Hello alvisanovari,
How do you get the data,Can you share it?Thks
Thanks:狞笑:
Hey … i am working on a project where in i want to create a prototype on a microcontroller that will be attached on a buggy robot with a camera to detect road traffic signs and alert the driver on the upcoming signs …i trained my model on GTSRB (german road sign dataset) and got pretty hogh accuracy with 42 different signs…now i want to do object detection on road sign…thats my first doubt…then can rasberry pi do the image processing,detection,classification
?? and lastly how to proceed form here…i used pretrained resnet architecture and now how to deploy it on rasberry or any other microcontroller???
thank you
If you ever wanted to dive deeper into the actual implementation of neural networks without jumping from one PyTorch definition to the other, see numpy-dnn. I’ve spent some time putting the basic building blocks of convolutional neural networks into one single place. This repo shows how to write neural networks in a modular way, calculate gradients, and automatically check whether the network has been built properly. Plus this vectorized NumPy implementation works amazingly fast. If you’ve got new ideas or want to add support, e.g., for RNNs and GPU, you are welcome to contribute!
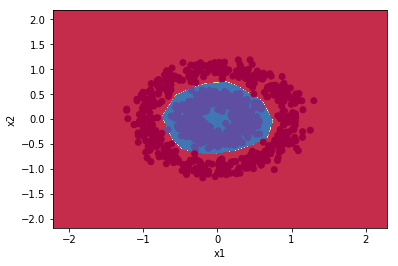
7 Likes
Hi @jeremy and everyone!
I was working on an assignment and I published the same as a Kaggle Kernel. It’s a multiclass food classification problem using FOOD-101 dataset which has 101 classes of food. Since it takes too long to train on all 101 classes, I trained the model on 3 classes first and then trained on 11 classes separately to validate and confirm that the model does well even with more number of classes.
The first model trained on 3 classes can classify apple_pie / pizza / omelette. As I was experimenting with different inputs, I gave the model an image which has both applie pie and pizza.

What I noticed was, when the objects in image are flipped vertically, the model changed its output classification from one class to another.
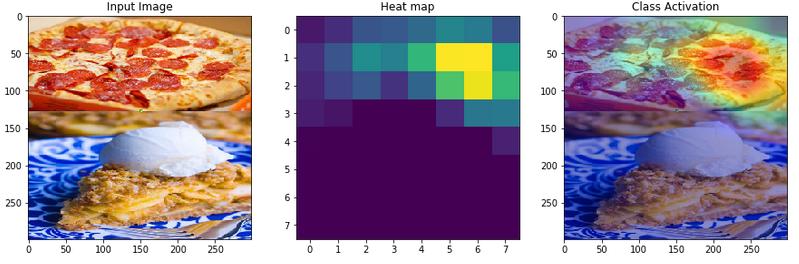
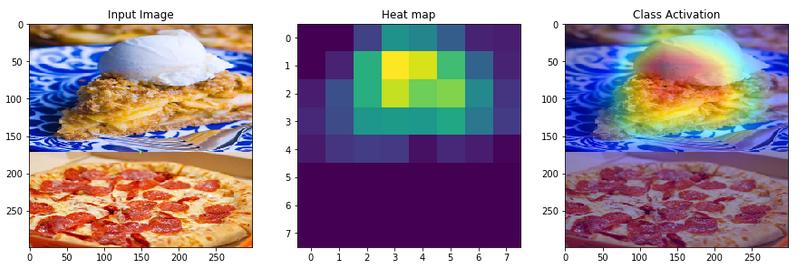
I tried the same with horizontal flip. In this case, the model gave the same output and also with almost similar confidence(92% vs 90%)
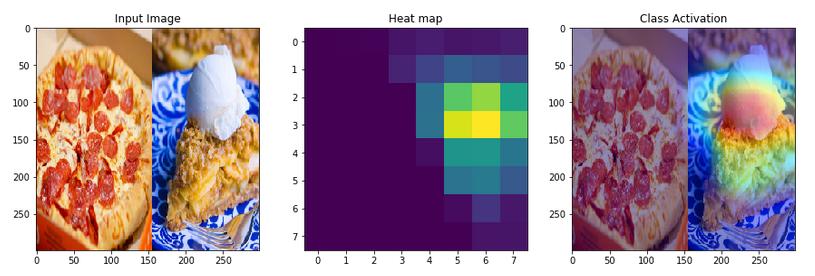
I am yet to try this with more images and from different classes. I am curious to know what the reason could be in both cases where the model flipped its output for vertical flip and gave out the same class for a horizontal flip.
Here’s the kernel - https://www.kaggle.com/theimgclist/multiclass-food-classification-using-tensorflow
Note - I used TensorFlow and Keras for this assignment.
Thanks,
1 Like
I looked into Twitter. Too many privacy issues I didn’t want to deal with. I will be developing a website. Will post here when it’s done.
Hey where did you find the data set and does those image have the categorized names already so that you can use the regular expression like lesson 1?
Please don’t tag Jeremy unless it’s absolutely needed (it’s in the forum rules).
Having said that, it looks like your model is recognising Slices for its classification. Weird
1 Like
Interesting @avinash3593 - it feels like it is scanning from top to bottom and sticking with what it finds first. I’d be keen to know what your other tests reveal.
