Banknotes detection for blind people
I wanted to share a banknote detector I made. It recognizes what currency it is (euro or usd dollar) and what denomination (5,10,20, …). The social impact purpose is to help blind people, so I took care to make “real-life” training images holding the banknotes in my hand, sometimes folded, sometimes covering part of it.
It is deployed on iris.brunosan.eu

As others have shared, the fast, fun and easier part is the deep learning part (congrats fastai!), and the production server took roughly 10x time (I also had to learn some details about docker and serverless applications).
The challenge
I found just a few efforts on identifying banknotes to help blind people. Some attempts use Computer Vision and “scale-invariant features” (with ~70% accuracy) and some use Machine Learning (with much higher accuracy. On the machine learning side, worth mentioning one by Microsoft research last year and one by a Nepali programmer, Kshitiz Rimal, with support from Intel, this year.
-
Microsoft announced their version at an AI summit last year, “has been downloaded more than 100,000 times and has helped users with over three million tasks.” Their code is available here (sans training data). Basically, they use Keras and transfer learning, as we do in our course, but they don’t unfreeze for fine-tuning, and they create a “background” class of non-relevant pictures (which, as Jeremy says, it’s odd to create a “negative” class). They used a mobile-friendly pre-trained net “MobileNet” to run the detection on-device, and 250 images per banknote (+ plus data augmentation). They get 85% accuracy.
-
The nepali version from Kshitiz: 14,000 images in total (taken by him), and gets 93% accuracy. He started with VGG19 and Keras for the nural net, and “Reach Native” for the app (This is a framework that can create both an iOS and Android app with the same code), but then he switched to Tensorflow with MobileNetV2 and native apps on each platform. This was a 6 months effort. Kudos!! He has the code for the training, AND the code for the apps, AND the training data on github.
My goal was to replicate a similar solution, but I will only make a functioning website, not the app, or on-device detection (I’m leaving that for now). Since I wanted to do several currencies at once, I wanted to try multi-class classification. All the solutions I’ve seen use single-class detection, e.g. “1 usd”, and I wanted to break it into two classes, “1” and “usd”. The reason being that I think there are features to learn across currencies (all USD look similar) and also across denominations (the 5usd and 5eur have the number in common). The commonalities should help the net reinforce those features for each class (e.g. a big digit “5”).
The easy part, Deep learning
I basically followed the multi-class lessons for satellite detection, without really many changes:
The data
It is surprisingly hard to get images on single banknotes in real-life situations. After finishing this project I found the Jordan paper and the Nepali project which both link to their dataset.
I decided to lean on Google Image searches, which I knew was going to give me unrealistically good images of banknotes, and then some that I took myself with money I had home for the low denominations (sadly I don’t have 100$ or 500eur lying around at home). In total I had between 14 and 30 images per banknote denomination. Not much at all. My dataset is here.
