I finely got into my instance, I found the location of the spm.vocab and spm. model. For me it was in /home/jupyter/.fastai/data/frwiki/docs/tmp
I tried twice and I am getting this error:
---------------------------------------------------------------------------
_RemoteTraceback Traceback (most recent call last)
_RemoteTraceback:
'''
Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/concurrent/futures/process.py", line 360, in _queue_management_worker
result_item = result_reader.recv()
File "/opt/anaconda3/lib/python3.7/multiprocessing/connection.py", line 250, in recv
buf = self._recv_bytes()
File "/opt/anaconda3/lib/python3.7/multiprocessing/connection.py", line 411, in _recv_bytes
return self._recv(size)
File "/opt/anaconda3/lib/python3.7/multiprocessing/connection.py", line 386, in _recv
buf.write(chunk)
MemoryError
'''
The above exception was the direct cause of the following exception:
BrokenProcessPool Traceback (most recent call last)
<ipython-input-43-58259e67b5f0> in <module>
1 data = (TextList.from_folder(dest, processor=[OpenFileProcessor(), SPProcessor()])
----> 2 .split_by_rand_pct(0.1, seed=42)
3 .label_for_lm()
4 .databunch(bs=bs, num_workers=-1))
5
/opt/anaconda3/lib/python3.7/site-packages/fastai/data_block.py in _inner(*args, **kwargs)
475 self.valid = fv(*args, from_item_lists=True, **kwargs)
476 self.__class__ = LabelLists
--> 477 self.process()
478 return self
479 return _inner
/opt/anaconda3/lib/python3.7/site-packages/fastai/data_block.py in process(self)
529 "Process the inner datasets."
530 xp,yp = self.get_processors()
--> 531 for ds,n in zip(self.lists, ['train','valid','test']): ds.process(xp, yp, name=n)
532 #progress_bar clear the outputs so in some case warnings issued during processing disappear.
533 for ds in self.lists:
/opt/anaconda3/lib/python3.7/site-packages/fastai/data_block.py in process(self, xp, yp, name)
709 p.warns = []
710 self.x,self.y = self.x[~filt],self.y[~filt]
--> 711 self.x.process(xp)
712 return self
713
/opt/anaconda3/lib/python3.7/site-packages/fastai/data_block.py in process(self, processor)
81 if processor is not None: self.processor = processor
82 self.processor = listify(self.processor)
---> 83 for p in self.processor: p.process(self)
84 return self
85
/opt/anaconda3/lib/python3.7/site-packages/fastai/text/data.py in process(self, ds)
468 else:
469 with ProcessPoolExecutor(self.n_cpus) as e:
--> 470 ds.items = np.array(sum(e.map(self._encode_batch, partition_by_cores(ds.items, self.n_cpus)), []))
471 ds.vocab = self.vocab
472
/opt/anaconda3/lib/python3.7/concurrent/futures/process.py in _chain_from_iterable_of_lists(iterable)
474 careful not to keep references to yielded objects.
475 """
--> 476 for element in iterable:
477 element.reverse()
478 while element:
/opt/anaconda3/lib/python3.7/concurrent/futures/_base.py in result_iterator()
584 # Careful not to keep a reference to the popped future
585 if timeout is None:
--> 586 yield fs.pop().result()
587 else:
588 yield fs.pop().result(end_time - time.monotonic())
/opt/anaconda3/lib/python3.7/concurrent/futures/_base.py in result(self, timeout)
430 raise CancelledError()
431 elif self._state == FINISHED:
--> 432 return self.__get_result()
433 else:
434 raise TimeoutError()
/opt/anaconda3/lib/python3.7/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
--> 384 raise self._exception
385 else:
386 return self._result
BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.
