If anyone is interested, I’ve got a little (important) project request: implement “cyclical momentum” from the recent Leslie Smith paper. https://arxiv.org/abs/1803.09820
The way I think it should work is that the use_clr tuple should be expanded to optionally be a 4-tuple instead of a 2-tuple. If it’s a 4-tuple, the first two items are the same as currently, and the last 2 items are (max momentum, min momentum). In a cycle, the momentum would start at the max, and it would linearly decrease down to the minimum with the same schedule that LR is increasing, and then it would linearly increase back up to the maximum with the same schedule that LR then decreases. i.e. it would look just the same as the recommended approach in the paper.
Ideally, if the user is using cyclical momentum, then plot_lr would plot a 2nd line, showing the momentum as well as the LR.
If anyone starts on this, please post updates here so that we can coordinate progress. I’m thinking this shouldn’t be more than a few hours work for someone who’s already familiar with the callback system in fastai, or even faster for someone who’s already familiar with the existing SGDR or CLR code.
(If one of you does do this, you may also want to do some experiments to see if it speeds up training on a couple of different datasets and then write a little blog post about it, since I don’t think anyone has implemented this paper yet - I’m sure a lot of folks would be interested.)
Great! Feel free to PR now so we can start playing with it - but then I think see if you can replicate at least one of Smith’s training results from the paper where he uses it.
I just did.
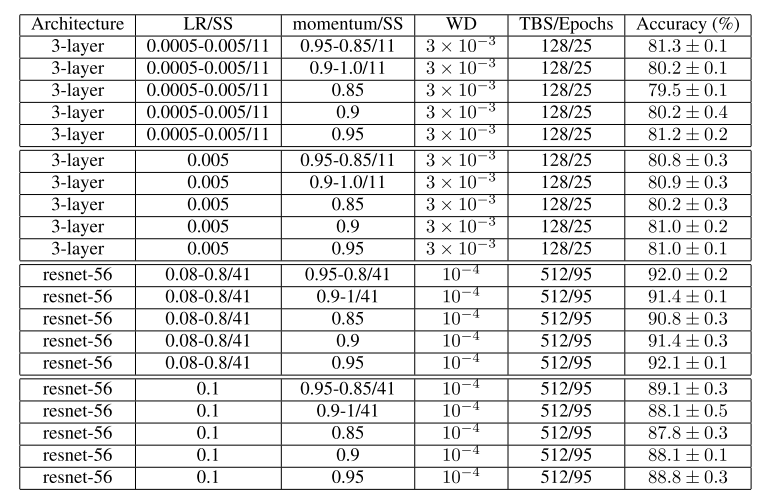
I’ll try to replicate Leslie’s training results on cifar10 with resnet56 since he didn’t describe his shallow network. It seems he uses the cyclical learning rate a bit differently than us, making a longer period where the learning rate rises: in this table, it seems he uses 11 epochs for the cycle going up then I guess 25-11=14 epochs for the cycle going down.
Yeah when he 1st described it to me over email it was basically just what’s now use_clr. But the paper suggests doing a standard triangular cycle and then doing just the latter half of a cycle going down another 100x multiple on the LR. However I think they’re basically close enough to the same thing - when you test on CIFAR-10 we’ll find out though!
I didn’t manage to reproduce the exact results of 92% accuracy but came close.
My first experiment was to use use_clr with lr=0.8 and the parameters (10,95/41) (to 41 epochs on the ascending step then 54 to descend) and found 91.175%
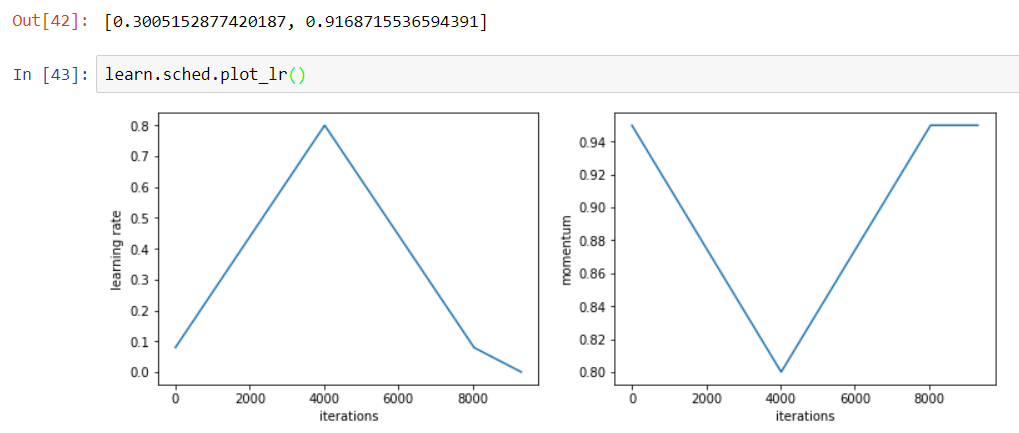
The second one was to try to replicate exactly what Leslie is doing, so 41 epochs ascending, 41 epochs descending and the remaining 13 to drop the lr by another 100 (maybe I should have picked another number, I’ll try and see if it gets better) and I found 91.69% accuracy. Here are my pictures of lr/momentum over iterations.
First interesting fact: trying to increase the learning rate too quickly is punished by the error going up to nan. If we try to go with just a half-cycle of 10 instead of 41, it diverges.