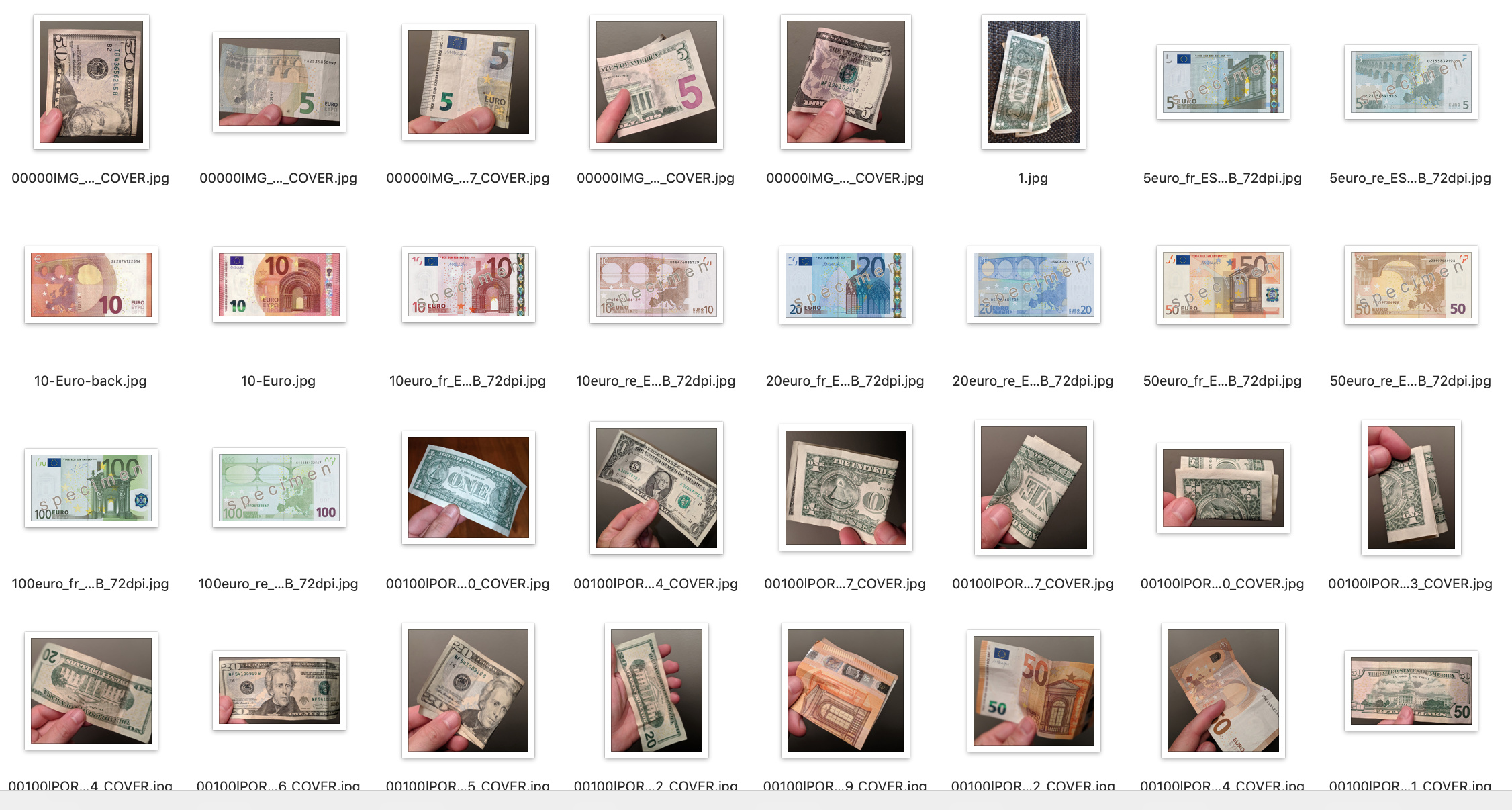
Since I didn’t have many images, I used data augmentation with widened parameters. (I wrongly added flips, it’s probably not a good idea):
tfms = get_transforms(do_flip=True,flip_vert=True,
max_rotate=90,
max_zoom=1.5,
max_lighting=0.5,
max_warp=0.5)
In the end, the training/validation set it looked like this:

It’s amazing one can get such good results with that few images.
