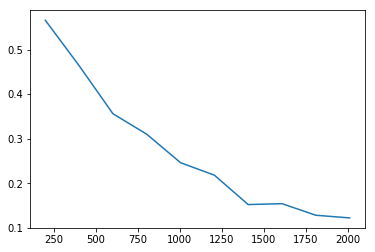
Here’s an updated animation showing 10 epochs with no pre-training (one snapshot of lr_find every 10 batches).
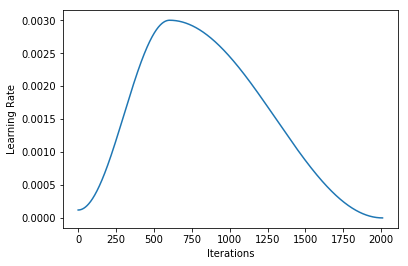
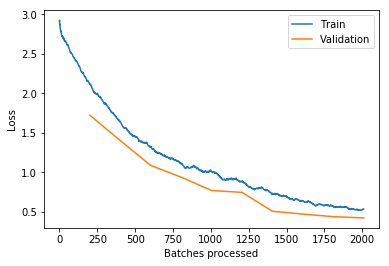
It stayed pretty much in the zone! So maybe there’s not actually that much room to improve the LR schedule.
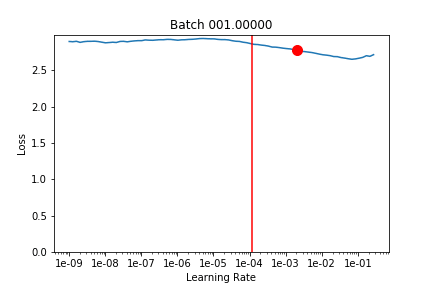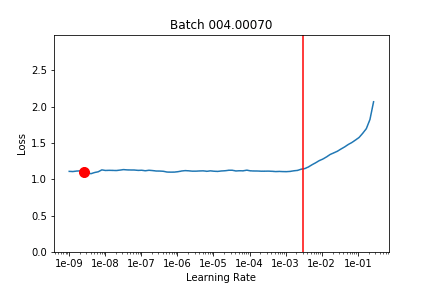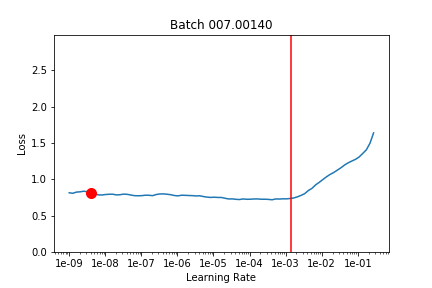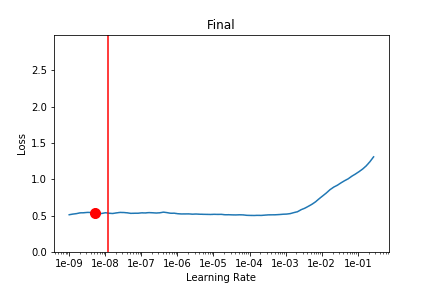
It looks like 1e-3 (which is what lr was set at) would have been good but it overshoots it a bit according to learn.opt.lr – not sure if this is an issue with opt.lr or learn.recorder because they still don’t seem to match up.)
LR
Loss
Error Rate