In lesson 2, Jeremy explains that if training loss is lower than the validation loss, it does not necessarily mean overfitting as long as val_accuracy increases (or error rate decreases).
So does that mean I can train my model for as long as accuracy is increasing?
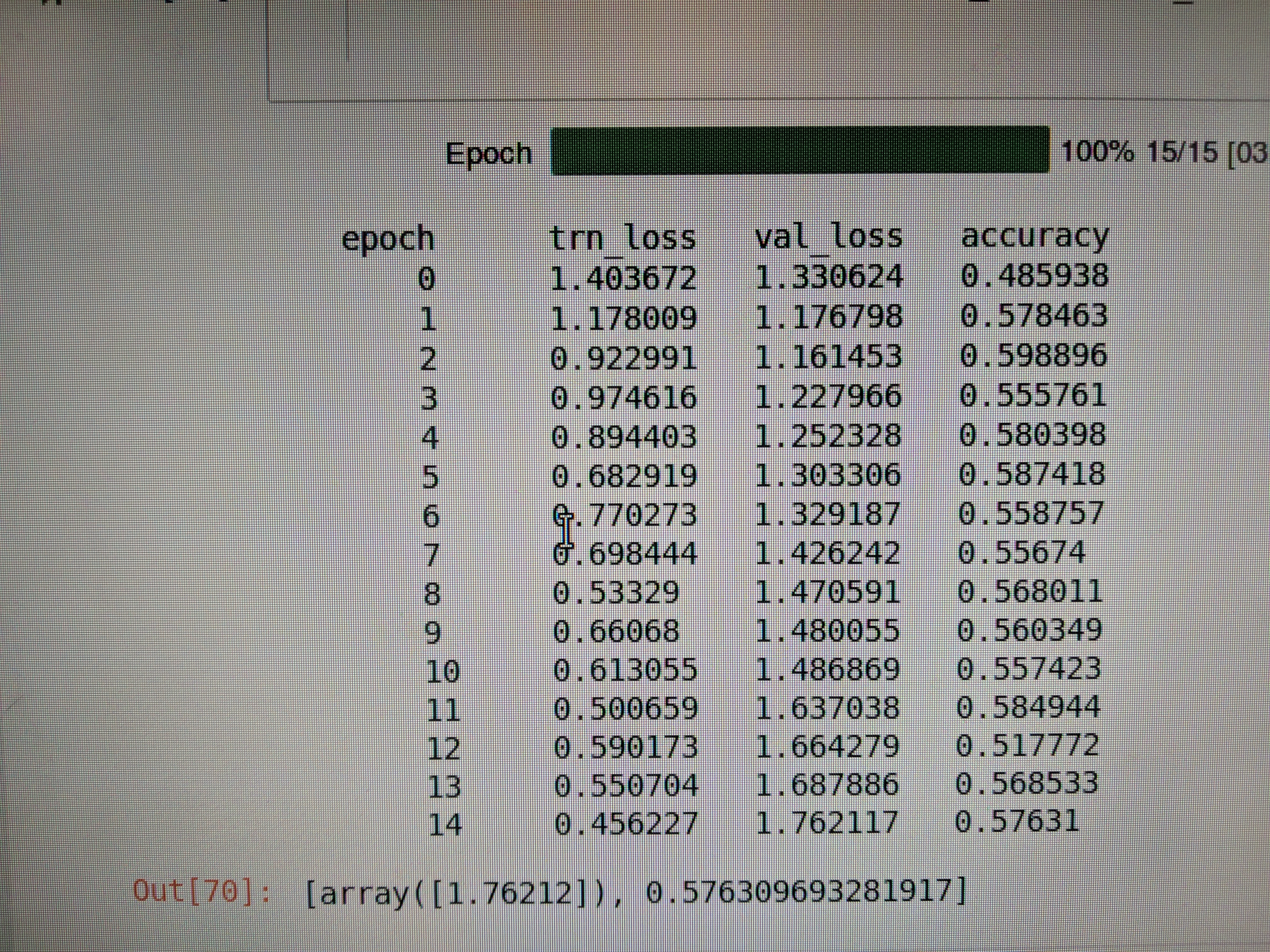
When training the model, my accuracy is increasing, training loss is way lower than validation loss, but validation loss is increasing as well. What does this signify? Am I overfitting? Or am I ok as long as accuracy is increasing?