For the past few weeks I have been doing some reading on active learning. I thought it would be a good idea to open a thread about this topic to discuss potential implementations in fastai-v2. Mainly to see if this would be something worth pursuing and investing time in.
So far I haven’t done any actual experimentation to test out some of the popular techniques but I intend to do so in the coming weeks. I also think that there might be many people in the forums that have a decent amount of hands-on and practical experience. So please share your thoughts and give feedback
Mainly the goal would be to have utilities/helpers/pipelines that would enable to do the most with the least number of labelled data. Here are some example cases that might benefit from such goal:
Medical applications where labelling costs are too high
Sensory applications where signal to noise ratios are very low
Self driving cars that collect real time data - plethora of data to label, which ones to label?
Production models that interact with users and get input constantly - domain adaptation?
Many more…
So, this topic shouldn’t necessarily be narrowed down to only active learning but the term can be an umbrella for many ideas such as pseudo labelling (works pretty well in many kaggle comps), uncertainty estimation, semi-supervised learning, and so on.
A recent paper with title “Active Learning for Deep Detection Neural Networks” also includes codes. May be same words with different uses. link to paper
I started conducting a very preliminary work similar to this useful paper. In most active learning frameworks we try to come up with an uncertainty measure - there are many different algorithms you can use for this here is a good survey paper.
Once uncertainties are measured then user can decide whether to annotate, psuedo-label or ignore unlabeled samples. But there is one important caveat:
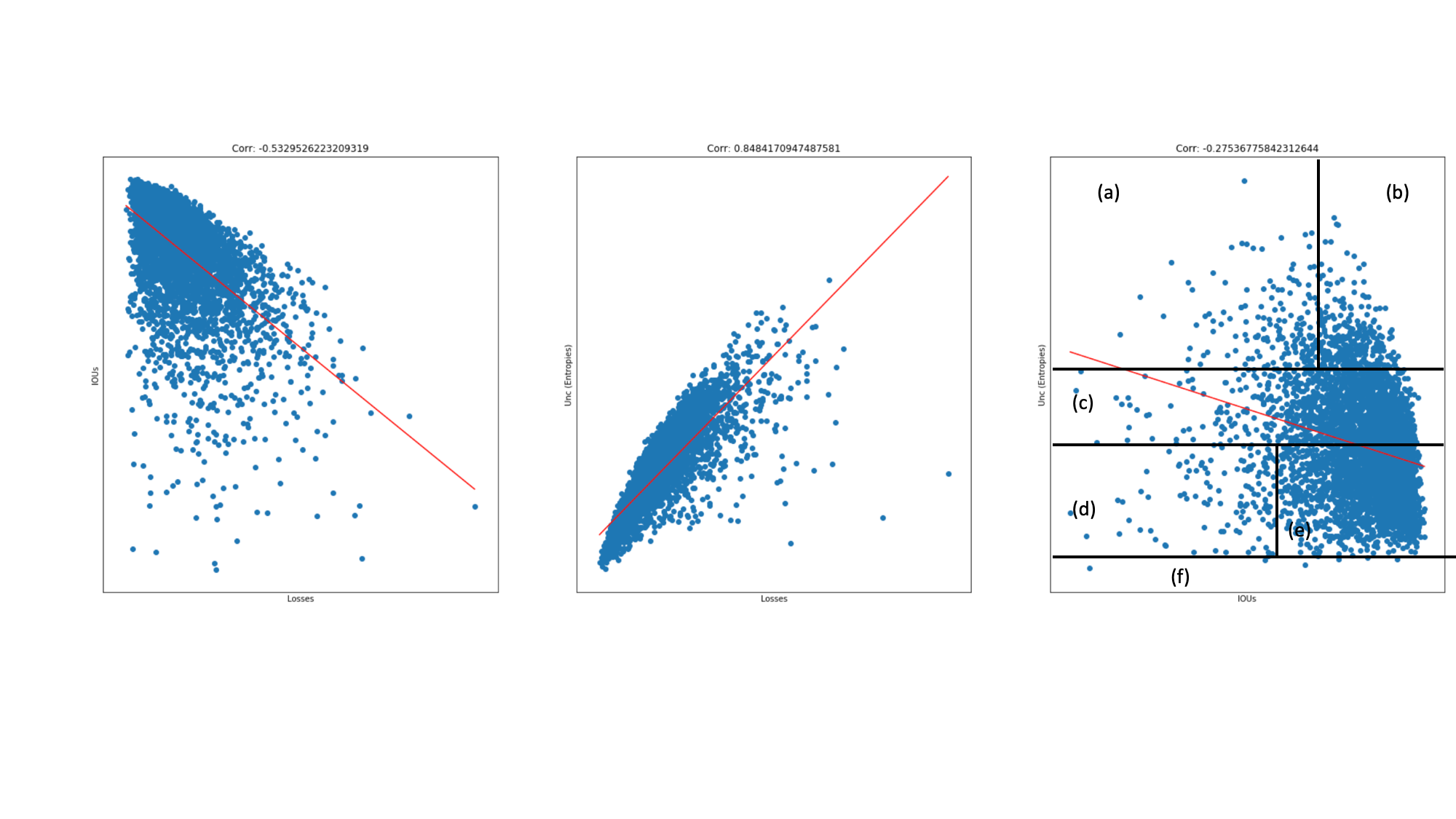
Is uncertainty measure and prediction performance correlated? (In a perfect scenario we would see a correlation of -1)
For testing this hypothesis I trained a binary segmentation model for few epochs and used entropy based uncertainty.
