Cloud Classification
While revisiting the earlier lessons of Part 1 using the new version of fastai, I tried to train a model to classify the type of cloud in the sky based on appearance (cumulus, stratus, cirrus). They look something like this:

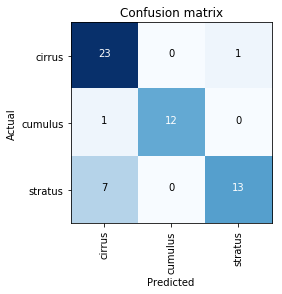
I was able to get a good enough accuracy but the model seems to be confused between Stratus & Cirrus clouds. On visual examination, I could see that these two clouds are indeed difficult to distinguish between, even by a human at the first glance. Can the model do better?
Here’s a link to my research notebook:
Cloud Classification Research Notebook
Cloud Classification Repo
Bonus Inspiration: ‘Quick, Draw!’ for Clouds
As I was going through pictures of clouds, it occurred to me that as a kid I used to look at the sky when the storm was gathering and tried to imagine the clouds as an approaching army of mythical beasts. Turns out it is indeed a real hobby for some people: The joy of cloudspotting: 10 incredible visions in clouds

“Is that a UFO?”
Can we make something like Quick, Draw! but for clouds, where a model learns to recognize objects in clouds instead of doodles and drawings?