Today I was thinking about how you might go about discovering a better learning rate schedule.
The first step in my experimentation was exploring what’s going on with the relationship between the learning rate and the loss function over the course of training.
I took what we learned about callbacks this week and used that to run lr_find after each batch and record the loss landscape. Here’s the output training Imagenette on a Resnet18 over 2 epochs (1 frozen, 1 unfrozen) with the default learning rate. The red line is the 1 cycle learning rate on that batch.
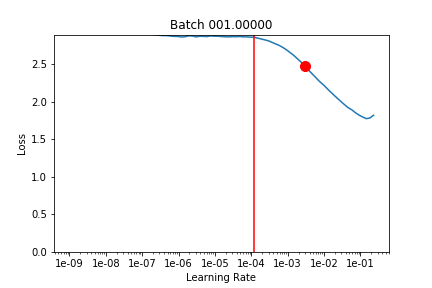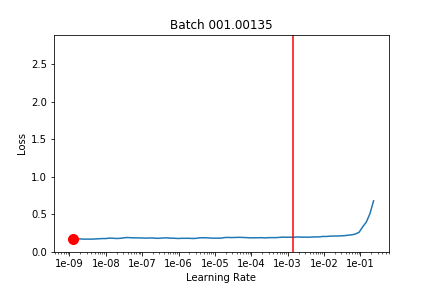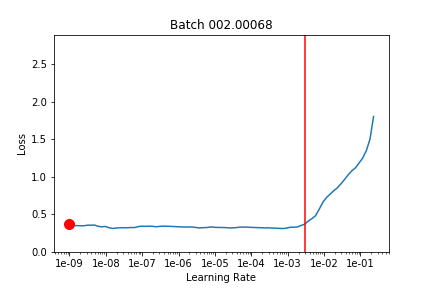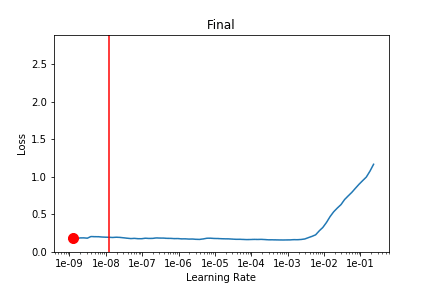
And (via learn.recorder) the learning rate schedule, and loss for epoch 1 (frozen) and 2 (unfrozen):
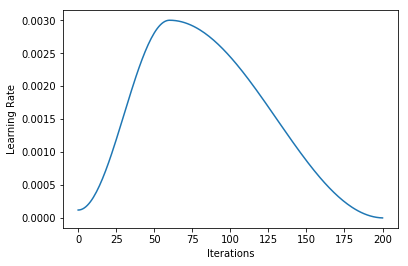
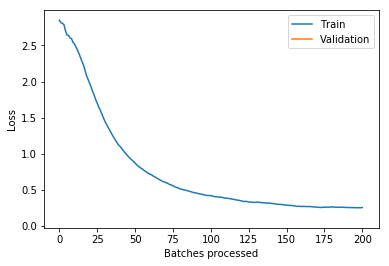
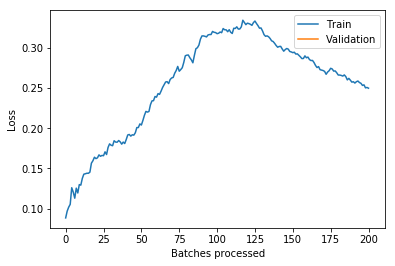
I’m not quite sure what to make of it yet. I think maybe if you could have your learning rate schedule dynamically update to stay just behind where the loss explodes that might be helpful (in the unfrozen epoch I had my LR a bit too high and it clipped that upward slope and made things worse).
Unfortunately it’s pretty slow to run lr_find after each batch. Possible improvements would be running just a “smart” subset to find where the loss explodes and to only run it every n batches.
Edit: one weird thing I found was that pulling learn.opt.lr returns a value that can be higher than the maximum learning rate (1e-3 in this case) – not sure why this would be when learn.recorder.plot_lr doesn’t show the same thing happening.