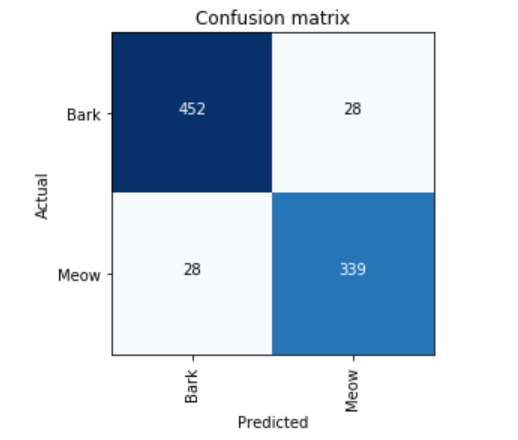
-
Boat vs Motorcycle vs Racecar vs Helicopter vs Railroadcar - Even for just five classes, this dataset turned out to be too huge with ~33k audio clips. Post downloading, the 10s audio clips turned to around ~45GB of wav files. So it was a bit challenging to download the data given the huge network overhead
Coming to the results, the accuracy is around 66% with both resnet 34 and 50.
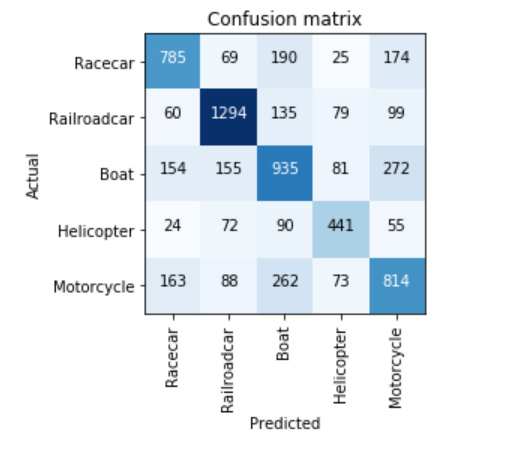
Also the model is grossly overfitting when training all the layers.
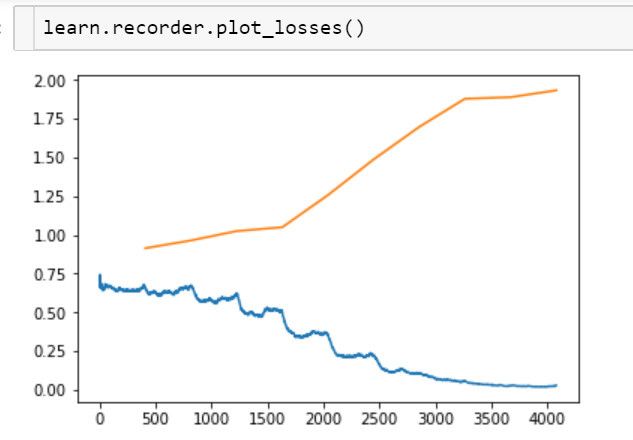
Will look to improve upon this and avoid overfitting based on the next lessons