The training
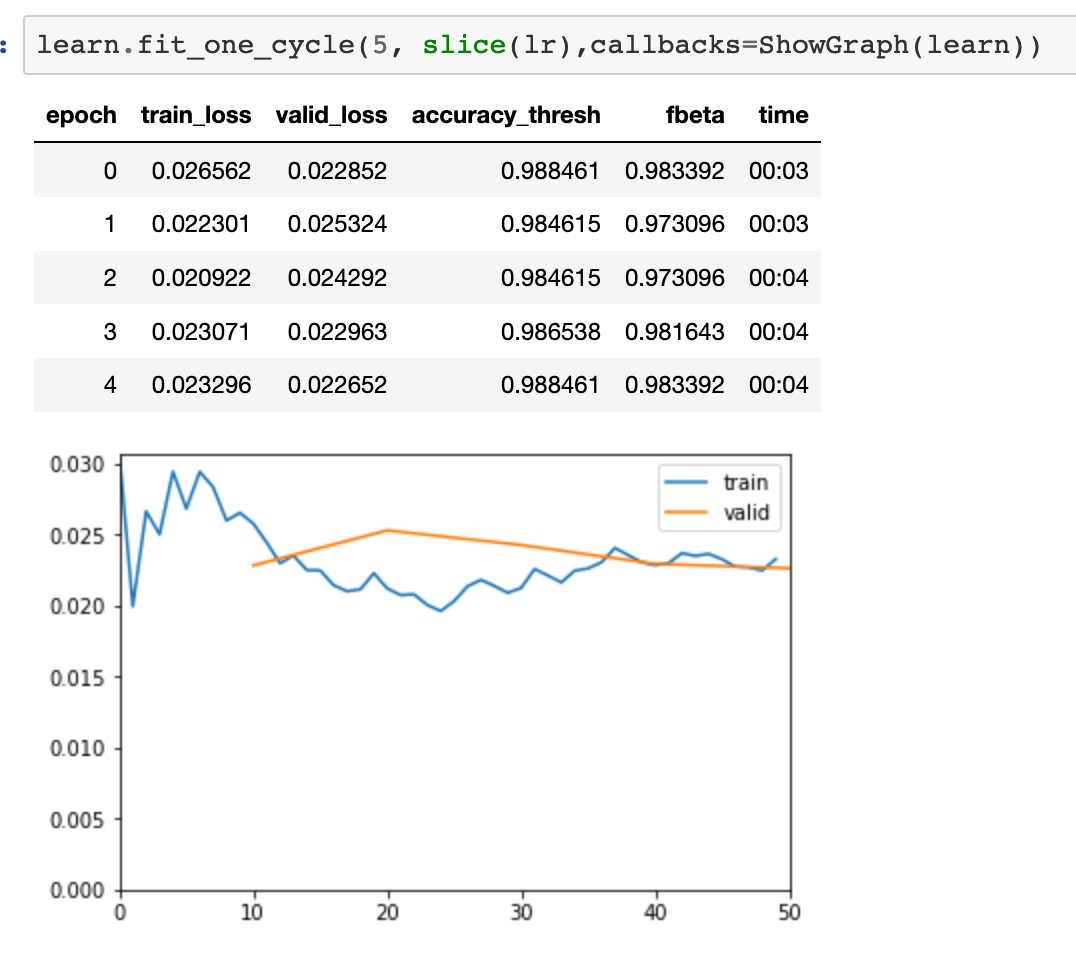
I used 20% split for validation, 256 pixel size for the images, resnet50 as the pre-trained model. With the resnet frozen, I did 15 epochs (2 minutes each) and got an fbeta of .087, pretty good already. Then unfroze and did more training with sliced learning rates (bigger on the last layers) on 20 epochs, to get .098. I was able to squeeze some more accuracy by freezing again the pre-trained model and doing some more epochs. The best was fbeta=0.983. No signs of over-fitting, and I used the default parameters of dropout.
Exporting the model and testing inference.
Exporting the model to PyTorch Torch script for deployment is just a few lines of code.
