Real Time Handwritten recognition CHALLENGE
(Recognizing digits in the wild)
Hello everybody I have been reading this thread since I joined this wonderful course a month ago and I think this thread is amazing, so many high quality projects in one place.
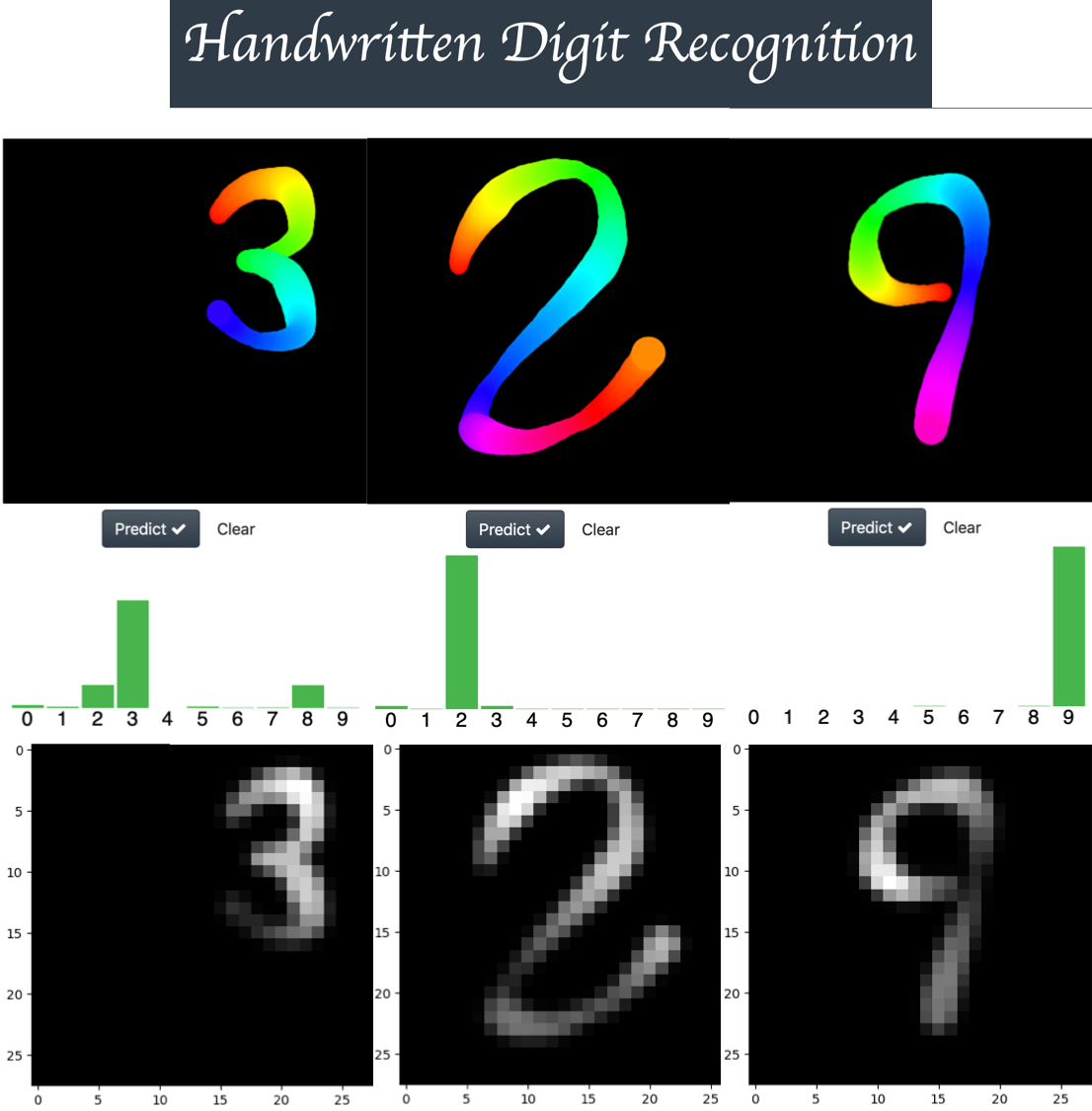
Now, I want to share a little project that I have been developing this week. My intent was to build a reliable app for handwritten digit recognition under adverse conditions (with a pen tip that changes its size and color during the drawing process) using the MNIST dataset. If you want, you can play with the app using the following link (EDIT – SUPPORT ADDED FOR TOUCH SCREEN DEVICES)
As shown in the figure above, the width and color changes as a digit is drawn and cold colors (like blue) generate low intensity strokes, (you can see this when the images are converted into an MNIST format image). So I think this app is a good way to challenge the true performance of any neural network architecture.
