I wanted to create a craft-beer identification network which would tell me quality/rating of a beer from an image. I realised early on that I couldn’t just use the lesson 2 classifier, because this problem requires not just image classification, but segmentation too. When there are multiple craft beers in the frame, I need to return different predictions to different coordinates.
The way I solved this was, first using this pre-trained pytorch implementation of YOLOv3, to segment and draw bounding boxes around the 1000 (possible) classes in imagenet.
Then, if the detection class = 39 (a bottle), I would pass this cut-out to the custom trained FastAI resnet model, and display the results as an overlay on the original image.
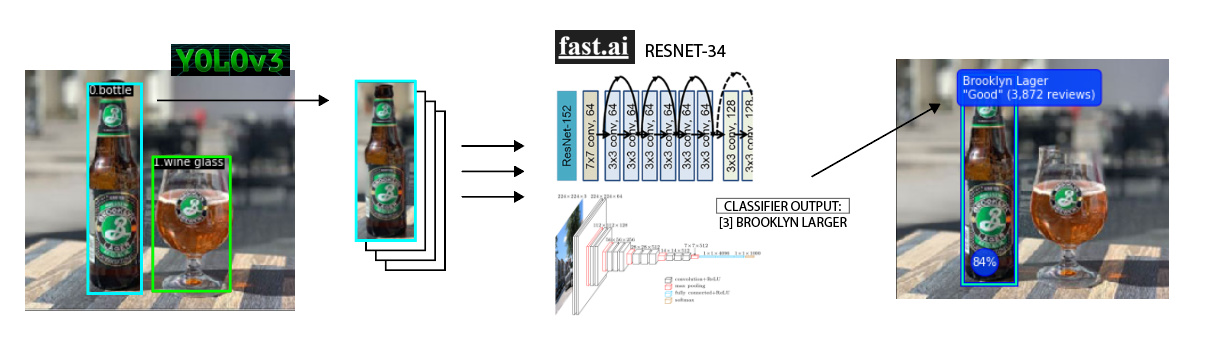
The code works well, but of course there’s the limitation that it only classifies beers that I’ve already looked up and created a dataset for. I can imagine some kind of future work which automatically adds brands to the model by scraping Google Images based on a master-list, then using YOLOv3 to extract bottles from the search results, and then running those images in training.

Also I have a short video of it running on my GitHub, but it would need some considerable refactoring to make it actually run in real-time (and beyond the scope of this hobby project)