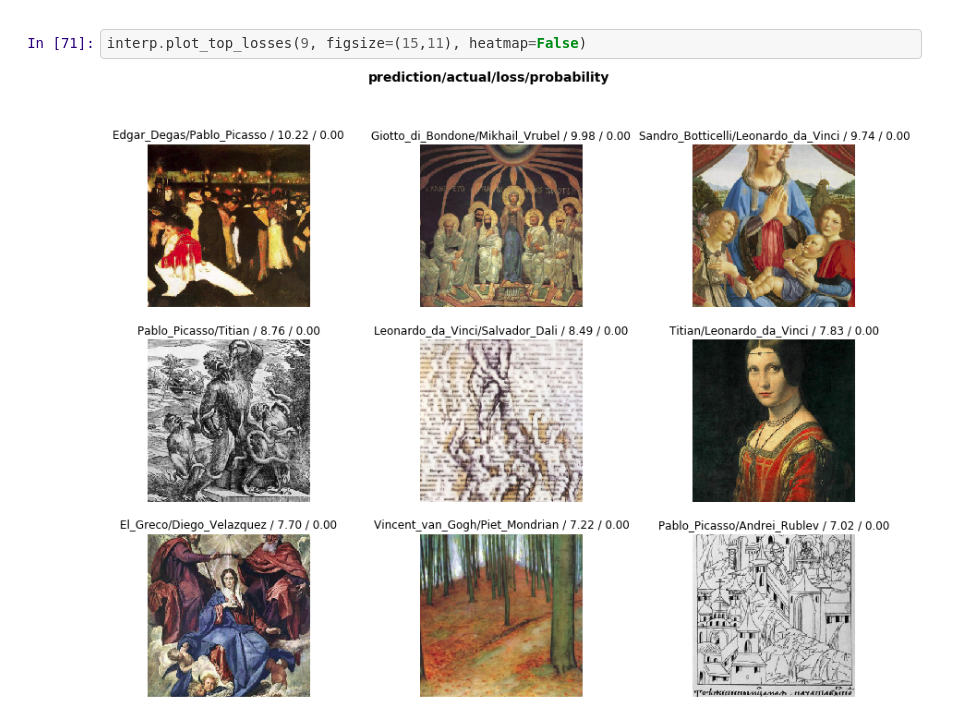
Who is the artist?
For lesson 1 assignment, I used kaggle artwork dataset of paintings by 50 artists and tried to classify the artist.
Results summary:
Resnet34 with 4 epochs on top layers gets 33.8% error rate.
4 epochs of fine tuning reduces the error to 21.5%
Resnet50 with 8 epochs on the top layer (no unfreeze) achieves 20% error rate
10 more on all layers (unfreeze) results in 15.5% error rate
Further training would probably continue reducing the error rate but I am not sure whether it is over fitting.

Interesting to see the error analysis