Interesting results
As humans we tend to associate abstract ideas to familiar concepts, for example you can see an smiling face just here ( = ) ). So I tested if the networks that I trained share this ability of recognizing abstract representations of a digit, but at difference with the pathological cases of the MNIST set (where some digits are unrecognizable for any human being), I used representations which are easily recognizable for any of us. In the image below I shown examples for the following numbers:
row1: 4 8 5
row2: 6 7 4
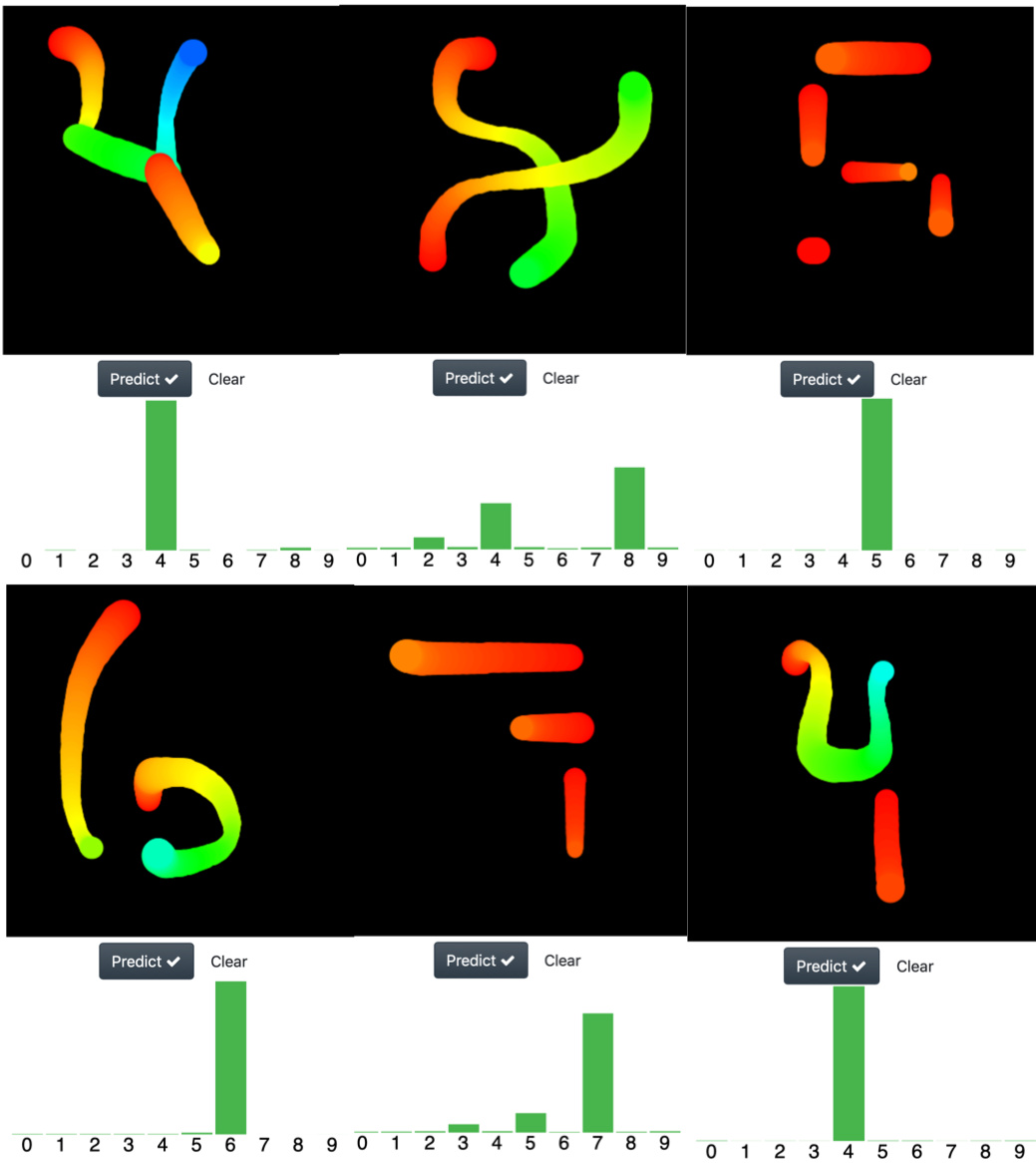
I was amazed with the performance of the nets, so I pushed them a bit further in its ability to recognize abstract representation of digits with the following images.
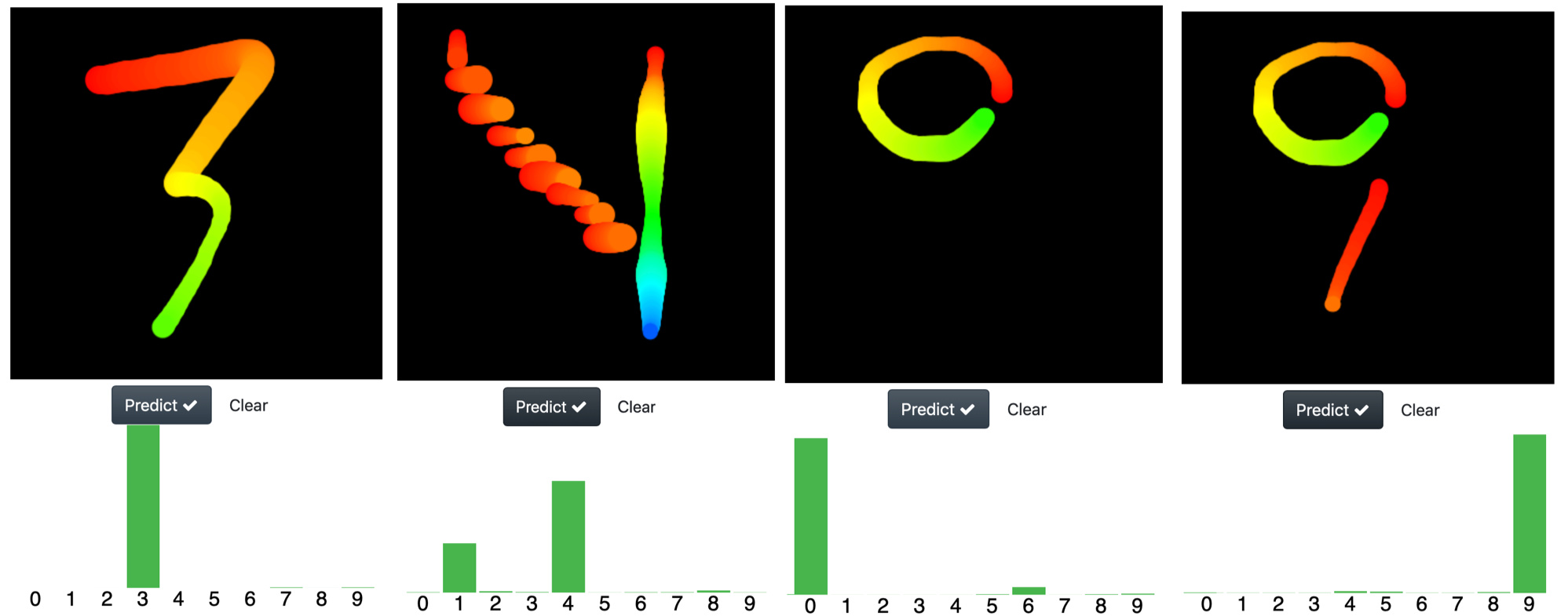
Particularly a challenging one was the digit “4”. I drew it as descending stairs from heaven with a rainbow waterfall at the background (yeah all that is there, you can see it? 