Train 15 epochs (1.5k) - Plotting samples out of training (5k)
a) High uncertainty, choose to annotate and will be most useful for model performance,
b) High uncertainty, choose to annotate and will be not be as useful as (a) since samples already have high IOU.
c) Medium level uncertainty, not so certain how to use these samples, most likely ignore.
d) Low uncertainty, choose to psuedo label but it may degrade model performance by feeding systematic error.
e) Low uncertainty, choose to psuedo label and will be most likely helpful in improving model performance.
f) Low uncertainty and low IOU. May these be samples out of training distribution? See this blog
Maybe diversity sampling can be made to collect similar images.
This is a very early stage work to get an initial understanding. Entropy as an uncertainty measure is probably not the best one, especially compared with Dropout / Ensemble / Bayesian Network based uncertainties.
Next: Investigate Dropout and Ensemble uncertainty methods.
One should listen some videos of Naftali Tishby from youtube and his papers. Hard to understand (at some point I have no clue what he is talking about ) , but really he is one of few people who discusses theory of DL from information theory point of view which forms the bases for active learning. video, some codes, and blog 1, blog 2
Yes almost same and there are couple of more in the same direction. The one I send was less technical, explaining more conceptual and more complete story for an easy to start.
Here is some information about an interesting library that might be useful in building something similar in fastai v2:
Bayesian Active Learning (Baal) by Element AI
Element AI (an artificial intelligence company co-founded by Yoshua Bengio and based in Montreal, Canada) has recently open sourced BaaL, an active learning library written in pytorch. BaaL supports the following methods to perform active learning.
Above is a fantastic blog post about Active Learning in general and a comparison between the BALD BatchBALD methods more specifically. The post is written by the same researchers (from University of Oxford) who published the BatchBALD article at NeurIPS 2019.
In Active Learning we only ask experts to label the most informative data points instead of labeling the whole dataset upfront.
Both BALD and BatchBALD are two techniques (called acquisition functions) that measure how informative a data point is and help us to decide if a data point should be prioritized to be labeled by an expert, and consequently be part of the next data batch to be trained. The final goal is that our model reach a good accuracy with a small number of labeled data points.
This is an illustration (from the article) that highlights the difference between BALD and BatchBALD
Figure 3:Idealised acquisitions of BALD and BatchBALD . If a dataset were to contain many (near) replicas for each data point, then BALD would select all replicas of a single informative data point at the expense of other informative data points, wasting data efficiency.
As illustrated, our model will learn more efficiently (more diverse data that share some similarities) if we chose the batch suggested by the BatchBALD acquisition function as opposed to the BALD one (more repetitive data).
For those who would like to deep dive in the BatchBALD method here are :
Andreas Kirsch, one of the author of BatchBALD paper (check out this little summary post here above), lately released a BatchBALD package built using nbdev: Repo, Docs
I think this would be the most straightforward to adapt for fastai2. They recently added BatchBALD as well.
One really interesting methodology in their baal_prod_cls notebook is how they use already labelled training data to simulate human labelling.
Say you have 1,000 labelled samples, 200 test samples, and 10,000 unlabelled samples. As per their approach, first train the model with 100 samples only, then simulate active learning labelling for the next 900 samples before bringing in the actual human in the loop.
It seems to me like this would be a more robust way (although longer) to train the model than to just train it on the 1,000 labelled images and then start active learning.
Could you share the code you used to test this hypothesis? I was reading up on ‘Building Machine Learning Powered Applications’ where “Uncertainty sampling” was mentioned.
This approach seems to be useful in identifying samples near decision boundary, and adding such similar examples to the training set.


 ) , but really he is one of few people who discusses theory of DL from information theory point of view which forms the bases for active learning.
) , but really he is one of few people who discusses theory of DL from information theory point of view which forms the bases for active learning. 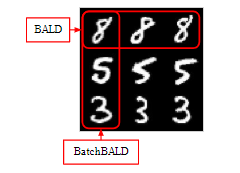
 :
: