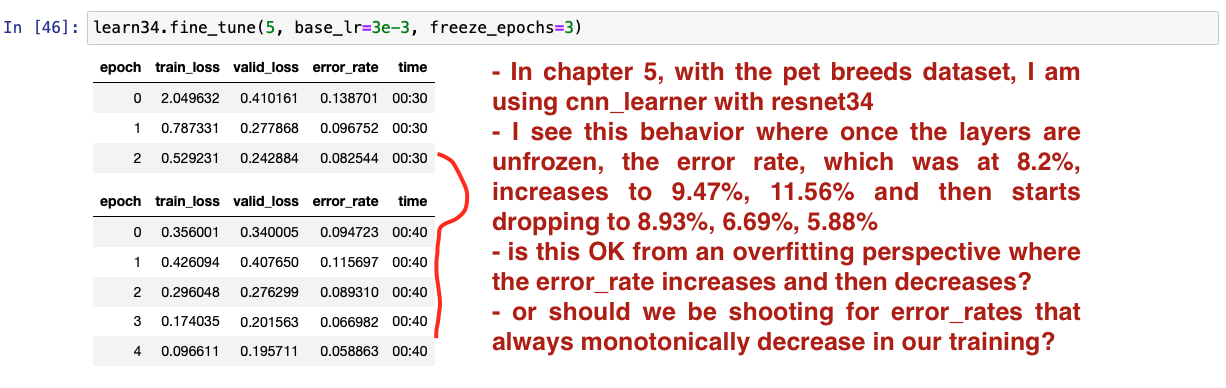
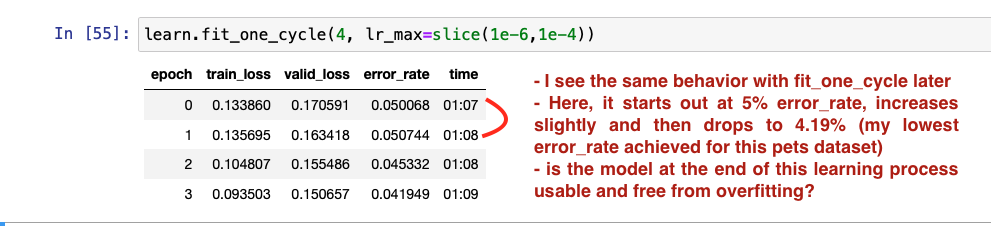
Request for input on the error_rate behavior where it increases and then starts decreasing.
Hi Kishore.
I’m not really sure if this explains your issue completely, but here it goes:
for learn.fine_tune() and learn.fit_one_cycle(), fast.ai uses a cyclical learning rate. If you run learn.recorder.plot_sched() you’ll see something like this:
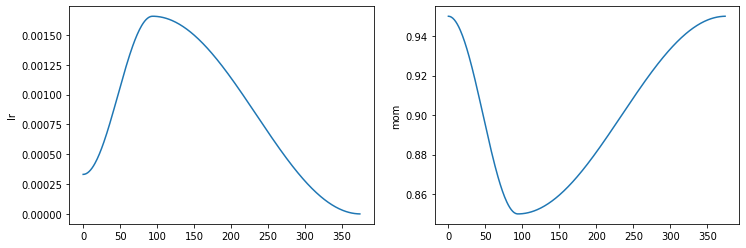
Intuitively, I’d say that what you’re seeing there may just be that the learning rate gets too high and you overshoot the loss minimum a bit, and then you start getting closer once your learning rate starts decreasing again.
Cheers,
K.
Hi Kristian, thanks for taking the time to answer. Your explanation makes sense and I will look up and understand how fit_one_cycle works.
But my question or issue is not constrained to me. In his example in the lesson on unfreezing learning rates, and using discriminative learning rates, @Jeremy also shows an example where the error_rate increases and then drops. See screenshot of that example. My question is more general. All I am asking is if this behavior where the error_rate increases and then falls is OK as long as it falls later? And if it starts rising again and stays rising or constant, is that when we are overfitting?
