Hi! I used fastai to train a model that can generate bird images from text description, and made a web app:
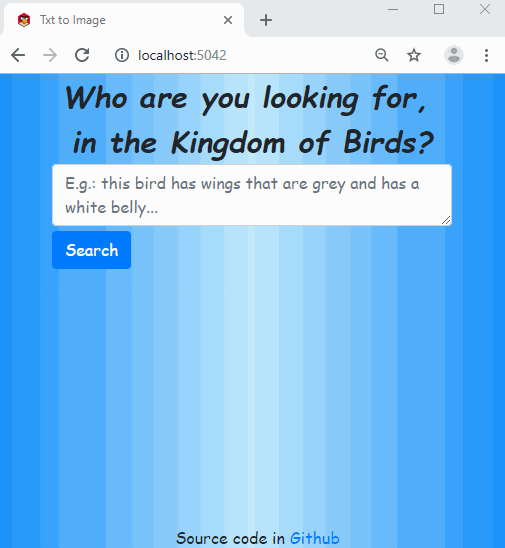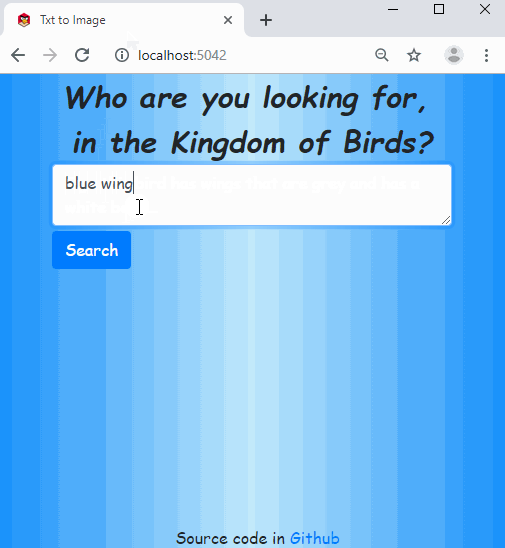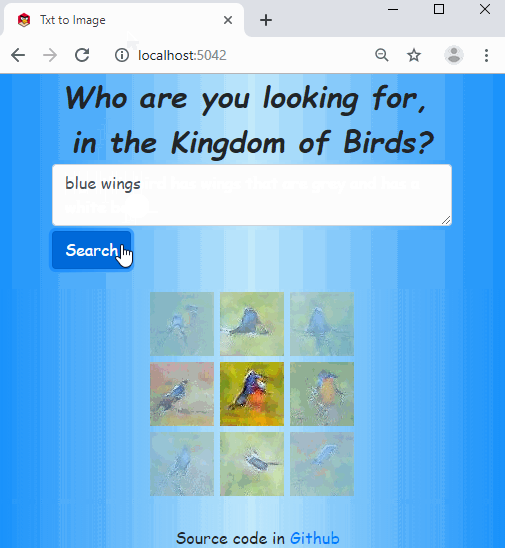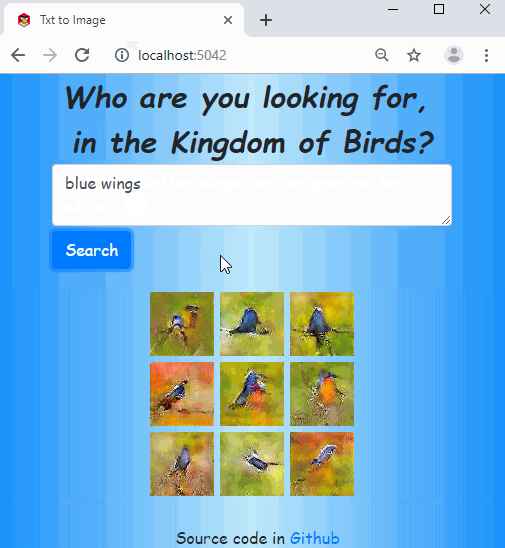
The code is in this repo. The idea is based on this paper, but I used fastai with some customizations for all the works.
There’re a lot of things to improve, but I’d like to share and discuss with you. Thank you for checking out!