Hey there,
I want to share my MNIST equivalent with you 
This is my little image classification app that distinguished between the seven different plastics defined by the industry standard RIC (resin identification code). I built up my own dataset by taking photos almost during every shopping tour. By now my dataset contains of ~450 pictures of the seven different plastics.
This is my dataset on kaggle: https://www.kaggle.com/piaoya/plastic-recycling-codes
You are very welcome to contibute  (no websearch pictures, please)
(no websearch pictures, please)
My goal was to built up a little website or app where you get information on whether the plastics are ready to recycle or not. What are alternatives? Which specific effects has the classified plastic on our health? What does it mean for the environment? Here are some pictures of my mock-up - you can test it also on render:
https://plastics.onrender.com/
(As long as I still have credit on render  )
)


Sadly the training of the model is not so good yet, I think this might be because of the lack in data.
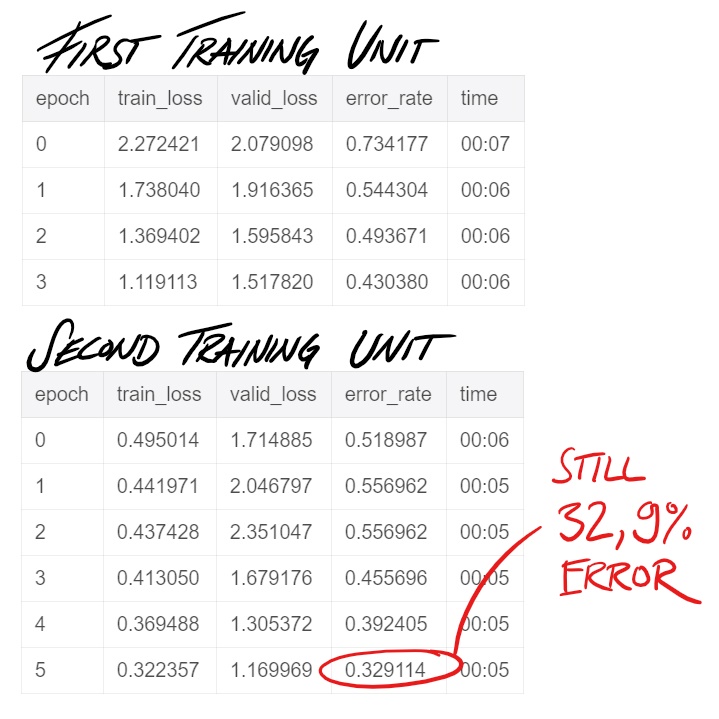
Do you think this could be interesting to develop further? Is anyone interested in collaborating to make this open available as a service?