2 Likes
I’m working on fake news classification based on lesson3-imdb.ipynb. I’ve run a few variations on it but now am trying a Kaggle dataset augmented with some additional fake news articles. Now I keep hitting this error when trying to tune the classifier:
learn_c.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-41-a7eaf4cbd03b> in <module>
1 # 2019-02-17 12:43:53
----> 2 learn_c.lr_find()
/opt/anaconda3/lib/python3.7/site-packages/fastai/train.py in lr_find(learn, start_lr, end_lr, num_it, stop_div, **kwargs)
29 cb = LRFinder(learn, start_lr, end_lr, num_it, stop_div)
30 a = int(np.ceil(num_it/len(learn.data.train_dl)))
---> 31 learn.fit(a, start_lr, callbacks=[cb], **kwargs)
32
33 def to_fp16(learn:Learner, loss_scale:float=512., flat_master:bool=False)->Learner:
[snipped out]
/opt/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in batch_norm(input, running_mean, running_var, weight, bias, training, momentum, eps)
1424 size = list(input.size())
1425 if reduce(mul, size[2:], size[0]) == 1:
-> 1426 raise ValueError('Expected more than 1 value per channel when training, got input size {}'.format(size))
1427 return torch.batch_norm(
1428 input, weight, bias, running_mean, running_var,
ValueError: Expected more than 1 value per channel when training, got input size [1, 1200]
I initially thought it was the lr_find function itself, but lr_find works fine when I build the language model before the classifier, so this seems related to the data I’m using for data_clas, which is a subset of the full dataset (to get a balanced ds for data_clas).
I have no idea what the the err message (ValueError: Expected more than 1 value per channel when training, got input size [1, 1200]) means, so I’m hoping one of you does! I snipped out most of the traceback to be more concise here but please let me know if it’s needed…
lr_find runs all the way to the end (showing 99+ % completion, and note the first line saying it completed) and then throws this error, if that clue helps any.
thanks!
Pls check this tweet out and the link:
Haven’t read the work in detail, but it seemed to say bees can be trained to do math! I thought of your counting neural net.
I will be trying next with more images and from different classes. I didn’t yet look into the activations at the end of the network. Will try these things next and post an update.
Following lesson 2, I created in a kaggle kernel a classifier for horse breed colors. There are 4 classes: palomino, buckskin, pinto, white. My overwhelming experience so far is that of the importance of having a quality dataset.
I had to massively clean the data as there was a lot of noise: images of toys or other non-horse items (white horse inn for example), of objects with horses on them, multiple horses of different colors on the same image, watermarks, parts of horses, light which makes it hard to see the color of the horse, mixed breeds, etc. Still, the resulting dataset is not completely clean.
I was able to get an error rate of 8%.
I found using a smaller batch size worked better to avoid overfitting (not clear exactly why).
I also found I tended to get different results every time I trained, I guess because of randomness.
What did not work was unfreezing and trying to train a bit more as I was not able to get a lower loss.
I suspect in the end I did not have enough data (about 130 of each class in the training set after cleaning) and that data was too heterogeneous.
The data is organized in the imagenet folder structure, but I created a script to parse it into train/test sets. I belieev I linked to the site I got the data from in the original post
I recently published my first medium article the matrix operations done under the hood in GRUs(choosen because of a project I’m working on). The links to detailed notebook on GitHub is included in the post.
6 Likes
I just finished my first model and am really happy with it–recognizing keystrokes on a laptop using only the microphone. Stoked about fast.ai and its incredibly robust framework that allowed me to get 92% accuracy on these 63 classes with just a few hours of gradient descent.
I’m using Kaggle kernels, but I can’t figure out how to download/upload my resnet weights to avoid losing all the work after 6 hours. If you know how, could you drop me a hint? Also, looking for fast.ai friends in Boston, if anyone wants to get coffee!
On to my next project…
11 Likes
Also, does anyone know if there is a resnet with pretrained weights for spectrograms, ala model zoo? They seem sufficiently different from normal images that unfreezing the whole model is the best strategy, but they seem quite similar to each other, and there could probably be a useful set of low-level layer weights that could be consistent and transfer-learnable.
If you know of one, could you point me towards it?
If you know there isn’t one, do you want to work with me to create it?
Poisonous plants are dangerous for unsuspecting individuals such as children. Especially the plants that are common in backyards. There are many casualties due to lack of supervision of gardens in public and private areas.
One solution to this problem is image classification using deep learning. Keeping this in mind I made a custom data set of the poisonous plants that are common in our home area. I got a list of these from here:
I have made the data set available on Kaggle:
https://www.kaggle.com/nitron/poisonous-plants-images
Using fastai, I have successfully created an Image classifier for classifying a plant’s image into 8 categories of poisonous plants. The classifier have 98% accuracy on the current data set. Here is the Kaggle kernel:
https://www.kaggle.com/nitron/poisonous-plant-classifier
This is one of the first step towards the solution. Next I will make a web app for demonstrating the capabilities of the current model.
Any helpful tips are welcome 
3 Likes
I just finished my first model and am really happy with it–recognizing keystrokes on a laptop using only the microphone.
Nice! Did you collect that data yourself? How well does it generalize? Does it matter where the microphone was compared to the keyboard? Does it work with multiple keyboards or just the one the sounds were recorded from?