(Black and white) image colorizer in self-contained notebook:
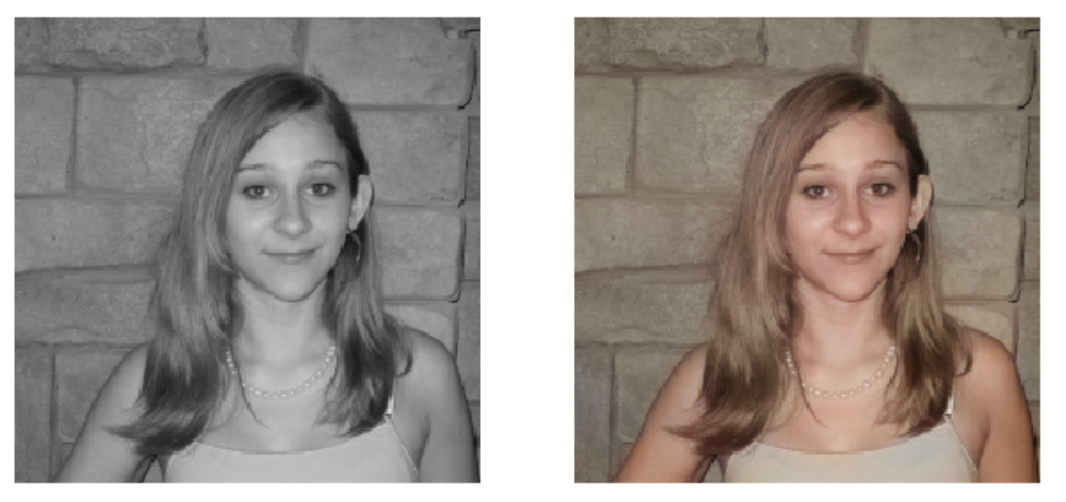
I used this project to teach a few high school student to use deep learning. I think it was fun because once the project (4 days) was over, they could still run the network in Google colab for inference and even “colored” the trailer of movies like Casablanca and Schindler’s list.
I also learnt a few things in the process:
- The network is just a UNet that predicts
CbCrcolor components, it minimizes MSE. Skin tones, sky, vegetation, sea, etc. which has consistent colors, the network does a pretty good job; however for things whose color varies wildly the network “does its job” minimizing MSE and predicts things close to (0.5, 0.5) which inCbCris gray. I am experimenting with GAN to make the network predict plausible colors not averages (grays). - I have two GPUs and even with 32 threads in my system the CPU was the bottleneck:
Although I use turbo-jpeg flavored PIllow, a cursory inspection ofsudo perf topreveals:
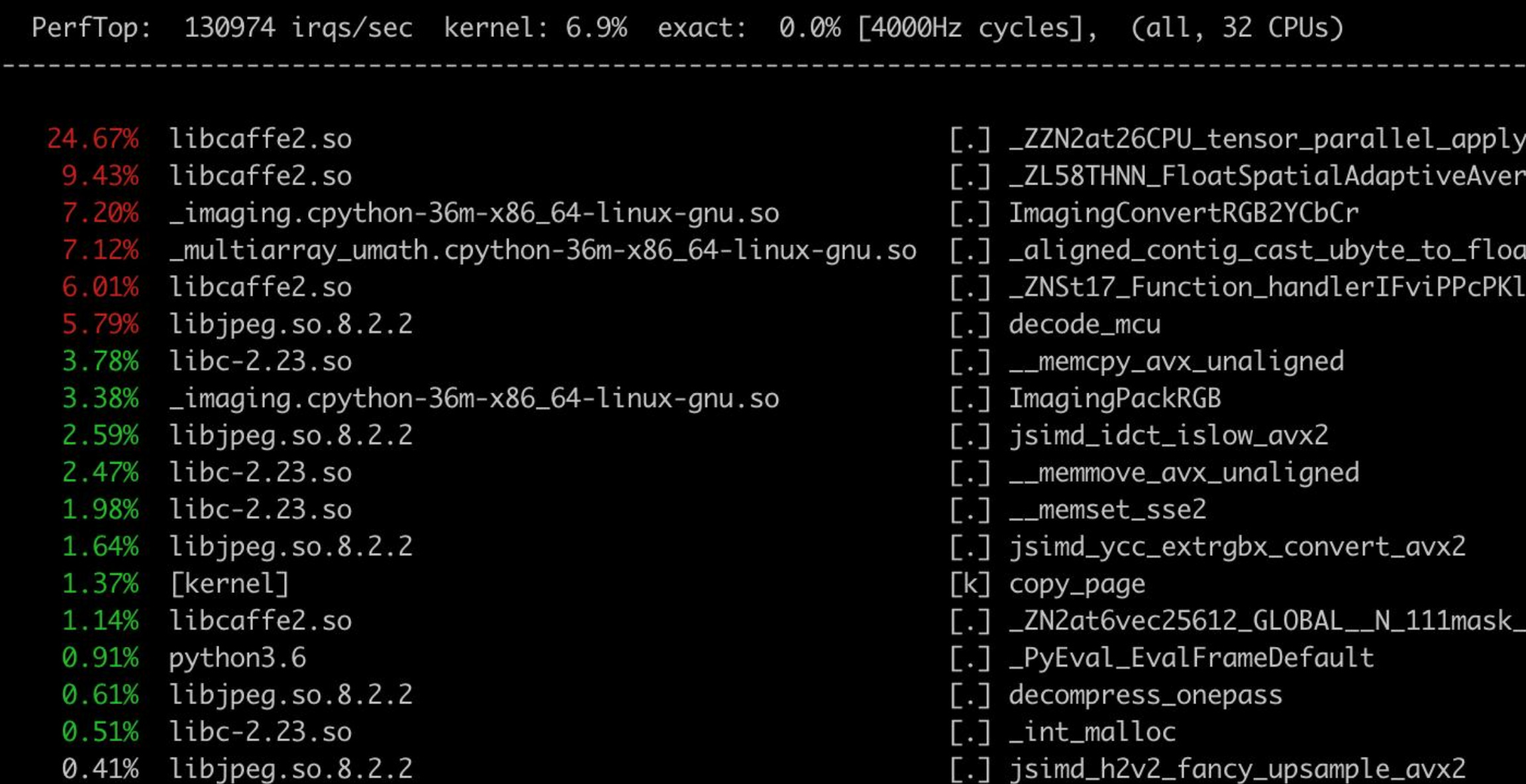
look at ImagingConvertRGB2YCbCr … it reveals a nice (albeit big in scope) opportunity for Fastai imaging models: most JPEGs are encoded in YUV colorspace with UV (equivalent to CbCr) components downsampled 2:1. When you open a JPEG file, the library (libjpeg or libjpeg-turbo) internally decodes YUV components, upscales UV if needed (most times) and then converts the result to RGB. In our case colorizer it’s a waste b/c we can just open the YUV natively and also make the Unet predict the native downsampled (2:1) UV components. For pretrained image models, it makes sense to do it in YUV nonetheless as shown here: https://eng.uber.com/neural-networks-jpeg/ - you get better NN and less CPU overhead processing. In Fastai it could be done by extending Image and training image models in the new colorspace, injecting 2:1 downsampled UV components in most modern architectures after the first 2:1 scaling.