I’m thinking of using the spectrogram or wavelet for a dataset of mine. Would you mind sharing the code that you’ve used to turn the sounds into well formatted spectrogram images (with no axes, etc.) ?
1 Like
Hi Everyone,
Special thanks to Jeremy for the great class.
I am new to the data science world (started on December 2018), so I decided to dive inside the fastai library, to really understand what’s going on under the hood.
It turns out that if eventually you want to create your own model, or prepare your own data in a non-default way (imagenet style for example), you will need to get to know with datablock API, custom ItemList, create_head(), create_body(), and adaptiveconcatpooling()… And once you start to play with the low level API, you will be shocked how powerful fastai is. 
I want to eventually create my own Siamese network using fastai, (or TripleItemList with anchor / positive / negative). Based on my understanding, this is essential because if you have thousands of classes, Resent accuracy wont be good enough. 1/1000 is a very low probability for guessing, and if you have imbalanced and small dataset,you will have more problem.
(Currently still working on Siamese, and it is far from done and polished to share )
I used MNIST as my first step to understand custom Item List, so I would like to share to the folks like me new to the fastai and thinking custom Item List is really some advanced stuff (labeled ‘advanced tutorial’ in the doc  , it is really not, and it is very easy to use)
, it is really not, and it is very easy to use)
Here is the kaggle kernel for the traditional MNIST dataset
The reason I am using MNIST is following:
- It’s a very simple dataset, and very easy to understand
- We talked a lot in the class (lesson 5 and 7)
- It doesn’t work with default fastai transfer learning style (the data is not img file, it is tabular formatted)
If you ever wondering,
Lesson 5, we did use the pixel value as input, but we create dense net from scratch, no transfer learning involved. We pretty much prepared data in Pytorch style: ‘dataloader, dataset’
Lesson 7, we created our own Resnet CNN model, but the data is in img format, not pixel anymore.
What if I want to use ItemList with pixel input so I can take advantage of transfer learning / argumentation and other cool method like predict with TTA?
We will have to create own ItemList.
For the vision part, the call flow like the following:
from_folder(), from_csv(), from_df() all looking for a filename, then eventually calling get(), the get() will call open() to get single Image (Itembase), then you can start split(), label(), transform(), databunch(), normalize()…
In the MNIST example, if you follow the above path, the custom ItemList is simple, you only need to override open(), and leave the rest part to the ImageItemList(), your super() class. (You don’t even need a init() for your custom class).
Another point I would like to share is how easy add_test() can be used instead of add_test_folder()
add_test() takes an ItemList iterator, when you want to add the test-set after training, you can simply call add_test(CustomItemList.from_df()), you don’t need to override anything, fastai takes care for you.
The computer vision path seems fascinating to me at the moment,
Identify cat / dog -> Identify Species --> Identify Large class (1000+) —> Identify Large class with multiple items in one image
Really looking for part 2 for the bounding box explanation, so I can further my identification project to more than 1 item in single image 
3 Likes
I wrote a tutorial on connecting a text generator (like the one from the IMDB notebook) to twitter – Medium article here. Comments/feedback very welcome!
1 Like
hey @ilovescience. I will surely try that and see if it works. Seems like it does in your kernel. Thanks.
After lesson 5, I followed Jeremy’s suggestions and tried a few different pieces of homework.
Writing my own linear class for the Lesson 5 SGD notebook:
- Per Jeremy’s suggestion, I decided to try out writing my own linear class (to use instead of the nn.Linear class)
- I’m still quite new to coding, so this was pretty difficult for me (it took a few hours, with lots of Googling). After completing it, I feel like I know a lot more about PyTorch, so it was definitely a valuable exercise
- The full code is available at GitHub

Adding momentum into the Lesson 2 SGD notebook:
-
I edited the SGD update function to incorporate momentum. For each step, I calculated the size of the step as step = moms * last_step + (1-moms) * gradient. This was then multiplied by the learning rate to calculate the adjustment to the weight. For the first epoch, I set momentum to zero (a previous step does not exist, so the formula does not really work)
-
I found that with the momentum value set to 0.8, the model trained significantly faster than the previous version
-
The code is available at GitHub
Adding momentum into the update function in the Lesson 5 SGD notebook:
-
Similarly to what I did for the Lesson 2 notebook, I edited the Lesson 5 update function to incorporate momentum. This was a bit harder than the Lesson 2 version, since this model contains multiple sets of parameters
-
The code is available at GitHub
Going back to previous models and trying to improve them:
- During Lesson 5, we learnt about some different options you can use when building models (e.g. weight decay, momentum)
- I went back to one of my previous models and played around with the weight decay value (I increased it a lot from its default of 1e-2), and was able to improve the accuracy significantly
5 Likes
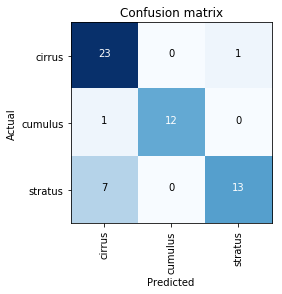
Cloud Classification
While revisiting the earlier lessons of Part 1 using the new version of fastai, I tried to train a model to classify the type of cloud in the sky based on appearance (cumulus, stratus, cirrus). They look something like this:

I was able to get a good enough accuracy but the model seems to be confused between Stratus & Cirrus clouds. On visual examination, I could see that these two clouds are indeed difficult to distinguish between, even by a human at the first glance. Can the model do better?