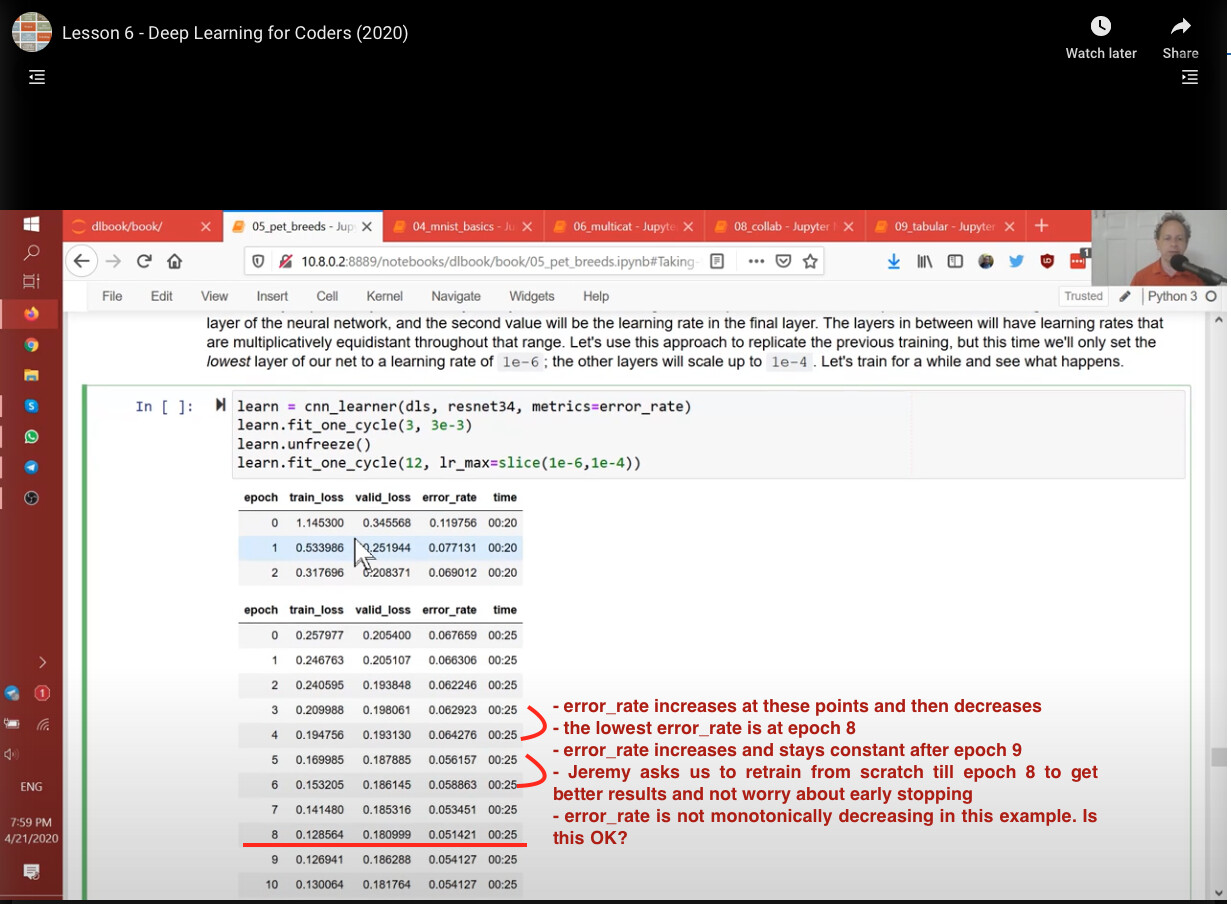
The error rate rising could be overfitting or it could be the weights moving to a different part of the loss surface that is hopefully flatter and more generalizable to new input data. That movement to a different part of the loss space is brought about by one-cycle learning where the learning rate increases enough such that it can jump out of any narrow pits of the loss surface and find a more stable landing spot with a gentle path back down the loss surface. You’ll know it’s overfitting when the loss doesn’t go back down even the learning rate is decreasing.
3 Likes
@Patrick, thanks for that beautiful explanation. I enjoyed visualizing and understanding what you said. This being said, my basic question still remains unanswered.
Is the model at the end of the training run in the image below OK to use from an overfitting perspective?
https://forums.fast.ai/uploads/default/original/3X/4/e/4e5db111ccb47e2aa07653228d72a32c274e9a15.png
Hi Kishore!
I’d say the model is OK, you should keep an eye on it once the training loss gets lower than the validation loss, your model can still improve, but usually it starts around that point.
