Guess the Doodle App
I’ve created this App based on the knowledge from Lesson 1 &2, completely in Jupyter Notebooks giving some Material UI touch to the App.
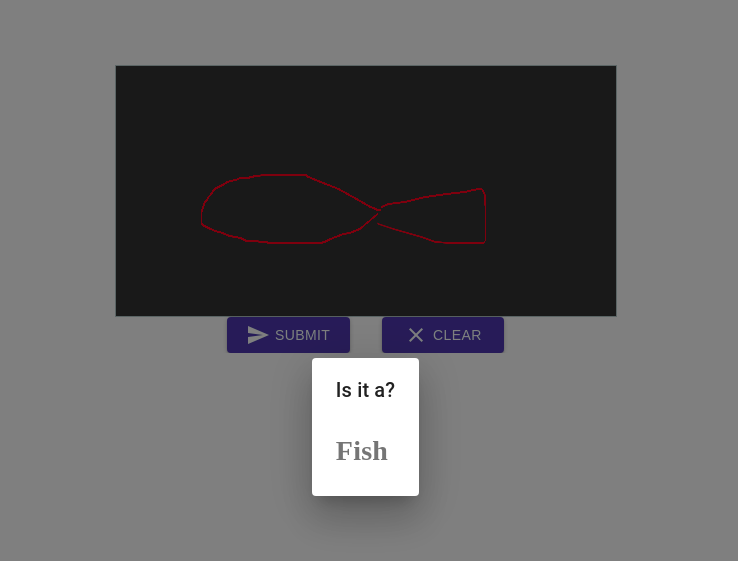
Got inspired by Google Draw and built one of my own using FastAIV2.
Currently supports 5 Doodles (bird,cup,dog,face,fish).
Please do give it a try.
8 Likes