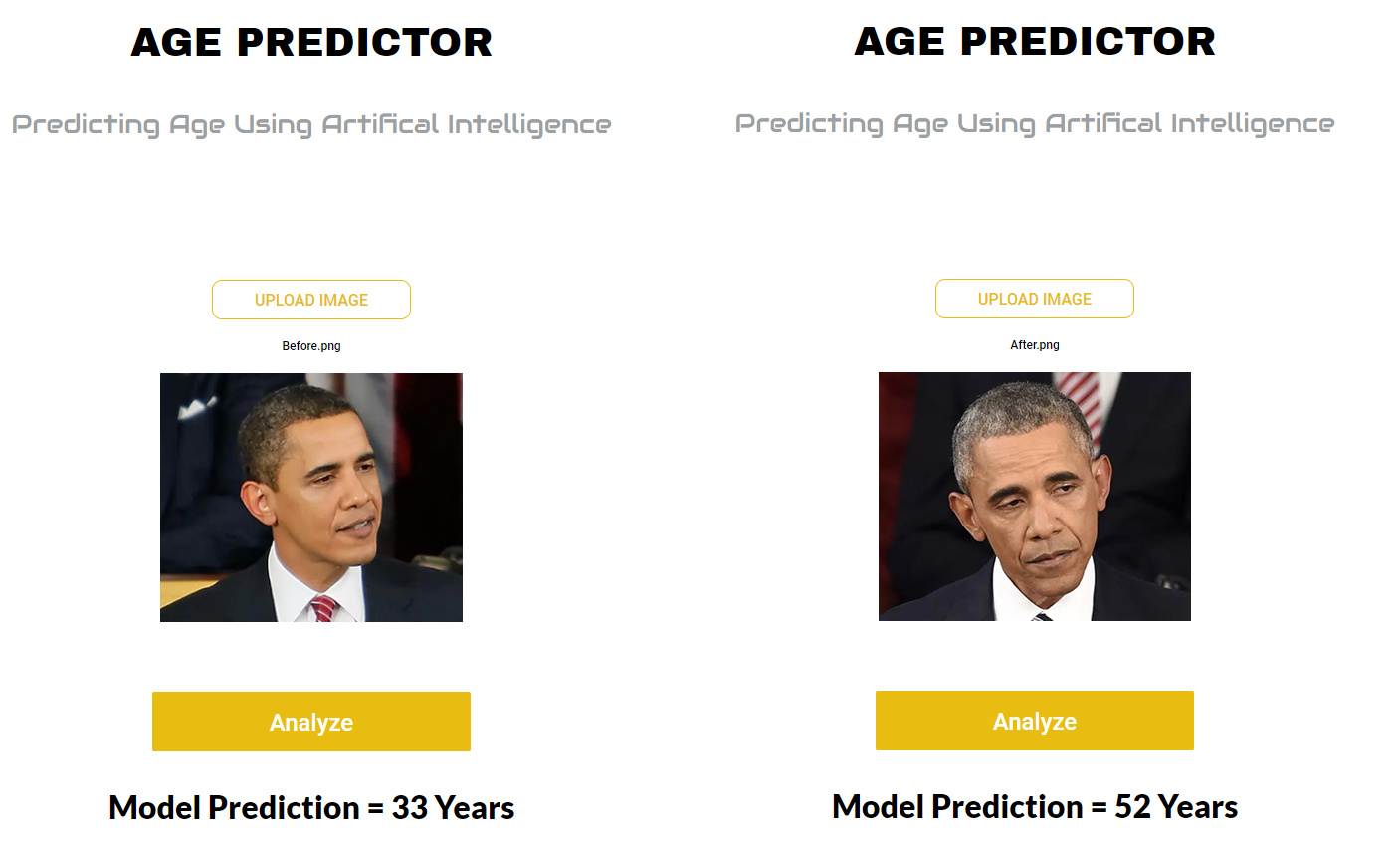
I did a picture of Barack Obama before his presidency and got 33 years, and after he got 52 years. Stressful 8 years aged him 19 years!
3 Likes
I did a picture of Barack Obama before his presidency and got 33 years, and after he got 52 years. Stressful 8 years aged him 19 years!