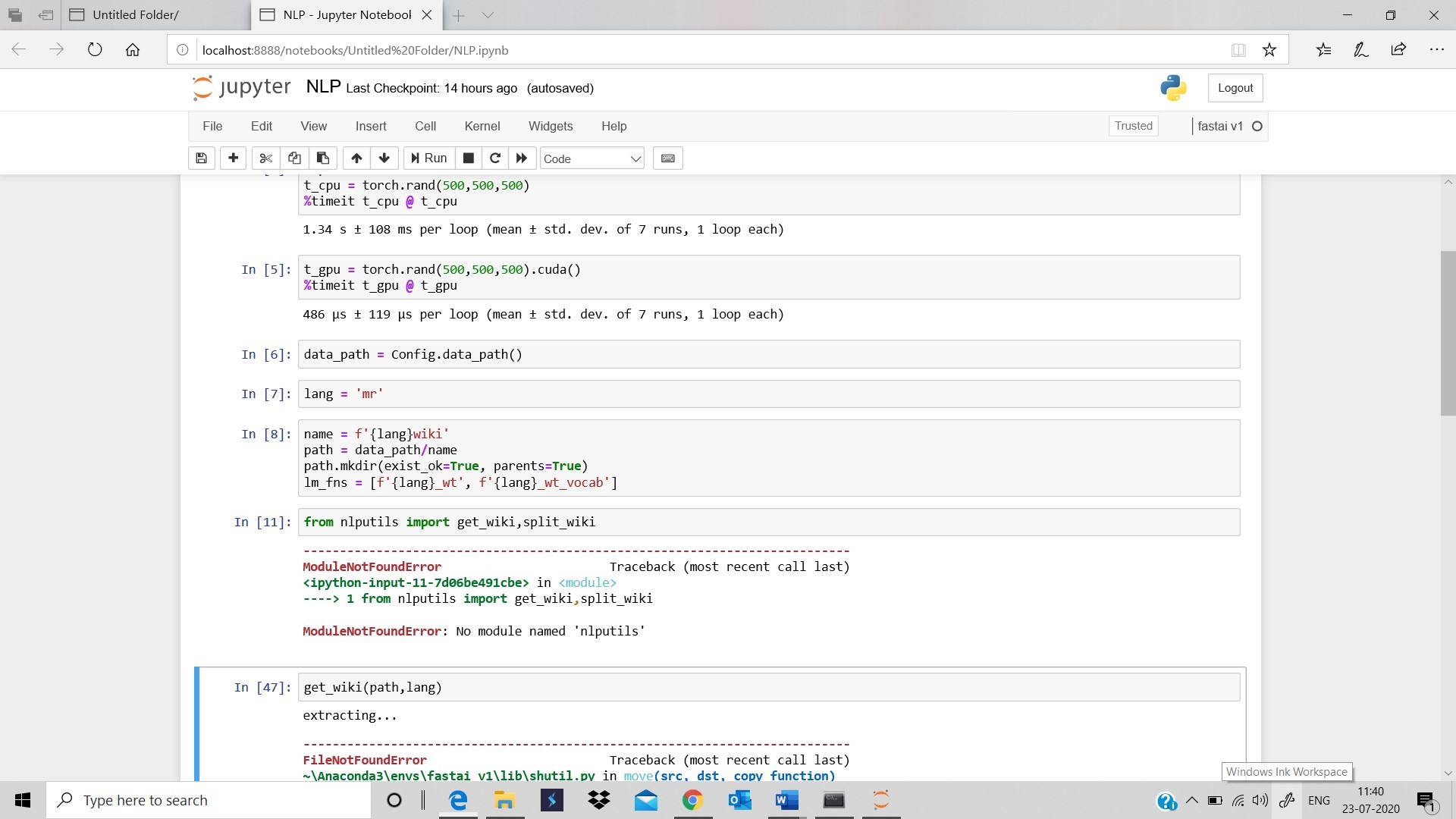
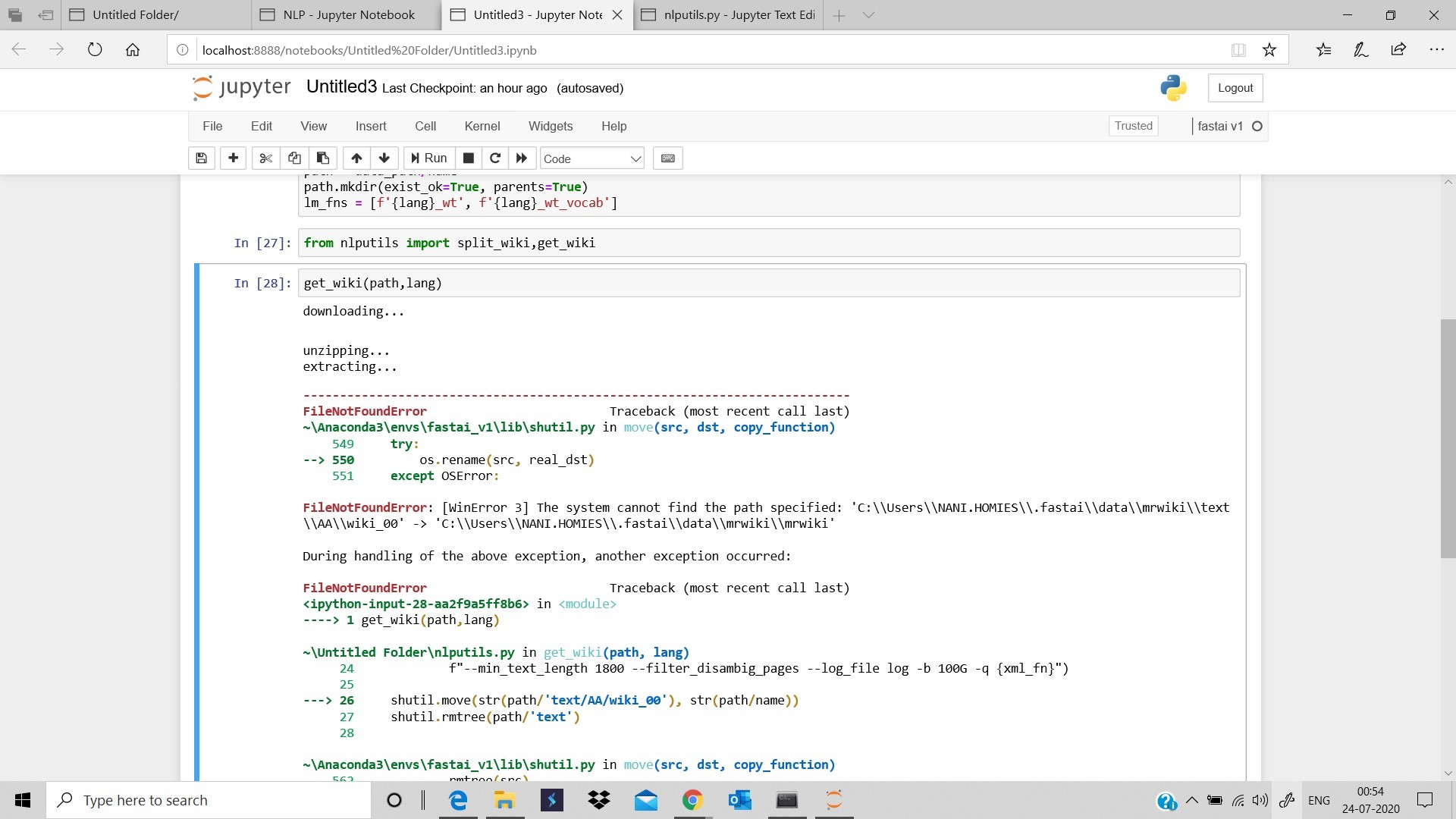
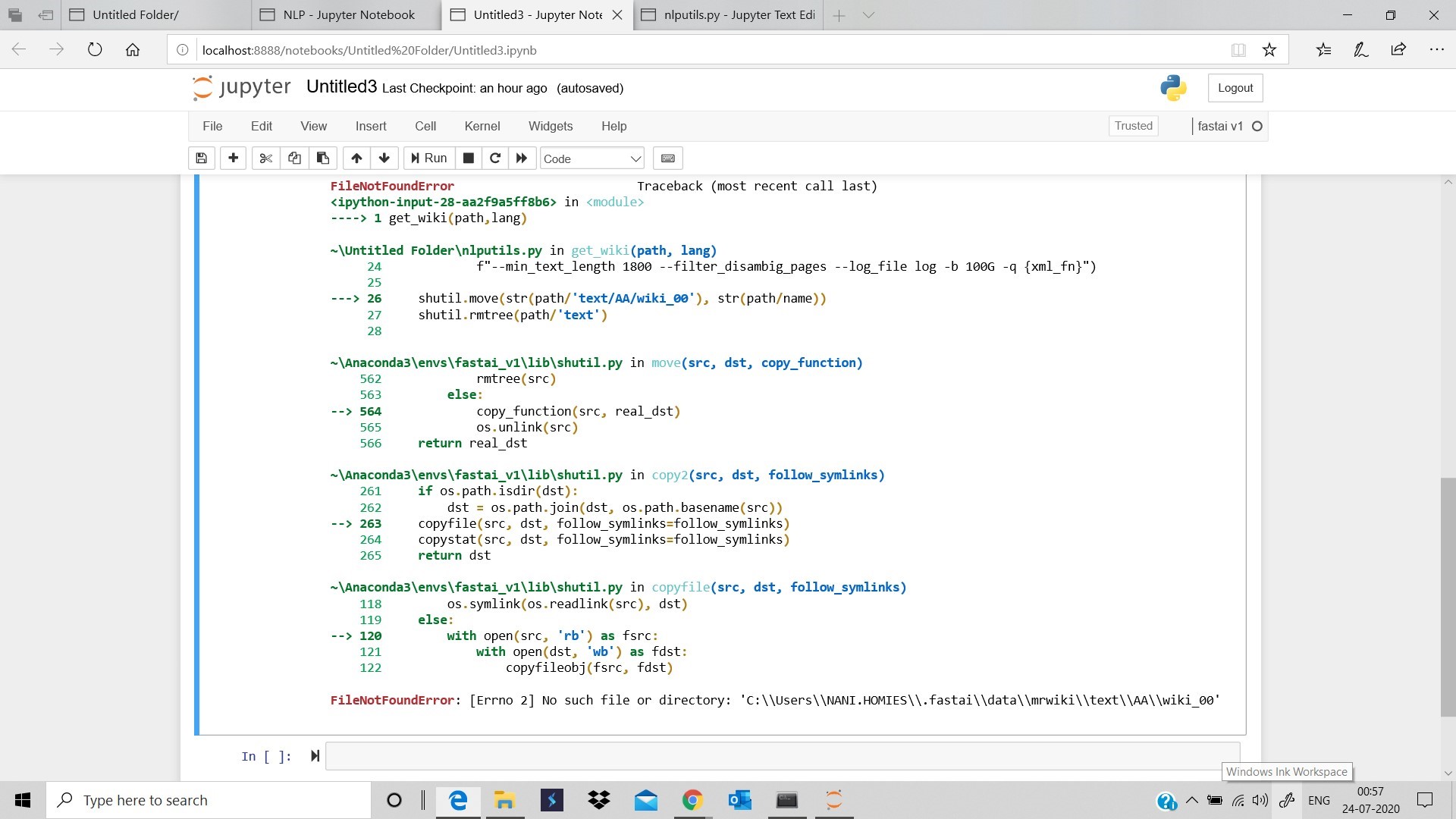
I am thinking the fr wiki is too big for my instance, but am not sure. at this point in setting up data, my cpu goes up to 100% then dies. Do you know how I would fix this? I can give you spm.model and vocab, but I don’t know if that will help you.
Jeromy stated to limit the corpus size to 100 million tokens [Language Model Zoo 🦍] but I need to figure out how to do that.
 :smiley
:smiley