I made an app to classify images of sea fishes. For the project I ran a 34 resnet on a database that has 44,134 images classified in 44 fish categories (for the moment, as I manage to increase my database I will increase the fish species)
The project was deployed with mybinder. The difference with the app shown in session 3 is that instead of using a jupyter notebook and voila, I used streamlite. The link to the project can be found here and the github repo can be found here.
I just published my project on TowardsDataScinece. I used fastai v2 and experimented with Chest X-ray dataset on kaggle and I got 100 percent accuracy on the provided validation set (val set for this dataset is rather small but its what others used on Kaggle) which compared to other notebooks on Kaggle is the best result on this dataset and higher than others. Click here to see the post.
I would be really happy if you let me know your comments about it
wow. it took a lot longer to deploy this, than to train it.
First, I tried to deploy on Binder, but it seems that it does not work. I checked some of the ones that should work, but none does anymore. It seems broken.
However, behold the “What game are you playing” classifier:
a little classifier, that can detect what game you play, from a screenshot.
on Heroku the slug size is 935MB with the requirements from the course page and only the bear classifier example with a .pkl file of 46MB.
Hi ringoo hope your having a fun day!
Well done for persevering, like you, I think the most difficult bit about creating any classifier model, is deploying it online easily at little or no cost, especially if one is still waiting to make their millions from it (pity the link makes you have to log in to see the model ).
@joedockrill Thank you for your comment. Yes, I used the instructions. The pytorch version in the Procfile is definitely the cpu version. I just copied it from the instructions.
It seems that I included the wrong repository on heroku and it used the myBinder requirements. Now that I have repeated all the steps, it seems to work.
I have created a separate repository for the heroku deployment: https://github.com/mesw/whatgame3.git, if you want to have a look at the files. Now the slug is only 368MB. Nice!
If you would like to take this little experiment for a spin, you can find it here:
too bad, there is a voila error (the same as with myBinder) and it does not work.
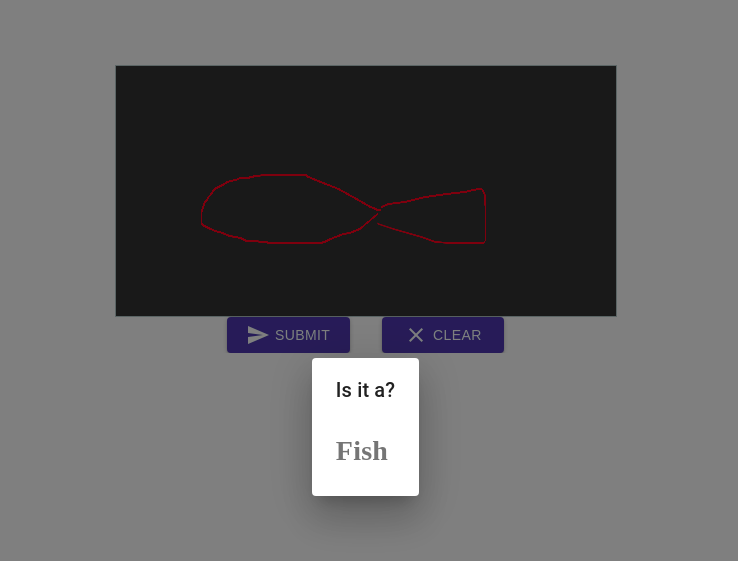
Guess the Doodle App
I’ve created this App based on the knowledge from Lesson 1 &2, completely in Jupyter Notebooks giving some Material UI touch to the App.
Got inspired by Google Draw and built one of my own using FastAIV2.
Currently supports 5 Doodles (bird,cup,dog,face,fish).
Please do give it a try.
Hi hitchhicker30 hope all is well!
A great little app with an original front end very different from the most common starter code classifier app.
Good work.
Cheers mrfabulous1
Hi everyone, I released my article on end to end image classification last week.
I have tried to cover the entire spectrum, right from gathering data, cleaning it, training a model to creating an app, by taking an example of a Guitar Classifier which discriminates between Acoustic, Classical and Electric Guitars.
Let me know what you think about it
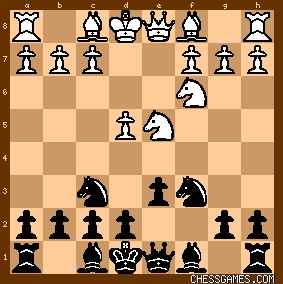
Hey, glad you like it! For your image, the model expects it to be from white’s perspective (white pieces at the bottom), I should have mentioned that. I should really add a user input for black/white perspective, but this would require collecting some data from black’s perspective.
By the way, this might explain something odd about your diagram: the position is clearly from black’s perspective but the notation on the edge of the board is as though it were white’s. Did you recognize the image and then load the FEN back into chess.com? If so, I guess the model worked, but you’re going to have some unexpected behavior… your pawns will be moving backwards
In answer to your questions…
Segmenting then classifying. I segment in the simplest, most obvious way possible: divide the vertical and horizontal dimensions by 8 and slice into 64 squares. This is why the image needs to be cropped exactly to the board: otherwise the squares will be off. Of course, it’d be better to be able to find the board in a larger image, but I haven’t implemented this. Then I run a standard image classifier on the sliced square images.
I believe I labeled 20 boards from each of lichess, chess.com, and chessbase (1 board -> 64 squares). I also set up a pipeline to generate synthetic data using python-chess, which looks to be the same piece set as lichess. Can’t remember if I used this in the latest model… Stay tuned for github repo/blog post
My training set was color images of whatever the default is for lichess, chess.com, and chessbase, so it should work best with those.
Hi guys,
I’m posting my first paper as first author
We used ULMFit to train a model to generate molecules similar to the ones tested for SAR-CoV-1 and then fine-tuned a classifier to classify molecules against the main protease (Mpro) of SARS-CoV-2.
Some main findings:
ULMFit can generate high proportions of valid, unique and novel molecules. This is in sharp contrast with other generative models described in literature. While some authors describe very low validity for LSTM/GRU/RNN models, others describe good results that were even better after using data augmentation. In our study, we showed that selecting the right sampling temperature can help users generate more than 99% valid molecules, even without data augmentation, that are also unique and novel compared to the training set.
We showed that ULMFit can approximate the chemical space of the training set. When comparing the distributions of physicochemical descriptors, the generated molecules were very similar to the training set. In addition, we noticed minor (e.g., changing one atom for another) and major (e.g., removal or addition of whole parts of a molecule). This suggests that ULMFit can be used to generate new chemical matter. The potential of this for drug discovery is still not fully understood, but it could be interesting for I.P analysis.
Our classifier did a pretty decent job and outperformed Chemprop, a message passing neural network that was trained with the same dataset. The training set was highly imbalanced, with only 265 active molecules in a ocean of 290K molecules. The training set was the bottleneck here, but I’m sure we can train better models as soon as new, high quality data is made available for Mpro inhibitors.
We generated a library of molecules and classified it using our classifier. The predicted actives were filtered and submitted to molecular docking, in order to predict it’s binding mode on Mpro. Surprise, surprise! The top-20 predicted actives were very similar to known Mpro inhibitors. In addition, the binding mode also similar to the experimental interaction between known inhibitors and Mpro described in protein-ligand crystals.
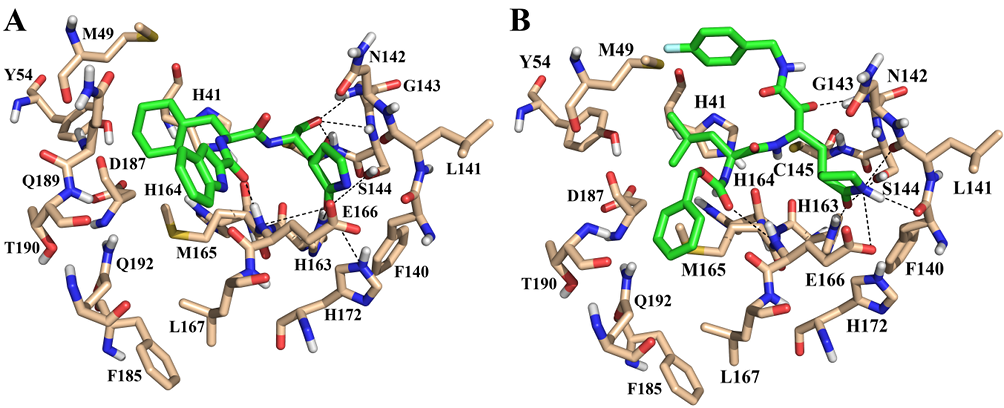
Here’s a figure. Mpro aminoacids are shown as bege sticks and ligands as green sticks. A) Known inhibitor and B) generated molecule
We are also expanding this approach for other protein targets and prediction settings. In addition, we will test the predicted actives against Mpro to check if our model can be useful to guide drug discovery for SARS-CoV-2.



 on Heroku the slug size is 935MB with the requirements from the course page and only the bear classifier example with a .pkl file of 46MB.
on Heroku the slug size is 935MB with the requirements from the course page and only the bear classifier example with a .pkl file of 46MB.
 from it (pity the link makes you have to log in to see the model
from it (pity the link makes you have to log in to see the model  ).
).