I did spend some time testing the exported model, and looking at the outputs (both the raw activations and the softmax. I then realized that I could use it to infer confidence:
- positive raw activations (which always translate to high softmax) usually meant high confidence
- negative raw activations but non-zero softmax probabilities happened when there was no clear identification, so I could use them as “tentative alternatives”.
e.g. this problematic image of a folded 5usd covering most of the 5

{‘probabilities’:
‘classes’: [‘1’, ‘10’, ‘100’, ‘20’, ‘200’, ‘5’, ‘50’, ‘500’, ‘euro’, ‘usd’]
‘softmax’: [‘0.00’, ‘0.00’, ‘0.01’, ‘0.04’, ‘0.01’, ‘0.20’, ‘0.00’, ‘0.00’, ‘0.00’, ‘99.73’],
‘output’: [’-544.18’, ‘-616.93’, ‘-347.05’, ‘-246.08’, ‘-430.36’, ‘-83.76’, ‘-550.20’, ‘-655.22’, ‘-535.67’, ‘537.59’],
‘summary’: [‘usd’],
‘others’: {‘5’: ‘0.20%’, ‘20’: ‘0.04%’, ‘100’: ‘0.01%’, ‘200’: ‘0.01%’}}
Only the activations for class “usd” positive (last on the array), but the softmax also correctly brings the class “5” up, together with some doubt about the class 20.
Deployment
This was the hard part.
Basically you need 2 parts. The client and the server.
-
The front-end is what people see, and what it does is give you a page to look at (I use Bootstrap for the UI), the code to select an image and finally displays the result. I added some code to downsample the image on the client using Javascript. The reason being that camera pictures are quite heavy nowadays and all the inference process needs is a 256 pixel image. These are the 11 lines of code to downsample on the client. Since these are all static code, I used github pages on the same repository.
-
The back-end is the one that receives the image, runs the inference code on our model, and returns the results. It’s the hard part of the hard part
 , see below:
, see below:
I first used Google Cloud Engine (GCE), as instructed here . My deployment code is here, and it includes code to upload and save a copy of the user images with the infered class, so I can check false classifications use them for further training.
Overall it was very easy to deploy. It basically creates a docker that deploys whatever code you need, and spins instances as needed. My problem was that the server is always running, actually 2 copies, at least. GCE is meant for very high scalability and response which is great, but it also meant I was paying all the time, even if no one is using it. I think it would have been 5-10$/month. If possible I wanted to deploy something that can remain online for long without paying much.
I decided to switch to AWS Lambda (course instructions here). The process looks more complicated, but it’s actually not that hard, and the huge benefit is that you only pay for use. Moreover, for the usage level, we will be well within the free tier (except the cost of keeping the model on S3, which is minimal). My code to deploy is here. Since you are deploying a Torchscript model, you just need PyTorch dependencies, and AWS has a nice docker file with all that you need. I had to add some libraries for formatting the output and logging and they were all there. That means your actual python code is minimal and you don’t need to bring fastai (On this thread Laura shared her deployment tricks IF you need to also bring fastai to the deployment).
UX, response time.
Inference of the classification takes .2 seconds roughly, which is really fast, but the overall time for the user from selecting the image to getting the result can be up to 30s, or even fail. The extra time is partly uploading the image from the client to the server, and downscaling it before uploading if needed. In real-life tests, the response time was roughly 1s, which is acceptable… except for the first times, it sometimes took up to 30s to respond for the first time. I think this is called “cold start”, as AWS pulls the Lambda from storage. To minimize the impact I added some code that triggers a ping to the server as soon as you load the client page. That ping just returns “pong” so it doesn’t consume much billing time, but it triggers AWS to get the lambda function ready for the real inference call.
Advocacy
This summer I have a small weekly section to talk about Impact Science on a spanish national radio, and we dedicated the last one to talk about Artifical Intelligence and the impact on employment and Society. I presented this tool as an example. You can listen to it (in Spanish) here (timestamp 2h31m) Julia en la Onda, Onda Cero.
Next steps
I’d love to get your feedback and ideas. Or if you try to replicate it have problems, let me know.
- Re-train the model using a mobile-friendly like “MobileNetV2”
- Re-train the model using as many currencies (and coins) as possible. The benefits of multi-category classification to detect the denomination should become visible as you add more currencies.
- Add server code to upload a copy of the user images, as I did with the GCE deployment.
- Smartphone apps with on-device inference.