Hi all,
After reading about Progressive Resizing as well as Mixed Precision here in the forums, I tried these techniques out on an image classification problem for the Plant Village plant diseases data set (other students have shared their projects on the same data set here as well – hi @aayushmnit @Shubhajit  ).
).
I was very surprised I was able to get a better than the top result! (99.76 percent)
And to think that this was on Colab, a free DL platform.
Thanks to fastai’s mixed precision capabilities, I was able to train faster in larger batches using progressive sizing for a smaller number of epochs using smaller sized images – @sgugger your mixed precision feature works wonders!!
TLDR;
The following steps were used to create the final model:
Note: all the training was done using Mixed Precision (learn.to_fp16())
except when running an interpretation, in which the model was converted to use 32bit fp (learn.to_fp32()) in order to run classification interpretation steps – for some reason, fastai barfs when classification interpretation is run on a mixed precision model.
-
Use image size of 112x112, batchsize=256
- Stage 1 - Frozen except last layer, train at default LR (1e-3)
- Best result : 0.982915
- 5 epochs at 6 mins per epoch, total training time: 29:58
- Stage 2 - Unfreeze, train with LR slice 1e-6,5e-4
- Best result: 0.992821
- 4 epochs at 6.3 mins per epoch, total training time: 25:22
- Stage 1 - Frozen except last layer, train at default LR (1e-3)
-
Use image size of 224x224, batchsize=128
- Stage 1 - Frozen except last layer, train at default LR (1e-3)
- Best result : 0.996092
- 5 epochs at 11 mins per epoch, total training time: 55:17
- Stage 2 - Unfreeze, train with LR slice 1e-6, 2e-5
- Best result: 0.996819
- 4 epochs at 14.5 mins per epoch, total training time: 58:34
- Stage 1 - Frozen except last layer, train at default LR (1e-3)
-
Use image size of 299x299, batchsize=128
- Stage 1 - Frozen except last layer, train at default LR (1e-3)
- Best result : 0.997546
- 5 epochs at 24.5 mins per epoch, total training time: 1:43:33
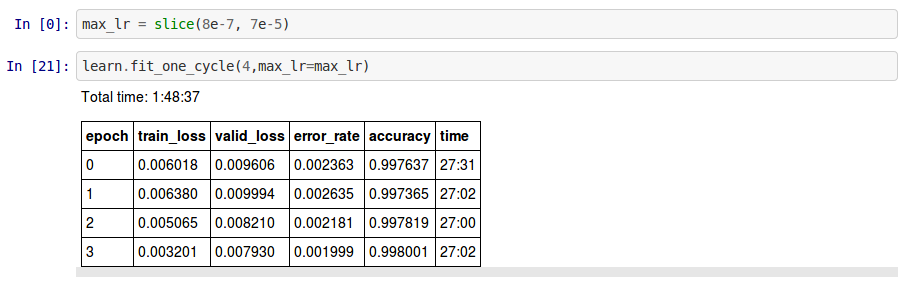
- Stage 2 - Unfreeze, train with LR slice 8e-7, 7e-5
- Best result: 0.998001
- 4 epochs at 27 mins per epoch, total training time: 1:48:37
- Stage 1 - Frozen except last layer, train at default LR (1e-3)
Total Epochs : 36
Total Training Time: 6.36 hrs
Model: ResNET50
Max GPU Memory: 11GB
Another notable finding was the GPU memory usage during training:
-
Using a batch size of 256 and image size of 112x112, Mixed Precision used up approx. 3-4 GB GPU Memory.
-
Using a batch size of 128 and image size of 224x224, Mixed Precision used up approx 3-4 GB as well.
-
Lastly, using a batch size of 128 and image size of 299x299, Mixed Precision used around 11GB GPU Memory (triggering warnings in Colab, but otherwise ran to completion)
If you have suggestions on how I can further speed up the training or just improve on it in general, please reply…
Thanks in advance…
Butch
Here’s my notebook on github or you can run it on Colab
_