Hi
I’ve always been fascinated by paintings and different styles of them. I’ve been working on a project to compare baroque paintings with ancient Greek pottery paintings.
Baroque art is characterized by great drama, rich, deep color, and intense light and dark shadows as opposed to Greek paintings where Figures and ornaments were painted on the body of the vessel using shapes and colors reminiscent of silhouettes.
I used a CycleGAN to experiment and see what features in each style were more important for the model to turn the paintings from one style to the other one.
as an example:
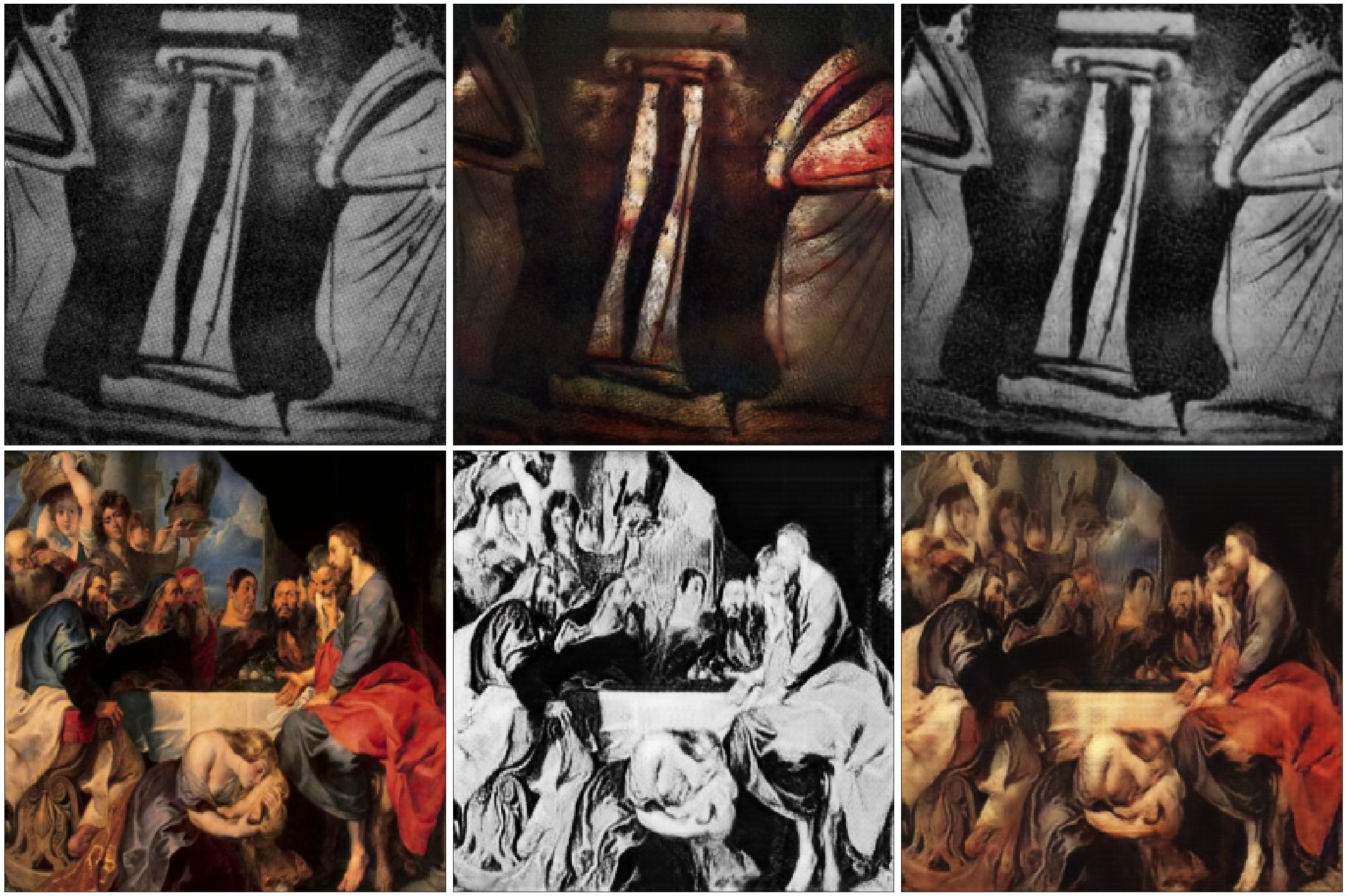
you can see the generator of baroque paintings tries to capture deep color contrasts and shadows features. but that’s a hard job since the Greek paintings usually represented as a solid shape of a single color, usually black, with its edges matching the outline of the subject. but the Greek generator almost captures the main features as dark shadows and solid edges.
The training took about 6hours on a single GPU. the notebook is available in the github repo: CycleGAN
I would really appreciate your feedback.