 ) and the net can do it very well, it chooses the number 4 but it also get doubts and give it a chance (a probability) to the number 1 (a very reasonable choice).
) and the net can do it very well, it chooses the number 4 but it also get doubts and give it a chance (a probability) to the number 1 (a very reasonable choice).
Who are those neural nets?
To make the things fun I decided to test three different neural networks architectures to see which one generalized better on unseen samples, the architectures are:
-
The “resent-ish” CNN coded by Jeremy in this notebook
-
The “lenet-like” CNN based on this kaggle kernel , (I code only one of the fifteen CNNs that are originally proposed)
-
The “Capsule net”, the capsule net is a very cool and clever idea which make used of spatial information contained inside the image to improve its performance. Indeed I found the capsule net amazing because for me the idea behind the routing agreement algorithm looks very similar to the idea behind the determination of eigenstates in quantum physics. I use this GitHub repo to build the network
Which one performed better?
I didn’t make any rigorous statistical analysis to answer this question, so all I can to say is subjective to my experience testing each network while I was playing around with the app. At the begging the best one was the resnet-ish cnn, because I trained the other two using pure pytorch but I found hard setting the right hyperparameters. Letter on I trained the “lenet-like” using fastai and its performance increase considerably. So right now I can say both, the “resnet-ish” and the “lenet-like” architectures performed equally well under the conditions of my app.
With respect to the capsule net, I tried trained it using fastai but I can’t achieve good results at all, (the net made very obvious mistakes and always show a very high training and validation losses for all the learning rates I tried ). Indeed this is an interesting result and I will try to review why is this happening.
So I trained capsule net using pure Pytorch (following the condition stated in the paper, using Adam and without schedulers). After my training with Pytorch, the capsule network performs almost as well as the other two, but not as well. It has troubles in recognizing digits written at the corners of the drawing area. Also I have to include the same random affine transformations I used for the other two networks during the training process to improve its performance (scaling (0.5, 1.3) , rotations (15º), and translation (0.1)). That is interesting because in theory this networks doesn’t required of this kind of data augmentation to generalize on unseen rotated or shifted samples of the same kind of images used during training.
The capsule network works as an inverse decoder. How do the reconstructed images look like?
Yeah, another cool feature of the capsule net, is that it works as an inverse image decoder, so it’s possible extract the image that the neural net “think” it is seen. Below I show interesting examples of this.