One of the best ways of spotting overfitting is to check the validation loss. If your validation loss starts to consistently diverge from your training loss (training loss keeps going down, but validation loss starts going up), then you know the model is overfitting. Also, you should base this in more than one observation, as the loss usually fluctuates a bit.
Bottom line, usually the loss tells you way more about what’s happening than the error rate, which saturates more easily.
Hi Kristian, thanks again for your time and response.
Blockquote
Bottom line, usually the loss tells you way more about what’s happening than the error rate, which saturates more easily.
@Jeremy has been specific about monitoring the metric (error_rate) and not the losses as a measure of overfitting. There are forum threads where he is quoted on this. You still think paying attention to the loss rates is important as a means to detect overfitting? Here is @Jeremy’s related tweet/ x.com
@lukemshepherd, thank you and I will use the plot_loss function. But as I mentioned to @kBodolai, @Jeremy has been specific about paying attention to the metric and not the losses when it comes to monitoring overfitting.
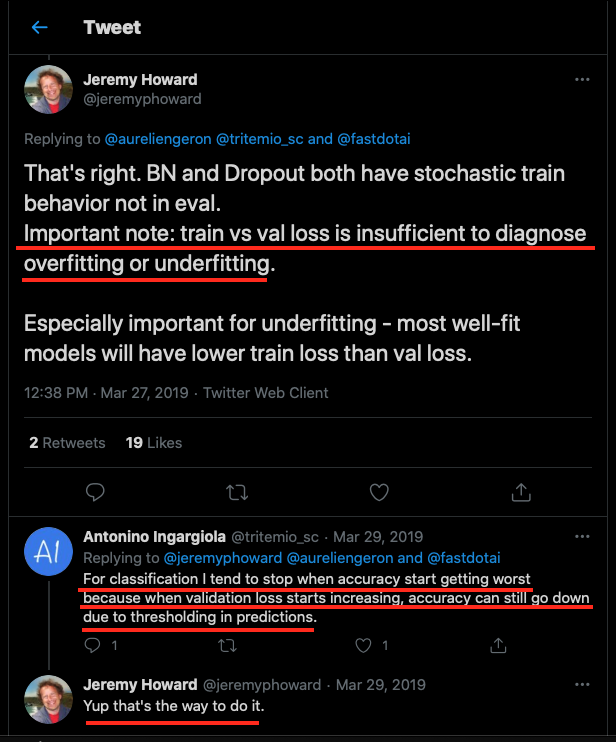
Also, thanks for pointing me to SaveModelCallback(). Although, in the textbook, @Jeremy says not to use the early stopping approach and retrain from scratch instead to the point where the error_rate starts increasing reliably. I appreciate the pointer nonetheless.
I stand corrected,
I tried to oversimplify the issue too much. Usually I monitor all of these things together, sorry for the vague/incorrect answer, and thanks for pointing that out!
No worries and thank you @kBodolai. It is awesome to talk/communicate with fellow DL practitioners. I am still early in my journey but loving it.
On an unrelated note, just modified MNIST_SAMPLE so that I can use softmax as the loss function instead of mnist_loss and I get what’s going on. Yay! 
1 Like
Hi,
Back in the earlier days (i.e. 2017) validation loss increasing was deemed an indicator of overfitting (Lesson 2 discussion - beginner - #125 by jeremy, Lesson 2: further discussion ✅ - #37 by krash, Lesson 2: further discussion ✅ - #28 by marcmuc) as I was using that criteria as well for a while.
There were some confusion regarding the definition of overfit Lesson 8 (2019) discussion & wiki - #464 by miwojc but it seems it was a misunderstanding - maybe Jeremy’s use of “validation error” in the lecture was heard incorrectly as “validation loss.”
But, I think it is clear now (and Jeremy has been teaching for a while, Share your work here ✅ - #190 by jeremy) that the indicator of overfitting is decreasing validation accuracy.
Chapter 1 in the the book repeats it several times (fastbook/01_intro.ipynb at master · fastai/fastbook · GitHub)
However, you should only use those methods after you have confirmed that overfitting is actually occurring (i.e., you have actually observed the validation accuracy getting worse during training).
and right under that, he says …
If you train for too long, with not enough data, you will see the accuracy of your model start to get worse; this is called overfitting .
And - another vote for accuracy
and are more prone to overfitting (i.e. you can’t train them for as many epochs before the accuracy on the validation set starts getting worse).
@meanpenguin, thank you.