This post is dedicated to understand the difference between three of the most important concepts in creating your data for a Language Model:
- SEQUENCE LENGTH: it’s the length of the sequence you’re going to learn (on fastai it defaults to [total length]/[batch size]).
- BATCH SIZE: as usual is the number of “concurrent items” you’re going to feed into the model.
- BPTT: Back Propagation Through Time - eventually it’s the “depth” of your RNN (the number of iteration of your “for” loop in the forward pass).
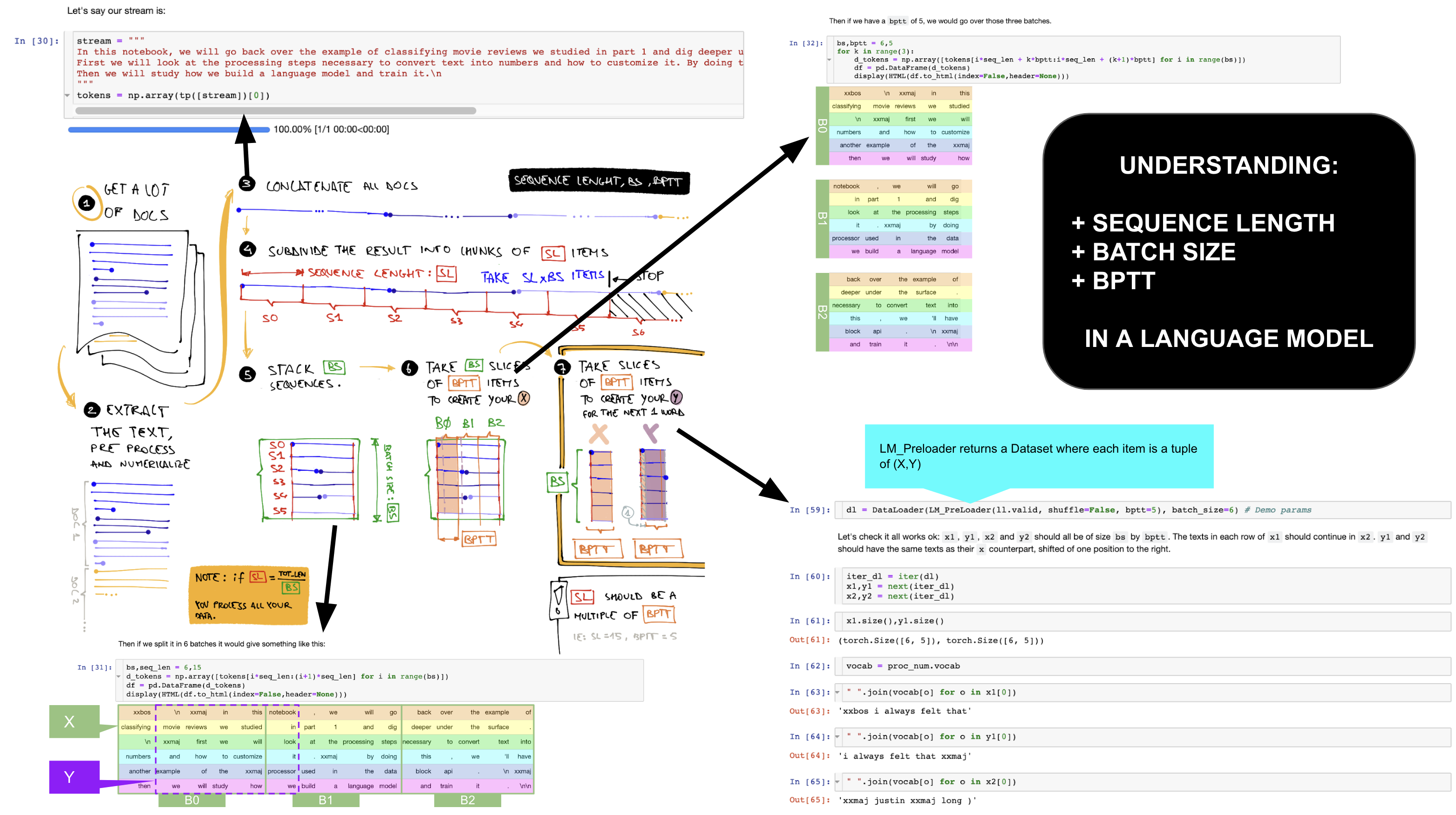
Visually follow the black numbers in the picture above.
I’ve slightly modified the original 12_text.ipynb notebook with this line:
dl = DataLoader(LM_PreLoader(ll.valid, shuffle=False, bptt=5), batch_size=6) # Demo params
To show the “path” of your data using the same parameters of the initial example (SL=15, BS=6, BPTT=5)
This was the original line, with a lot bigger BPTT and BS. Moreover the original code shuffle your data (in the sequence space) on each epoch (AFAIK it’s a kind of “data augmentation” that prevents the model to overfit…)
dl = DataLoader(LM_PreLoader(ll.valid, shuffle=True, bptt=70), batch_size=64)
STEPS:
- Get a lot of documents.
- Extract, process and numericalize your data.
- Concatenate all your numericalized documents in a stream of TOTAL LENGHT items.
- Chop your stream in lists of SEQUENCE LENGTH items (+).
- Stack your sequences into BATCH SIZE lines.
- Chop the groups again in chunks of BPTT items and you’ve got your X
- To get your Y, do the same thing as previous step, but one word shifted at right (note that X,Y has the same shape!)
VERY IMPORTANT Despite what happens with images or structured data (where for each Image you’ve a sample), your (X,Y) pairs will be A LOT MORE than your original documents!
IMPORTANT: if your SEQUENCE LENGTH isn’t a multiple of BPTT, you’ll pad the data inside your last batch.
NOTES:
(+) AFAIK usually you “randomize” a little bit the sequence length. IE: if SL=70 we can get sequences of 50…90.
SPECIAL THANKS
@stas for having reviewed and corrected the first version of the post.
@sgugger for sequence length formula: [sequnce lenght] = [total lenght]/[batch size]