fast.ai Course Forums
Share your work here ✅
Part 1 (2019)
kampamocha
(Diego Campos)
July 29, 2019, 5:08pm
1500
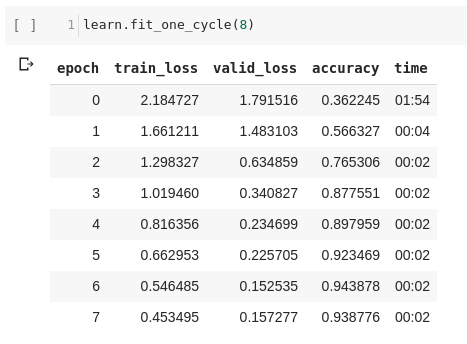
I trained a resnet50 to classify emotions on faces with the CK+ dataset (6% error).
image.png
762×835 61.3 KB
image.png
708×829 30.9 KB
1 Like
Share you work here - highlights
show post in topic