What Programming Language Is It?
Programming Language Classifier
After watching lessons 1-4, I decided to make a web app that classifies text according to the programming language. I searched the web, but couldn’t find much research on this topic. There was one example (https://arxiv.org/pdf/1809.07945.pdf) that uses a Multinomial Naive Bayes (MNB) classifier to achieve 75% accuracy, which is higher than that with Programming Languages Identification (PLI–a proprietary online classifier of snippets) whose accuracy is only 55.5%.
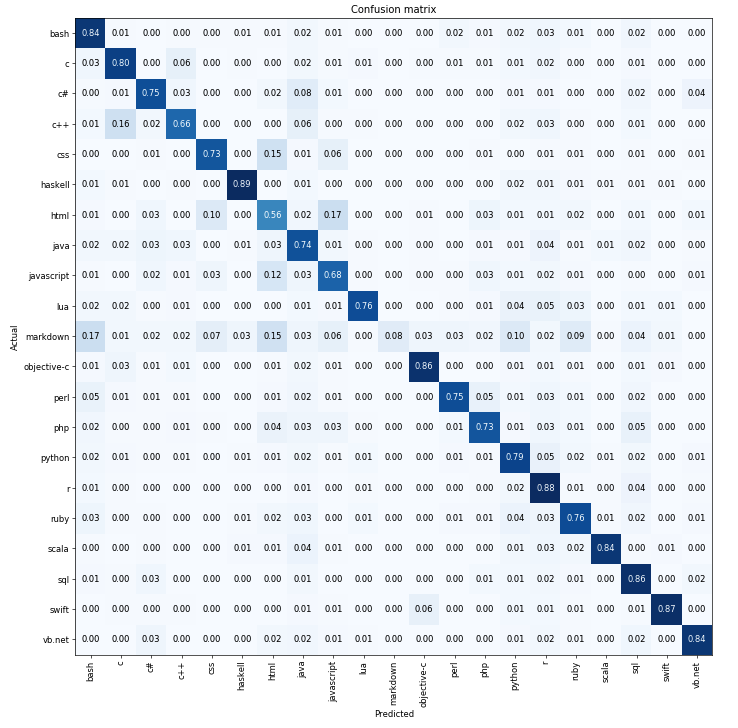
I was able to reach about 81% accuracy(according to fastai) (although I’m not sure I’m measuring it the same way as the paper) after following the same basic steps as the IMDB example. This was done with the dataset I found from the author of the paper, here: https://github.com/Kamel773/SourceCodeClassification. I noticed that the dataset is pretty messy and a lot of the css/html/javascript is misclassified as another one in that group. That is apparent in the confusion matrix:
But, regardless, I made a web app, which is currently here: https://programming-language-classifier.onrender.com. It lets you paste in a snippet of code and it will tell you what language it thinks it is. Give it a try and see if you can confuse it! I created the web app based on the template here: https://github.com/render-examples/fastai-v3.
I did find another data set of classified code on Kaggle, which is way bigger (called “lots of code”) (and hopefully has less misclassifications) that I am going to try to use to improve the accuracy even further.
I am having way too much fun with this course. Thanks everyone!