At 20, it manages to learn but the final accuracy isn’t as good (90%, at 50 epochs).
To complete this post, while keeping the same way of doing a cycle as Leslie (like in the figure above)
I got the 92% accuracy with cyclical LR (0.08-0.8) and cyclical momentum (0.95-0.85)
With just cyclical LR and a constant moment of 0.9, I got 91.7% (the upper margin of error according to the tab)
89% of accuracy for a constant LR (0.1) and constant momentum (0.9) (again, more than in the tab)
I also tried Adam with the same way of doing CLR and it didn’t like it all (even if I adapted the LR)! The accuracy dropped at 20%.
What was the difference between the 91.69% and the 92% runs?
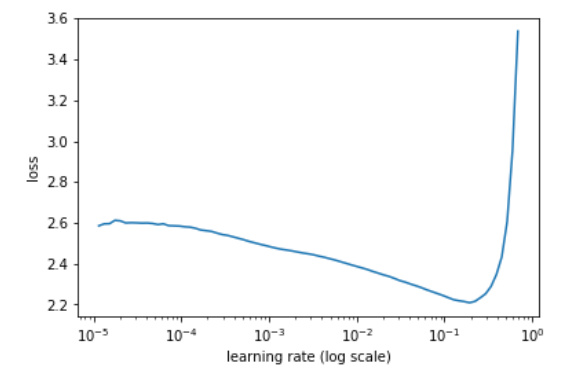
Also, it might be interesting to show a plot of lr_find(start=0.1, end=2, linear=True) with momentum 0.9. That way we can see how the optimal LR looks based on the LR finder, which might be helpful for setting LR in the future.
Maybe try with beta2=0.99 or 0.9? (You’ll need to use LR finder to figure out an LR, since it’s very different for Adam). Maybe also try setting use_wd_sched=True in learn.fit?
No difference in my code. I just stopped after the full cycle of 82 epochs and saved the model because I wanted to play around with various ways to decrease the last 13 epochs in the last part. FYI, going linearly from the initial value to 1/100th of it seems to work best. Regular cosine annealing as done by the fastai library is close behind.
I’m thinking the difference is just in the normal STD for this training.
Very true, since I did that before anything else and saw that 0.8 is above the value of the minimum:
Trying different values is what I plan to do tomorrow, to see if the real minimum for instance makes a better max LR.
I’ll try that tomorrow as well. Maybe the beta1 needs to move the same way momentum does in the cycle since it’s the equivalent of momentum. I had used a different LR given by the LR finder.
In that case we may want to think about changing the meaning of use_clr to work this way. Do you have a sense of what % of epochs should be used for that last section that goes to the really low LRs?
That’s really what seems to be key (and he repeats it several times in the first half of his paper) which is also why he uses a ‘real’ triangle for the cycle.
I’ll focus on the lr_plots tomorrow as well because this seems also very important to tune all the parameters. We may have to change a bit the LR Finder because it seems he doesn’t really do a test on one epoch but rather on a given number of iterations.
Not really. Leslie seems to do anything between 4 and 15% on his various tests.
To let us experiment as we want without breaking the existing use_clr, I’ve made a pull request with another argument use_clr_beta. It’s a tuple with either two elements (no cyclical momentum) or four, which are:
(div,pct,max_mom,min_mom)
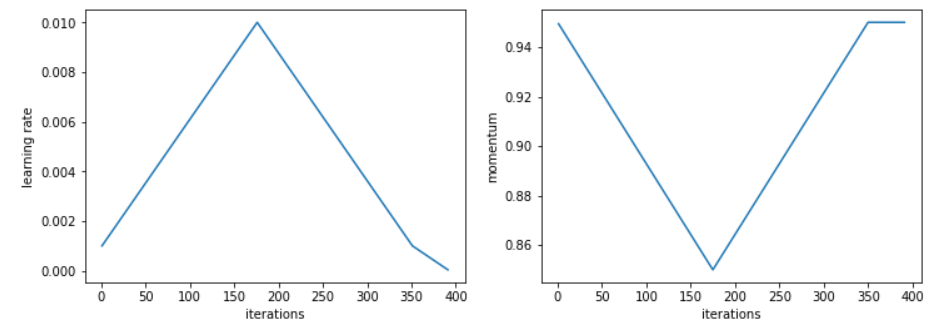
use_clr_beta = (10,10,0.95,0.85) with a learning rate of 0.01 will give a schedule like this:
div is the amount the LR is divided to give us the minimum LR, pct the percentage of our number of iterations devoted to the last part where we anneal the LR (I deliberately left it like this and not 0.1 to break less things in the existing use of use_clr where this value is often around 10).
Now I’ll work on a LR_finder_beta that gives us the nice plots Leslie uses to tune his other hyperparameters.
On parallel, by reducing the maximum learning rate to the minimum on our curve (0.3), I’ve reached an accuracy of 92.7%.
This makes me thinks I may not be using the same resnet56 as Leslie. I must admit I struggled to find a description of the specific architecture for cifar10. For now I was using the ameliorated version with Batchnorm after the sum of the input of the block with the outputs of the second convolutional layer, but that may not be the one he used.
Great! His RN50 does seem less than great, since his precision numbers in the paper are quite a big less than they should be for the baseline. Perhaps he’s not using data augmentation. Hard to know exactly.