Here’s a link to my research notebook:
Cloud Classification Research Notebook
Cloud Classification Repo
Bonus Inspiration: ‘Quick, Draw!’ for Clouds
As I was going through pictures of clouds, it occurred to me that as a kid I used to look at the sky when the storm was gathering and tried to imagine the clouds as an approaching army of mythical beasts. Turns out it is indeed a real hobby for some people: The joy of cloudspotting: 10 incredible visions in clouds

“Is that a UFO?”
Can we make something like Quick, Draw! but for clouds, where a model learns to recognize objects in clouds instead of doodles and drawings?
3 Likes
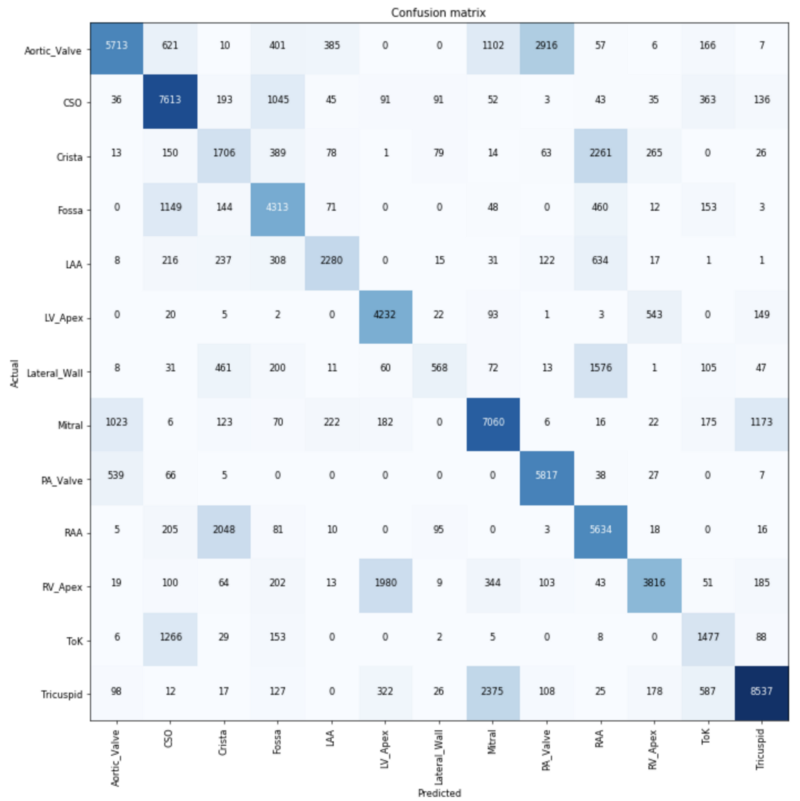
This has been a project I procrastinated on posting, but it is a fun one! Identifying different pieces of cardiac anatomy inside real human hearts. I made a longer post here on medium. (https://medium.com/@erikgaas/teaching-a-neural-network-cardiac-anatomy-f14f91a4c4bf)
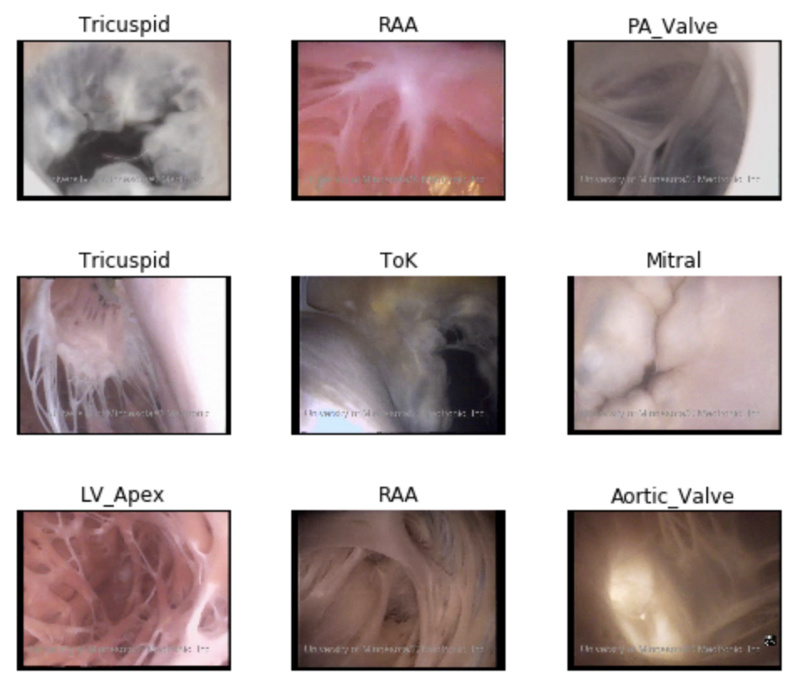
Above are different shots of camera inside a heart perfused with clear liquid. If you want to see videos of these regions in action, visit my lab’s webpage on cardiac anatomy. (http://www.vhlab.umn.edu/atlas/) I scraped the site’s videos and converted them to still frames.
Resnet34 does really well at the problem, and reveals some fun things about our dataset whether it be regions that happen to look similar, or simply are present multiple times in the same image.
