I had bad luck with birds and flowers, now I tried sounds and the results seems quite promising. I trained a classifier on spectrogram images generated from audio files that I downloaded from this Kaggle competition.
With a ResNet-34 and 4 epochs:
Total time: 36:42
epoch train_loss valid_loss error_rate
1 2.823842 1.935167 0.541053 (27:39)
2 1.968809 1.414007 0.408421 (03:00)
3 1.570557 1.216676 0.344211 (03:01)
4 1.380666 1.171882 0.330526 (03:01)
The top losses are

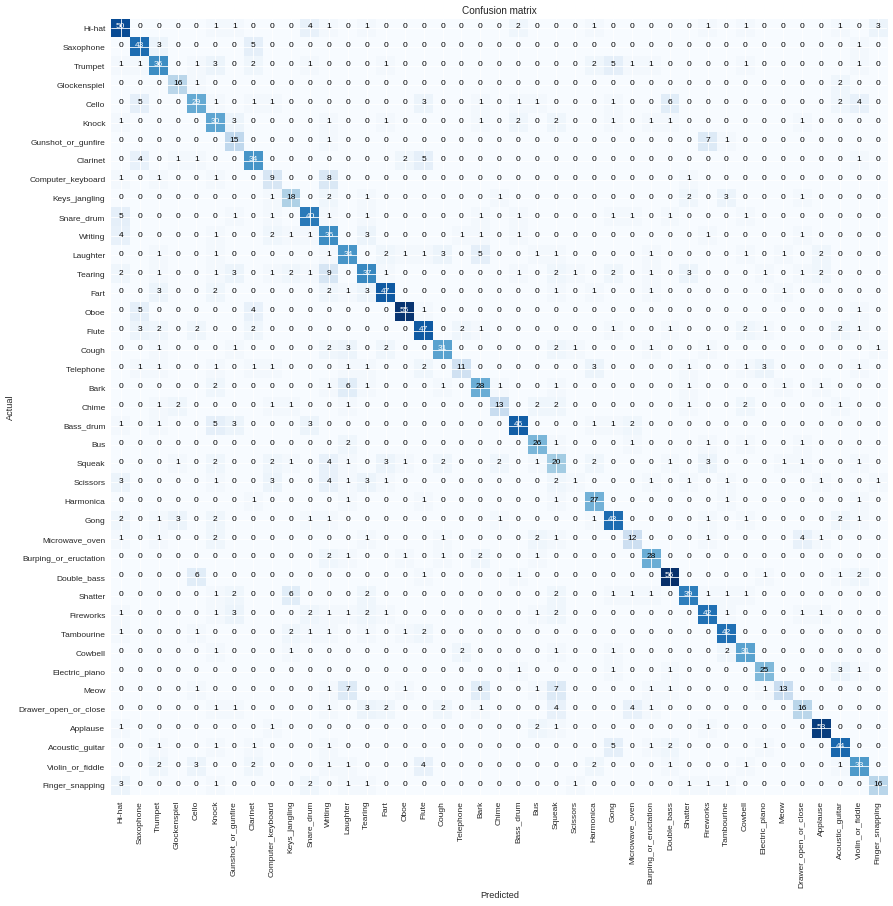
The confusion matrix looks OK
After unfreezing and choosing a good slice of learning rates, I got even better results:
Total time: 25:07
epoch train_loss valid_loss error_rate
1 1.272060 1.071349 0.293684 (03:08)
2 1.148295 0.994182 0.280526 (03:09)
3 1.040785 0.941049 0.264737 (03:08)
4 0.834645 0.837393 0.224737 (03:08)
5 0.664606 0.752477 0.205789 (03:08)
6 0.499639 0.716157 0.198421 (03:08)
7 0.399242 0.692799 0.188421 (03:07)
8 0.339768 0.671222 0.184737 (03:08)
Jupyter notebook - link