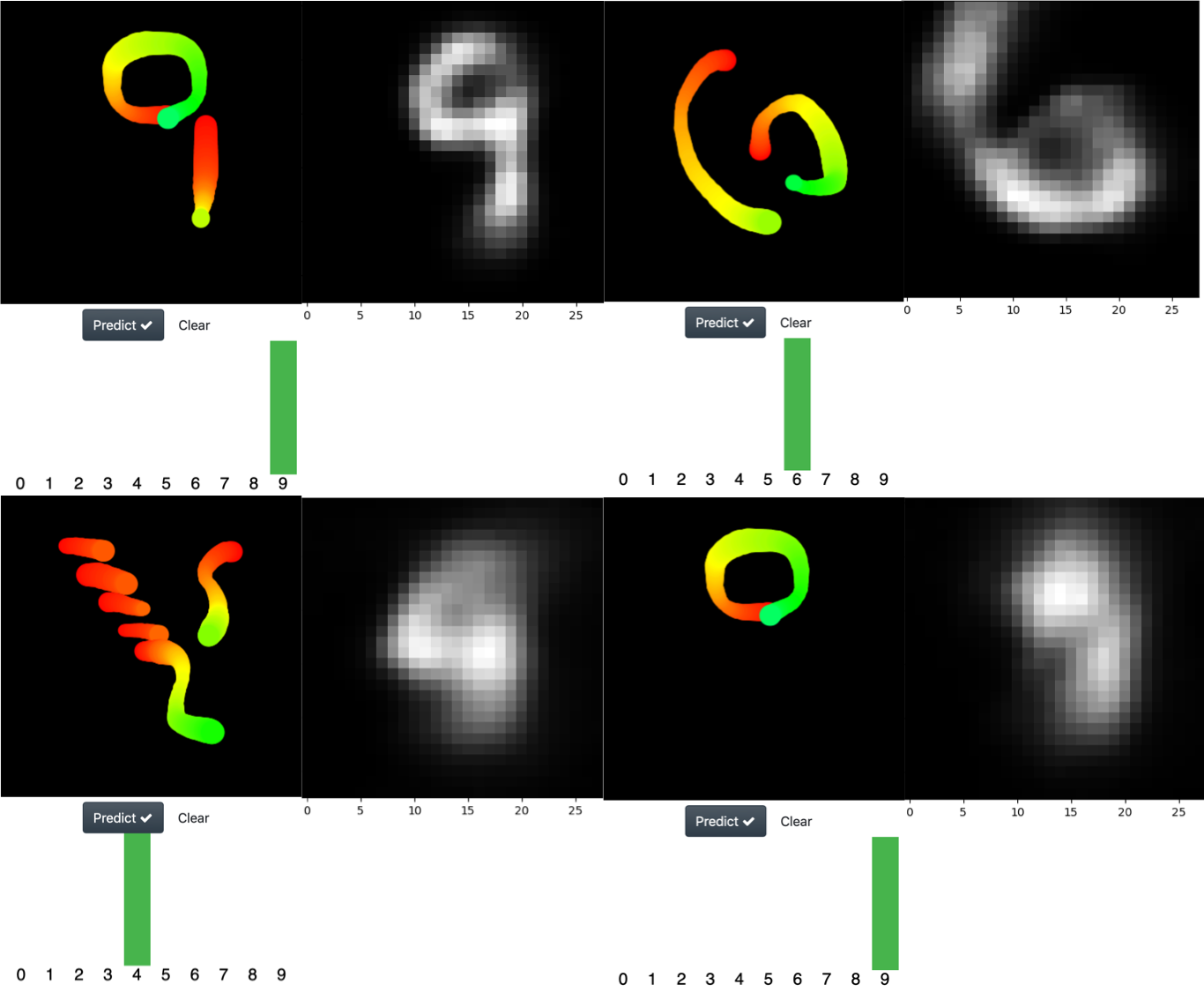
At the left is the drew digit and at the right is the reconstruction performed by the network. As you can see, in the last image the net confused a zero with a nine
Why the capsule network wasn’t the best performer?
Quoting the original paper
There are many possible ways to implement the general idea of capsules. The aim of this paper is not
to explore this whole space but simply to show that one fairly straightforward implementation works
well and that dynamic routing helps
So, maybe the current architecture isn’t the best one possible to implement the idea. That was also one of my motivation for this project.
Is the code available?
Yeah, you can get the code from my GitHub repo. There, I wrote an easy to follow guide (I think) explaining how you can easily add your own architectures to the app or how you can use the ones that are already available (resnet-ish, lenet-like and caps-net). So you don’t need to waste your time understanding my code, you only need to named your net architecture trained with fastai or pytorch (saved them as a .pkl or .pth), put them inside a folder and that’s all, you can have some fun drawing abstract representations of digits in your screen and “test” how good your nets performs under this hard conditions.