Fun stuff! I did this before in keras back in the day. Fastai makes this so much easier and more satisfying.
7 Likes
Hey Guys,
I have created a github repository for the CV and NLP datasets that I have implemented using fastai on Google Colab.
Main Repo-https://github.com/navneetkrc/Colab_fastai
Most recently I did a project on my own dataset automating the KYC document classification task.
KYC Classification
You are welcome for your reviews and feedbacks.
3 Likes
(Black and white) image colorizer in self-contained notebook:
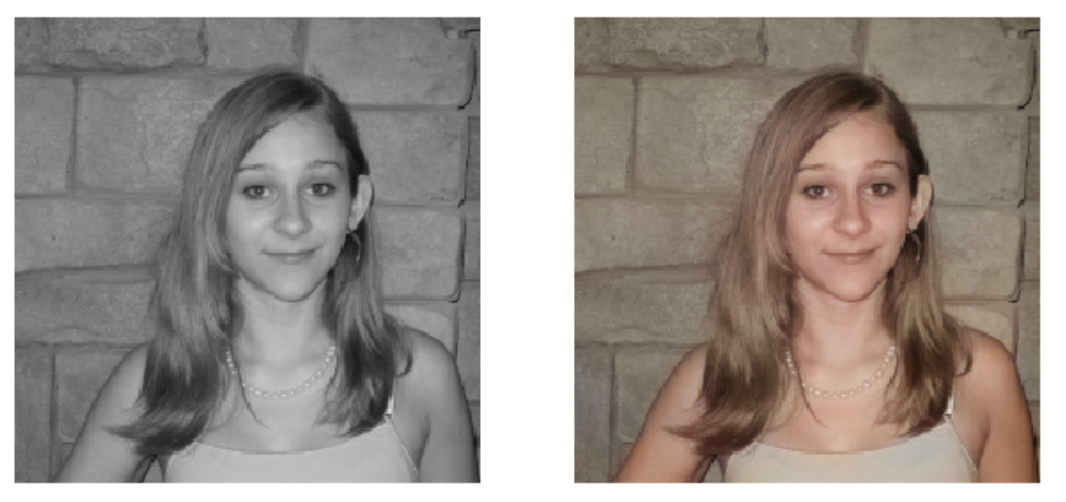
I used this project to teach a few high school student to use deep learning. I think it was fun because once the project (4 days) was over, they could still run the network in Google colab for inference and even “colored” the trailer of movies like Casablanca and Schindler’s list.
I also learnt a few things in the process:
- The network is just a UNet that predicts
CbCrcolor components, it minimizes MSE. Skin tones, sky, vegetation, sea, etc. which has consistent colors, the network does a pretty good job; however for things whose color varies wildly the network “does its job” minimizing MSE and predicts things close to (0.5, 0.5) which inCbCris gray. I am experimenting with GAN to make the network predict plausible colors not averages (grays). - I have two GPUs and even with 32 threads in my system the CPU was the bottleneck:
