Human in the Loop: Deep Learning without Wasteful Labelling
Above is a fantastic blog post about Active Learning in general and a comparison between the BALD BatchBALD methods more specifically. The post is written by the same researchers (from University of Oxford) who published the BatchBALD article at NeurIPS 2019.
In Active Learning we only ask experts to label the most informative data points instead of labeling the whole dataset upfront.
Both BALD and BatchBALD are two techniques (called acquisition functions) that measure how informative a data point is and help us to decide if a data point should be prioritized to be labeled by an expert, and consequently be part of the next data batch to be trained. The final goal is that our model reach a good accuracy with a small number of labeled data points.
This is an illustration (from the article) that highlights the difference between BALD and BatchBALD
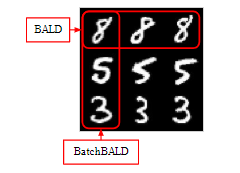
Figure 3: Idealised acquisitions of BALD and BatchBALD . If a dataset were to contain many (near) replicas for each data point, then BALD would select all replicas of a single informative data point at the expense of other informative data points, wasting data efficiency.
As illustrated, our model will learn more efficiently (more diverse data that share some similarities) if we chose the batch suggested by the BatchBALD acquisition function as opposed to the BALD one (more repetitive data).
For those who would like to deep dive in the BatchBALD method here are :
Paper : BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning
Repo: