fast.ai Course Forums
Lesson 12 (2019) discussion and wiki
Part 2 (2019)
ste
(Stefano Giomo)
April 23, 2019, 6:57pm
257
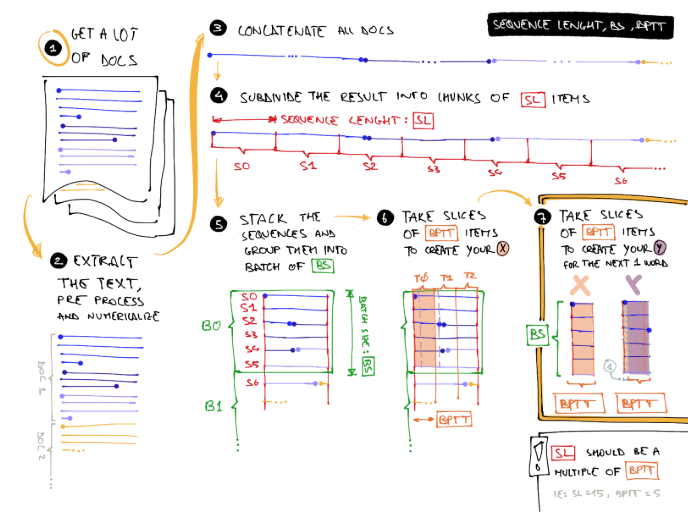
Sequence Length, Batch Size and BPTT
image
688×514 144 KB
9 Likes
show post in topic