Although I use turbo-jpeg flavored PIllow, a cursory inspection ofsudo perf topreveals:
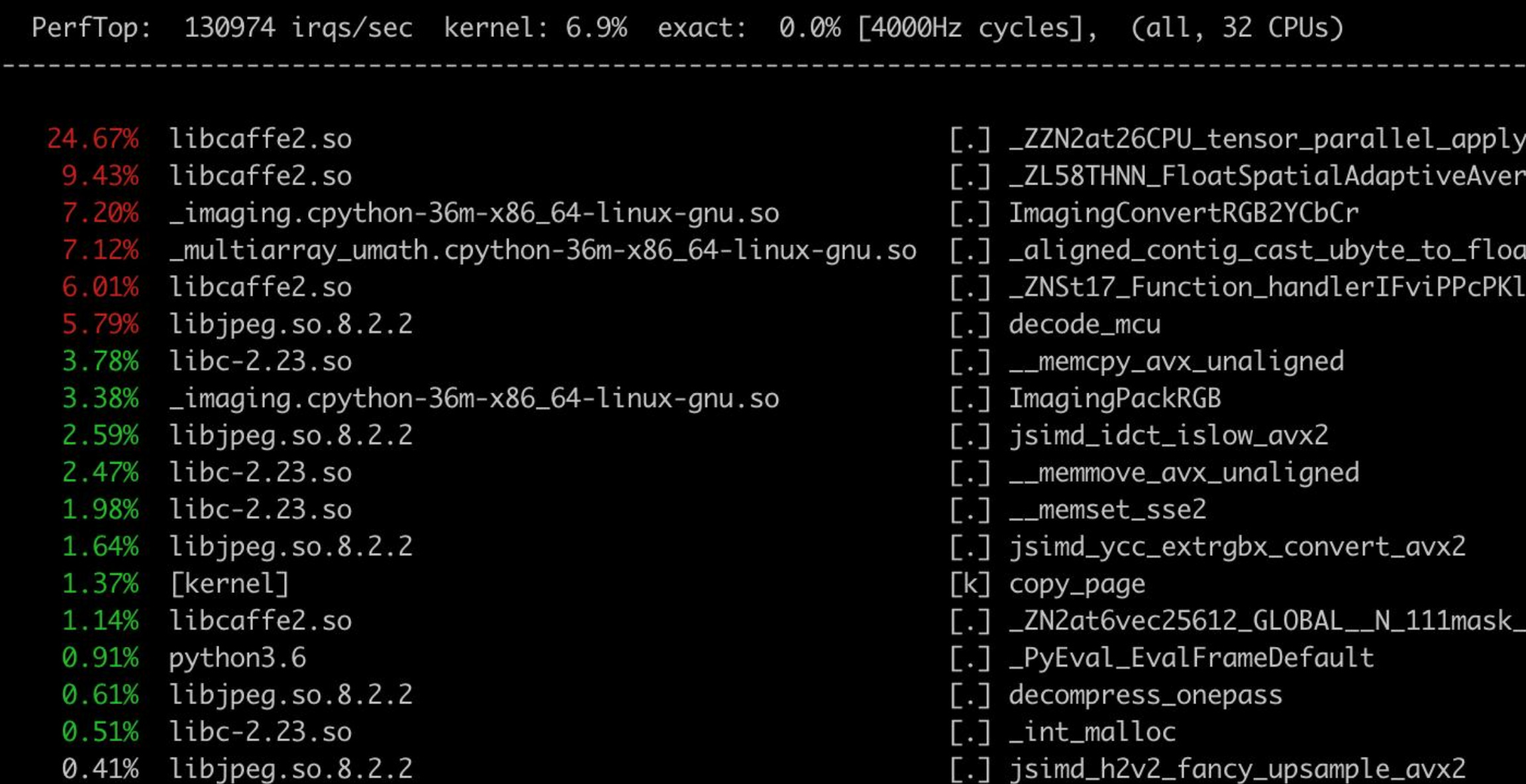
look at ImagingConvertRGB2YCbCr … it reveals a nice (albeit big in scope) opportunity for Fastai imaging models: most JPEGs are encoded in YUV colorspace with UV (equivalent to CbCr) components downsampled 2:1. When you open a JPEG file, the library (libjpeg or libjpeg-turbo) internally decodes YUV components, upscales UV if needed (most times) and then converts the result to RGB. In our case colorizer it’s a waste b/c we can just open the YUV natively and also make the Unet predict the native downsampled (2:1) UV components. For pretrained image models, it makes sense to do it in YUV nonetheless as shown here: https://eng.uber.com/neural-networks-jpeg/ - you get better NN and less CPU overhead processing. In Fastai it could be done by extending Image and training image models in the new colorspace, injecting 2:1 downsampled UV components in most modern architectures after the first 2:1 scaling.
14 Likes
Hi,
I work for an art studio that makes pottery plates with paintings on them. we had a website to sell the plates. on the site, each artist gets a page to introduce and sell her/his plates with her/his paintings. each artist has a unique style of painting but the plates are the same.
I wanted to make a recommender system based on image similarity of the plates.
I trained a resnet model and used hooks to get the activation outputs for each plate image.
then I used nearest neighbour algorithms to find similar images based on cosine metric.
as an example you can see the nearest image to this plate :

returns this:

as you can see the result are not bad at all!
the notebook is available in this github repo:Image similarity
(I would really appreciate your feedback)
14 Likes
I have taken my first MOOC in 2014, but fastai is a game changer for me. The level of participation is on a different scale. If fastai was so well-structured from the beginning, I probably would have learned less. Watching the evolution from v1 to v3, I have the chance to have a glance at how software is actually built
I have not accomplished anything big with deep learning yet, but I think this still worth a celebration.
100k view accomplished 
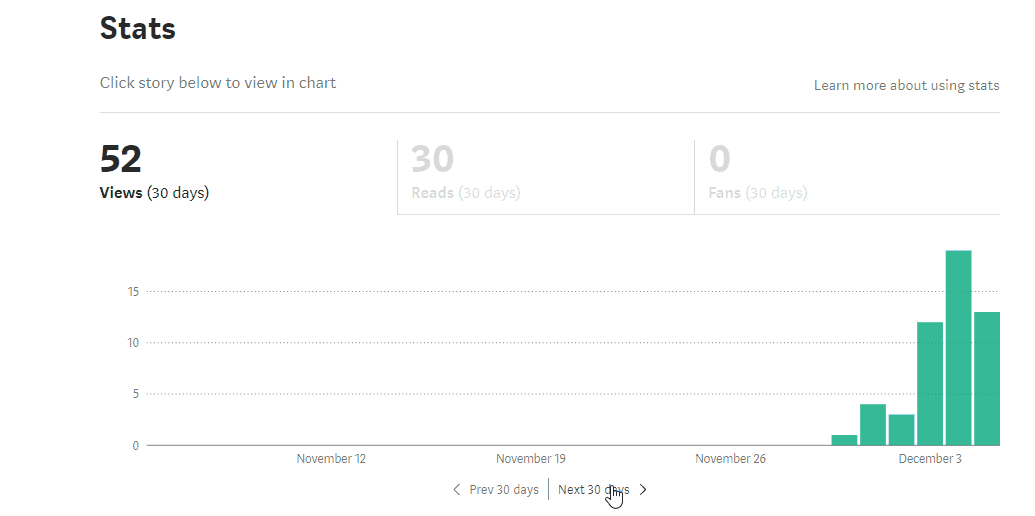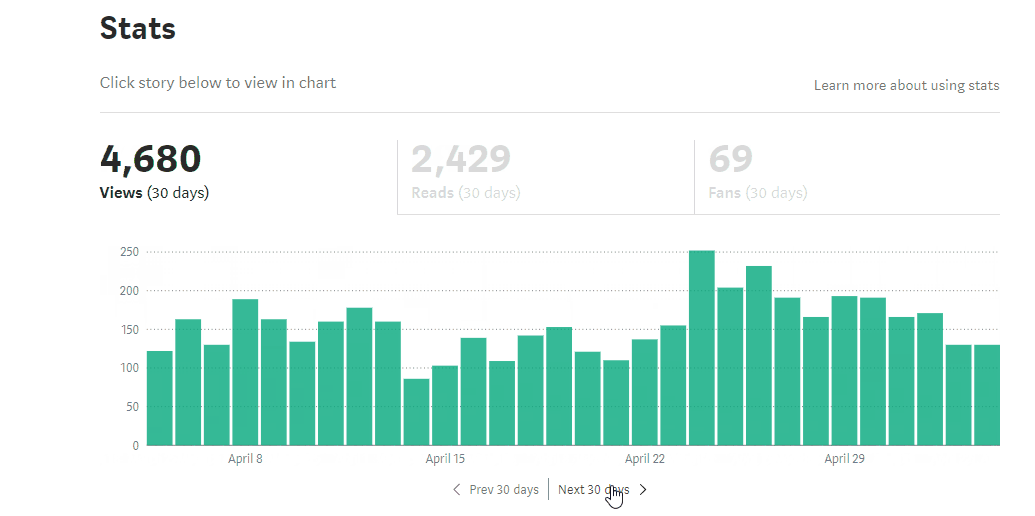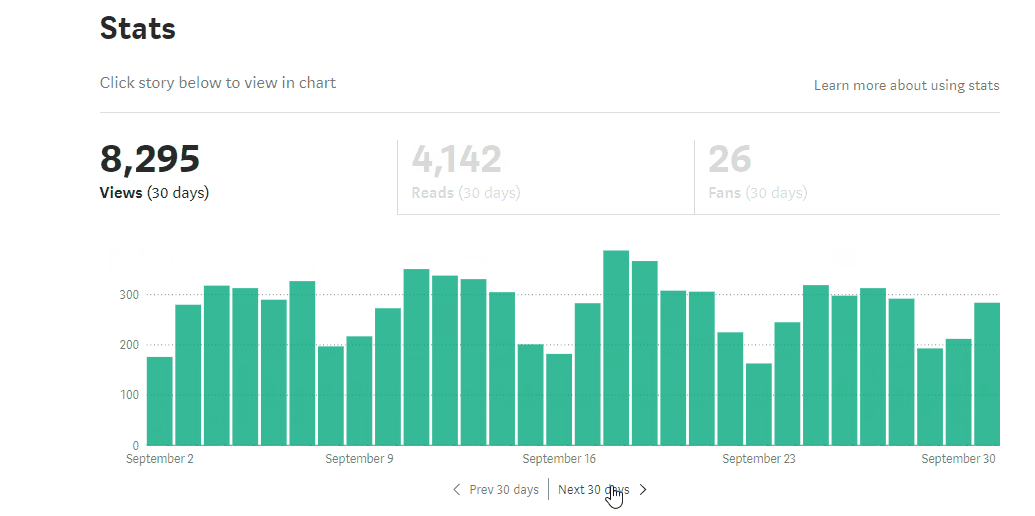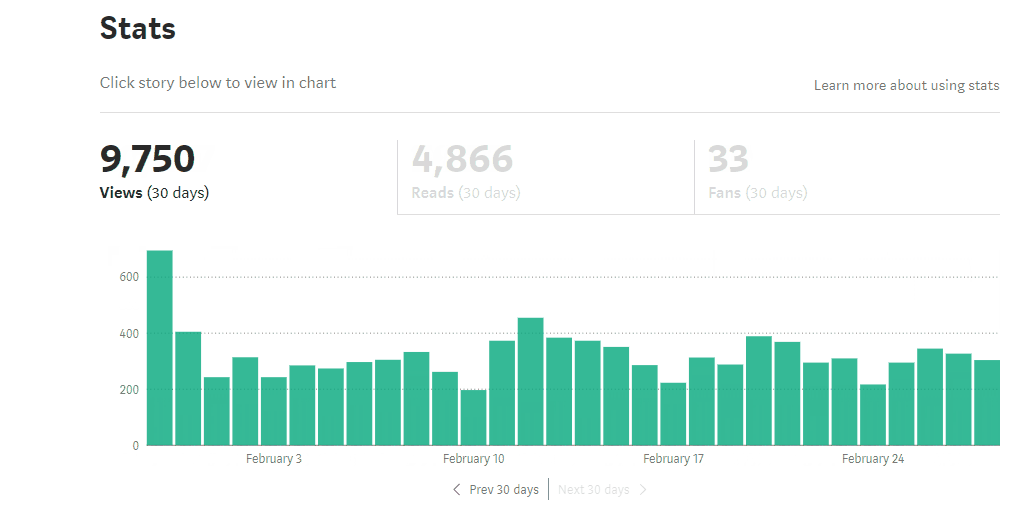
It all starts with a simple blog about how to setup fastai with GCP. Notice that there is a 2k view spike at 2018 Feb, it is all because of Jeremy’s retweet. Without this initial motivation, I probably would not continue to write.
I am very glad that I have written my first blog a year ago, it has a great impact on me including my way of working and mindset. I could not thank fastai enough. The more you dedicated, the more you learnt.
7 Likes
Just finished writing my first hands-on experience with FastAI and wrote a medium post about it.
This is about classifying malaria cells using CNN. I am just loving this library.
How I got a world-class Malaria classification model with FastAI within two hours.
Code can be found on my Github profile
1 Like
I made a simple widget for labeling image data.
It is heavily based on this text data labeler and the image cleaner from the fastai library. While it is not as polished as those, it does work!
Please try it out if you need to label some image data and let me know how I can make it better!
9 Likes
FreeCodeCamp asked me rewrite my project for medium. While it doesn’t have anything ground breaking for this group, it was a good experience in getting published online and hope it encourages you to submit your projects outside of the forums as well.
4 Likes
Hello!
A colleague referred me to get to know fastai and it is awesome! I brainstormed yesterday and was thinking about minority report, the way Tom Cruize interacts with the screens. Isn’t that the dream of every presenter? So I tried something small 3x25 imges of my pointing finger floating above my phone.
I created a pandas frame with a column for the filename and collumns for the approximate x and y positions. And just trained the thing to see what would happen. I expected somehow the (x,y) location to ‘stick’ with the image so that when I would predict with a new image, I would also get x and y parameters that corresponded to where my finger was.
It doesnt quite work that way  I get “Multicategory” and two 4 or 5 dimensioanl tensors. I tried to use their means but that was also not quite good. Anyway I had fun playing with this for some hours and if anyone has an idea to help out: please
I get “Multicategory” and two 4 or 5 dimensioanl tensors. I tried to use their means but that was also not quite good. Anyway I had fun playing with this for some hours and if anyone has an idea to help out: please 
regards, Jairo
1 Like
Hello  ,
,
As I advanced in the course, I wanted to improve my Simpson’s fine-grained classifier . Indeed, the model would not work if there were multiple characters in the image, as it would only output the name of the character it was the most confident about.
So I built a multilabel classifier (check out the link at the end of the post) able to recognize several characters present in an image. The most difficult part of the project for me was the conception of the dataset (combining images & labelling), as the training process was fairly similar to what I have done previously.
I would also like to give a shout-out to @balnazzar who has helped me a lot for this project through his tips about dataset creation and the fastai library 
3 Likes
Deploy PyTorch Models to Production via Panini
I always had a tough time deploying my model using Flask + Gunicorn +Nginx. It requires a lot of setup time and configuration. Furthermore, inferring the model with Flask is slow and requires custom code for caching and batching. Scaling in multiple machines using Flask also causes many complications. To address these issues, I’m working on Panini.
Panini
https://panini.ai/ can deploy PyTorch models into Kubernetes production within a few clicks and make your model production ready with real-world traffic and very low latency. Once deployed in Panini’s server, it will provide you with an API key to infer the model. Panini query engine is developed in C++, which provides very low latency during model inference and Kubernetes cluster is being used to store the model so, it is scalable to multiple nodes. Panini also takes care of caching and batching inputs during model inference.
Here is a medium post to get started: https://towardsdatascience.com/deploy-ml-dl-models-to-production-via-panini-3e0a6e9ef14
This is the internal design of panini
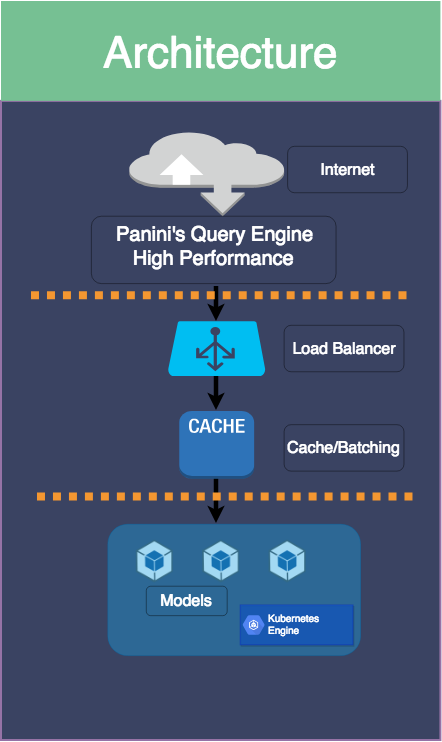
Let me know what you guys think!
7 Likes
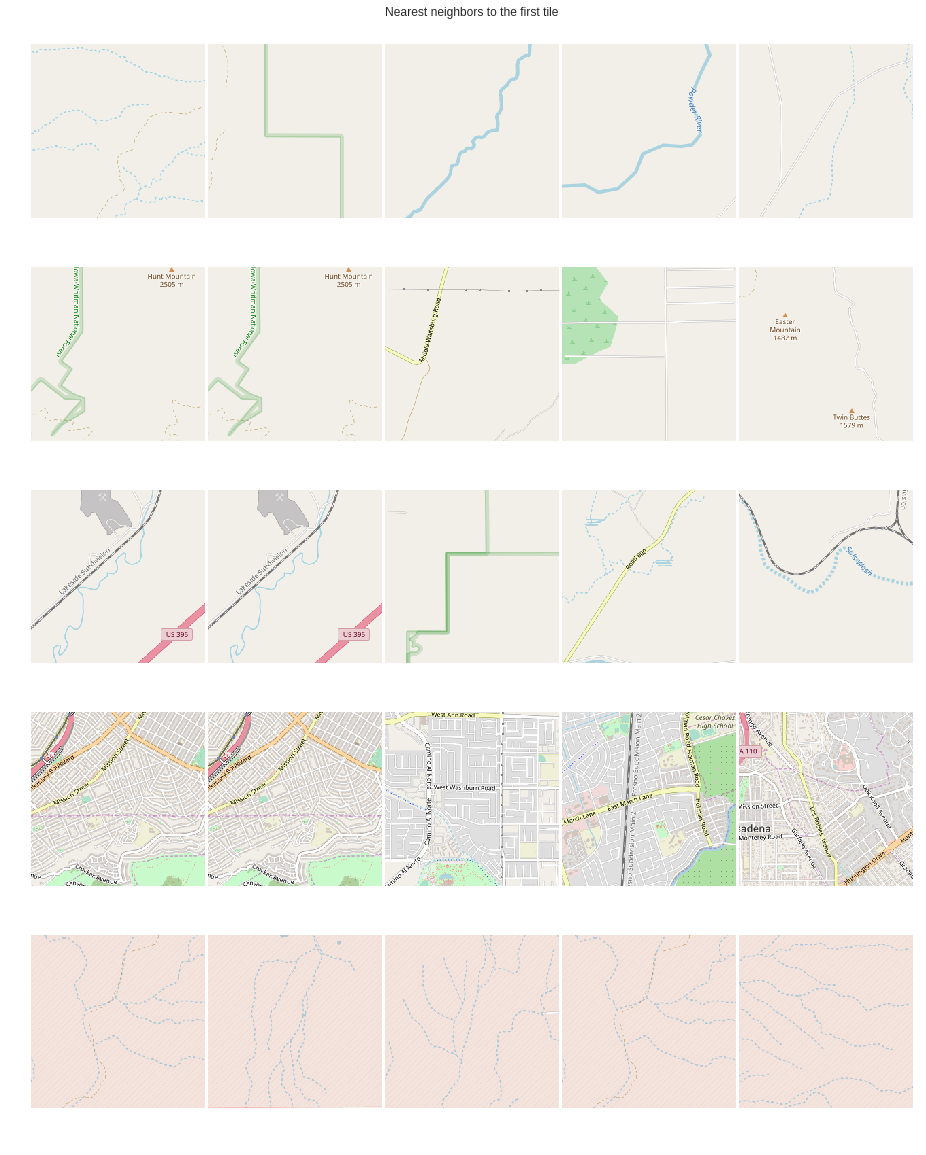
Hi,
I wanted to share with you my first blog post about my efforts building a semisupervised location to vector model based on this
Blog
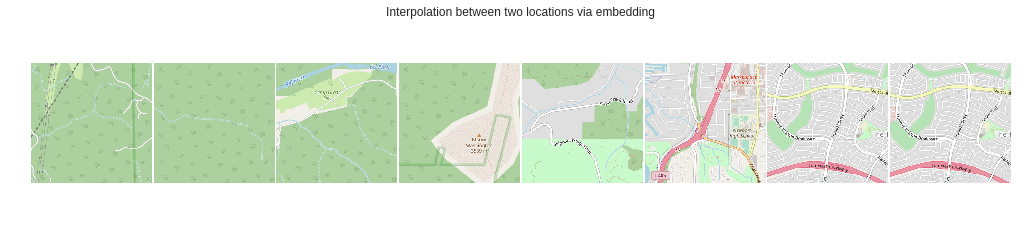
They took about 2 weeks to train on data generated from openstreetmap. I made quite a few changes from their implementation and added support for mixed precision using plain pytorch. I wrote a blog post about it here: and you could find the source code here: Loc2vec
This picture below shows interpolation between two locations by interpolating the embedding and finding the nearest location.
This picture shows nearest neighbors based on image queried (first column)
I’ve done this in plain pytorch as I took this course when it was taught with keras and pytorch. I’d like to port it to fast.ai to use some of the learning rate / stochastic weight averaging / densenet etc. Specifically, I got stuck with data loading. ( I didn’t watch the latest version of the course, and the answer could be just watch lecture x).
This is my first blog post, any feedback is appreciated. Also, on the technical front, how would you insert a video (say images/tsne.mp4) in the github Readme.md?
7 Likes
Hi
I’ve always been fascinated by paintings and different styles of them. I’ve been working on a project to compare baroque paintings with ancient Greek pottery paintings.
Baroque art is characterized by great drama, rich, deep color, and intense light and dark shadows as opposed to Greek paintings where Figures and ornaments were painted on the body of the vessel using shapes and colors reminiscent of silhouettes.
I used a CycleGAN to experiment and see what features in each style were more important for the model to turn the paintings from one style to the other one.
as an example:
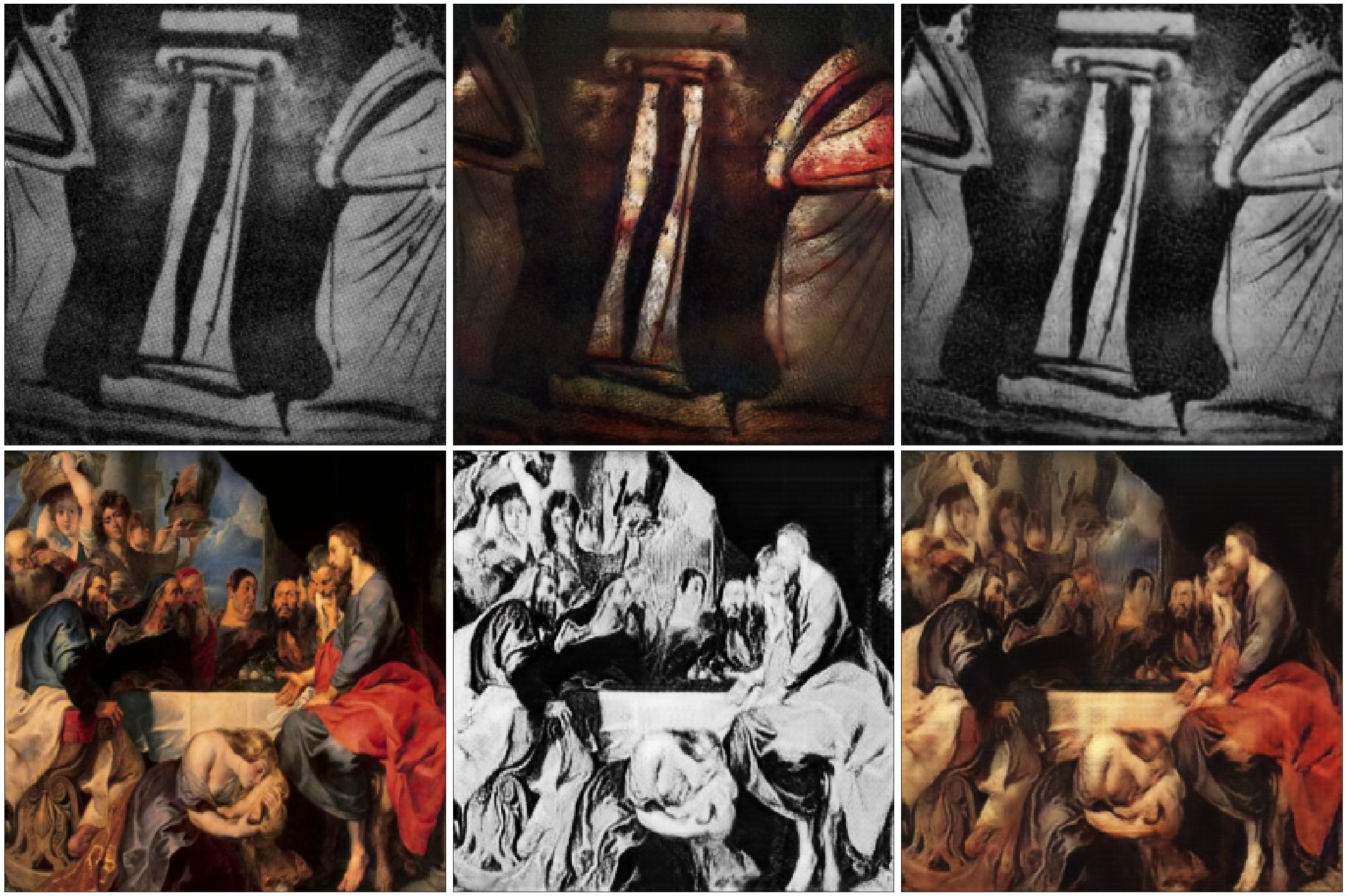
you can see the generator of baroque paintings tries to capture deep color contrasts and shadows features. but that’s a hard job since the Greek paintings usually represented as a solid shape of a single color, usually black, with its edges matching the outline of the subject. but the Greek generator almost captures the main features as dark shadows and solid edges.
The training took about 6hours on a single GPU. the notebook is available in the github repo: CycleGAN
I would really appreciate your feedback.
4 Likes
Don’t judge a book by it’s cover!
(Let my CNN do it for you  )
)
I just finished my second project: training a resnet34 on 15 different classes of book covers (




 ) and I’m super excited to share my results! A few thousand images, a bit of data grooming and architecture tweaking, an hour of training, and it’s pretty stable around 45% accuracy! (Random guessing would be 7%.) I believe a good bit of this is due to me choosing somewhat ambiguous/overlapping classes.
) and I’m super excited to share my results! A few thousand images, a bit of data grooming and architecture tweaking, an hour of training, and it’s pretty stable around 45% accuracy! (Random guessing would be 7%.) I believe a good bit of this is due to me choosing somewhat ambiguous/overlapping classes.
And now for the fascinating results:
-
Easy: Romance Novels and Biographies have an unambiguous stand-apart style
-
Runners Up: Fantasy, Cookbooks, and Children’s Books are pretty straightforward, too



-
Most Confused: Mystery x Thriller x Crime, and SciFi x Fantasy (hard to draw the line sometimes)
-
Hardest: SciFi turns out to be a mechanic more than content, and can scan as many subjects

-
WTF: Western is a genre dedicated to tales of cowboys, but it can also crossover fabulously…





If anyone has suggestions for breaking through my personal accuracy asymptote, I’d love to chat!
6 Likes